diff --git a/.coveragerc b/.coveragerc
deleted file mode 100644
index 3269103..0000000
--- a/.coveragerc
+++ /dev/null
@@ -1,22 +0,0 @@
-[run]
-omit = tests/*
-dynamic_context = test_function
-
-[report]
-# Regexes for lines to exclude from consideration
-exclude_lines =
- # Have to re-enable the standard pragma
- pragma: no cover
-
- # Don't complain about missing debug-only code
- def __repr__
-
- # Don't complain if tests don't hit defensive assertion code
- raise AssertionError
- raise NotImplementedError
-
- # Don't complain if non-runnable code isn't run:
- if __name__ == .__main__.:
-
- # Don't complain if ellipsis never gets executed
- ^[ ]*\.\.\.$
diff --git a/.github/workflows/build_wheels.yml b/.github/workflows/build_wheels.yml
index da6592a..3d14ae4 100644
--- a/.github/workflows/build_wheels.yml
+++ b/.github/workflows/build_wheels.yml
@@ -15,7 +15,7 @@ jobs:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
- python-version: '3.13'
+ python-version: '3.14'
- name: Build wheels
uses: PyO3/maturin-action@v1
with:
@@ -37,7 +37,7 @@ jobs:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
- python-version: '3.13'
+ python-version: '3.14'
architecture: ${{ matrix.target }}
- name: Build wheels
uses: PyO3/maturin-action@v1
@@ -59,7 +59,7 @@ jobs:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
- python-version: '3.13'
+ python-version: '3.14'
- name: Build wheels
uses: PyO3/maturin-action@v1
with:
diff --git a/.github/workflows/tests_and_lint.yml b/.github/workflows/tests_and_lint.yml
index 64bca5f..a4332f3 100644
--- a/.github/workflows/tests_and_lint.yml
+++ b/.github/workflows/tests_and_lint.yml
@@ -14,13 +14,7 @@ jobs:
runs-on: ubuntu-latest
strategy:
matrix:
- python-version: [3.13]
- lint-flags:
- - "--run-only-fast-linters"
- - "--run-only-pylint"
- - "--run-only-mypy"
- - "--run-only-bandit"
- - "--run-only-cargo-clippy"
+ python-version: [3.14]
steps:
- uses: actions/checkout@v4
- name: Set up Python ${{ matrix.python-version }}
@@ -38,7 +32,7 @@ jobs:
runs-on: ubuntu-latest
strategy:
matrix:
- python-version: ["3.9", "3.10", "3.11", "3.12", "3.13"]
+ python-version: ["3.10", "3.11", "3.12", "3.13", "3.14"]
steps:
- uses: actions/checkout@v4
- name: Set up Python ${{ matrix.python-version }}
@@ -61,7 +55,7 @@ jobs:
runs-on: ubuntu-latest
strategy:
matrix:
- python-version: ["3.9", "3.10", "3.11", "3.12", "3.13"]
+ python-version: ["3.10", "3.11", "3.12", "3.13", "3.14"]
steps:
- uses: actions/checkout@v4
- name: Set up Python ${{ matrix.python-version }}
diff --git a/.gitignore b/.gitignore
index 915718d..75a362e 100644
--- a/.gitignore
+++ b/.gitignore
@@ -97,3 +97,6 @@ wheels/
# These are backup files generated by rustfmt
**/*.rs.bk
+
+# UV
+uv.lock
diff --git a/.pydocstyle b/.pydocstyle
deleted file mode 100644
index 00d3440..0000000
--- a/.pydocstyle
+++ /dev/null
@@ -1,3 +0,0 @@
-[pydocstyle]
-ignore = D100,D101,D104,D202,D203,D213,D406,D407,D408,D409,D413
-match = (?!test_).*\.py
diff --git a/.pydocstyle_test b/.pydocstyle_test
deleted file mode 100644
index af3a431..0000000
--- a/.pydocstyle_test
+++ /dev/null
@@ -1,3 +0,0 @@
-[pydocstyle]
-ignore = D100,D101,D102,D104,D202,D203,D213,D406,D407,D408,D409,D413
-match = test_.*\.py
diff --git a/.pylintrc b/.pylintrc
deleted file mode 100644
index 708856e..0000000
--- a/.pylintrc
+++ /dev/null
@@ -1,656 +0,0 @@
-[MASTER]
-
-# A comma-separated list of package or module names from where C extensions may
-# be loaded. Extensions are loading into the active Python interpreter and may
-# run arbitrary code
-extension-pkg-whitelist=
-
-# Add files or directories to the ignore list. They should be base names, not
-# paths.
