The result of the seqclr model. #3
Description
Thanks for sharing the codes.
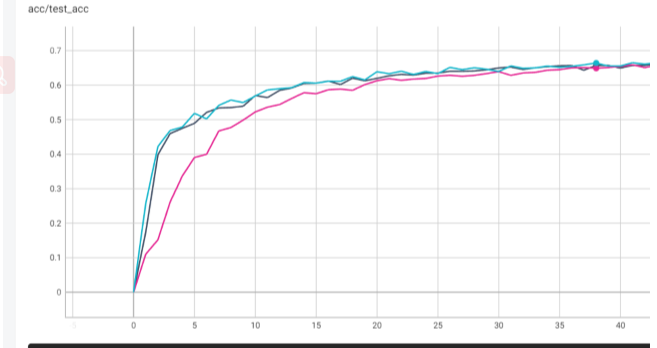
As for the result, I find the gap between the pre-trained model and the un-pre-trained model becomes similar as the training epoch increase.
Do you have the same result? Can you give me some advice?