-ignore=CVS,venv
-
-# Add files or directories matching the regex patterns to the ignore list. The
-# regex matches against base names, not paths.
-ignore-patterns=
-
-# Python code to execute, usually for sys.path manipulation such as
-# pygtk.require().
-#init-hook=
-
-# Use multiple processes to speed up Pylint.
-jobs=1
-
-# List of plugins (as comma separated values of python modules names) to load,
-# usually to register additional checkers.
-load-plugins=pylint.extensions.docparams,pylint.extensions.docstyle,pylint.extensions.overlapping_exceptions,pylint.extensions.redefined_variable_type
-
-# Pickle collected data for later comparisons.
-persistent=no
-
-# Specify a configuration file.
-#rcfile=
-
-# Allow loading of arbitrary C extensions. Extensions are imported into the
-# active Python interpreter and may run arbitrary code.
-unsafe-load-any-extension=no
-
-
-[MESSAGES CONTROL]
-
-# Only show warnings with the listed confidence levels. Leave empty to show
-# all. Valid levels: HIGH, INFERENCE, INFERENCE_FAILURE, UNDEFINED
-confidence=
-
-# Disable the message, report, category or checker with the given id(s). You
-# can either give multiple identifiers separated by comma (,) or put this
-# option multiple times (only on the command line, not in the configuration
-# file where it should appear only once).You can also use "--disable=all" to
-# disable everything first and then reenable specific checks. For example, if
-# you want to run only the similarities checker, you can use "--disable=all
-# --enable=similarities". If you want to run only the classes checker, but have
-# no Warning level messages displayed, use"--disable=all --enable=classes
-# --disable=W"
-disable=all
-
-# Enable the message, report, category or checker with the given id(s). You can
-# either give multiple identifier separated by comma (,) or put this option
-# multiple time (only on the command line, not in the configuration file where
-# it should appear only once). See also the "--disable" option for examples.
-enable=abstract-class-instantiated,
- access-member-before-definition,
- anomalous-backslash-in-string,
- anomalous-unicode-escape-in-string,
- apply-builtin,
- arguments-differ,
- assert-on-tuple,
- assigning-non-slot,
- assignment-from-no-return,
- assignment-from-none,
- attribute-defined-outside-init,
- backtick,
- bad-builtin,
- bad-classmethod-argument,
- bad-except-order,
- bad-exception-context,
- bad-format-character,
- bad-format-string,
- bad-format-string-key,
- bad-indentation,
- bad-open-mode,
- bad-reversed-sequence,
- bad-staticmethod-argument,
- bad-str-strip-call,
- bad-super-call,
- bare-except,
- basestring-builtin,
- binary-op-exception,
- boolean-datetime
- boolean-datetime,
- broad-except,
- buffer-builtin,
- catching-non-exception,
- cell-var-from-loop,
- cmp-builtin,
- cmp-method,
- coerce-builtin,
- coerce-method,
- confusing-with-statement,
- consider-using-enumerate,
- continue-in-finally,
- dangerous-default-value,
- delslice-method,
- deprecated-lambda,
- deprecated-method,
- deprecated-module,
- dict-iter-method,
- dict-view-method,
- differing-param-doc,
- duplicate-argument-name,
- duplicate-bases,
- duplicate-except,
- duplicate-key,
- duplicate-string-formatting-argument,
- eval-used,
- exec-used,
- execfile-builtin,
- expression-not-assigned,
- file-builtin,
- filter-builtin-not-iterating,
- format-combined-specification,
- format-needs-mapping,
- function-redefined,
- getslice-method,
- global-at-module-level,
- global-statement,
- global-variable-not-assigned,
- global-variable-undefined,
- hex-method,
- import-error,
- import-self,
- import-star-module-level,
- inconsistent-mro,
- indexing-exception,
- inherit-non-class,
- init-is-generator,
- input-builtin,
- intern-builtin,
- invalid-all-object,
- invalid-encoded-data,
- invalid-format-index,
- invalid-sequence-index,
- invalid-slice-index,
- invalid-slots,
- invalid-slots-object,
- invalid-star-assignment-target,
- invalid-unary-operand-type,
- len-as-condition,
- literal-comparison,
- logging-format-interpolation,
- logging-format-truncated,
- logging-fstring-interpolation,
- logging-not-lazy,
- logging-too-few-args,
- logging-too-many-args,
- logging-unsupported-format,
- long-builtin,
- long-suffix,
- lost-exception,
- lowercase-l-suffix,
- map-builtin-not-iterating,
- metaclass-assignment,
- method-hidden,
- misplaced-bare-raise,
- misplaced-future,
- missing-format-argument-key,
- missing-format-attribute,
- missing-format-string-key,
- missing-kwoa,
- missing-return-doc,
- missing-super-argument,
- missing-yield-doc,
- mixed-format-string,
- mixed-indentation,
- next-method-called,
- no-init,
- no-member,
- no-method-argument,
- no-name-in-module,
- no-self-argument,
- no-value-for-parameter,
- non-iterator-returned,
- non-parent-init-called,
- nonexistent-operator,
- nonlocal-and-global,
- nonlocal-without-binding,
- nonstandard-exception,
- nonzero-method,
- not-a-mapping,
- not-an-iterable,
- not-async-context-manager,
- not-callable,
- not-context-manager,
- not-in-loop,
- notimplemented-raised,
- oct-method,
- old-division,
- old-ne-operator,
- old-octal-literal,
- old-raise-syntax,
- parameter-unpacking,
- pointless-statement,
- pointless-string-statement,
- print-statement,
- property-on-old-class,
- protected-access,
- raising-bad-type,
- raising-format-tuple,
- raising-non-exception,
- raising-string,
- range-builtin-not-iterating,
- raw_input-builtin,
- redefine-in-handler,
- redefined-builtin,
- redefined-outer-name,
- reduce-builtin,
- redundant-keyword-arg,
- redundant-unittest-assert,
- redundant-yields-doc,
- reimported,
- relative-import,
- reload-builtin,
- repeated-keyword,
- return-arg-in-generator,
- return-in-init,
- return-outside-function,
- setslice-method,
- signature-differs,
- singleton-comparison,
- slots-on-old-class,
- standarderror-builtin,
- star-needs-assignment-target,
- super-init-not-called,
- super-on-old-class,
- t-method,
- too-few-format-args,
- too-many-format-args,
- too-many-function-args,
- too-many-star-expressions,
- truncated-format-string,
- undefined-all-variable,
- undefined-loop-variable,
- undefined-variable,
- unexpected-keyword-arg,
- unexpected-special-method-signature,
- unichr-builtin,
- unicode-builtin,
- unnecessary-lambda,
- unnecessary-pass,
- unnecessary-semicolon,
- unpacking-in-except,
- unpacking-non-sequence,
- unreachable,
- unsubscriptable-object,
- unsupported-binary-operation,
- unsupported-membership-test,
- unused-format-string-argument
- unused-format-string-argument,
- unused-format-string-key,
- unused-import,
- unused-variable,
- unused-wildcard-import,
- used-before-assignment,
- useless-else-on-loop
- useless-else-on-loop,
- useless-super-delegation,
- using-cmp-argument,
- using-constant-test,
- wildcard-import,
- xrange-builtin,
- yield-inside-async-function,
- yield-outside-function,
- zip-builtin-not-iterating,
- # Extensions
- multiple_types,
- overlap-except,
- docstyle,
- # Disabled for now, maybe enable in the future:
- # abstract-method, # needs some cleanup first
- # no-absolute-import, # maybe with Python 3 support
- # parameter_documentation, # needs some cleanup and maybe configuration
- # unused-argument, # needs some cleanup and per-line suppression,
- # buggy / unclear how to suppress only a single function
- # useless-object-inheritance, # when we stop having Python 2 in the codebase
- # fixme, # sometimes there is a legitimate need for a TODO
- # redundant-returns-doc, # needs some cleanup first
- # inconsistent-return-statements, # useful, but pylint takes way too long to check it
-
-
-# Consider the following sample rc files for errors to enable/disable:
-# https://github.com/datawire/quark/blob/master/.pylintrc
-# https://github.com/ClusterHQ/flocker/blob/master/.pylintrc
-
-
-[REPORTS]
-
-# Python expression which should return a note less than 10 (10 is the highest
-# note). You have access to the variables errors warning, statement which
-# respectively contain the number of errors / warnings messages and the total
-# number of statements analyzed. This is used by the global evaluation report
-# (RP0004).
-evaluation=10.0 - ((float(5 * error + warning + refactor + convention) / statement) * 10)
-
-# Template used to display messages. This is a python new-style format string
-# used to format the message information. See doc for all details
-#msg-template=
-
-# Set the output format. Available formats are text, parseable, colorized, json
-# and msvs (visual studio).You can also give a reporter class, eg
-# mypackage.mymodule.MyReporterClass.
-output-format=text
-
-# Tells whether to display a full report or only the messages
-reports=no
-
-# Activate the evaluation score.
-score=yes
-
-
-[REFACTORING]
-
-# Maximum number of nested blocks for function / method body
-max-nested-blocks=5
-
-
-[BASIC]
-
-# Naming hint for argument names
-argument-name-hint=(([a-z][a-z0-9_]{2,30})|(_[a-z0-9_]*))$
-
-# Regular expression matching correct argument names
-argument-rgx=(([a-z][a-z0-9_]{2,30})|(_[a-z0-9_]*))$
-
-# Naming hint for attribute names
-attr-name-hint=(([a-z][a-z0-9_]{2,30})|(_[a-z0-9_]*))$
-
-# Regular expression matching correct attribute names
-attr-rgx=(([a-z][a-z0-9_]{2,30})|(_[a-z0-9_]*))$
-
-# Bad variable names which should always be refused, separated by a comma
-bad-names=foo,bar,baz,toto,tutu,tata
-
-# Naming hint for class attribute names
-class-attribute-name-hint=([A-Za-z_][A-Za-z0-9_]{2,30}|(__.*__))$
-
-# Regular expression matching correct class attribute names
-class-attribute-rgx=([A-Za-z_][A-Za-z0-9_]{2,30}|(__.*__))$
-
-# Naming hint for class names
-class-name-hint=[A-Z_][a-zA-Z0-9]+$
-
-# Regular expression matching correct class names
-class-rgx=[A-Z_][a-zA-Z0-9]+$
-
-# Naming hint for constant names
-const-name-hint=(([A-Z_][A-Z0-9_]*)|(__.*__))$
-
-# Regular expression matching correct constant names
-const-rgx=(([A-Z_][A-Z0-9_]*)|(__.*__))$
-
-# Minimum line length for functions/classes that require docstrings, shorter
-# ones are exempt.
-docstring-min-length=-1
-
-# Naming hint for function names
-function-name-hint=(([a-z][a-z0-9_]{2,30})|(_[a-z0-9_]*))$
-
-# Regular expression matching correct function names
-function-rgx=(([a-z][a-z0-9_]{2,30})|(_[a-z0-9_]*))$
-
-# Good variable names which should always be accepted, separated by a comma
-good-names=i,j,k,ex,Run,_
-
-# Include a hint for the correct naming format with invalid-name
-include-naming-hint=no
-
-# Naming hint for inline iteration names
-inlinevar-name-hint=[A-Za-z_][A-Za-z0-9_]*$
-
-# Regular expression matching correct inline iteration names
-inlinevar-rgx=[A-Za-z_][A-Za-z0-9_]*$
-
-# Naming hint for method names
-method-name-hint=(([a-z][a-z0-9_]{2,30})|(_[a-z0-9_]*))$
-
-# Regular expression matching correct method names
-method-rgx=(([a-z][a-z0-9_]{2,30})|(_[a-z0-9_]*))$
-
-# Naming hint for module names
-module-name-hint=(([a-z_][a-z0-9_]*)|([A-Z][a-zA-Z0-9]+))$
-
-# Regular expression matching correct module names
-module-rgx=(([a-z_][a-z0-9_]*)|([A-Z][a-zA-Z0-9]+))$
-
-# Colon-delimited sets of names that determine each other's naming style when
-# the name regexes allow several styles.
-name-group=
-
-# Regular expression which should only match function or class names that do
-# not require a docstring.
-no-docstring-rgx=^(.*Tests)|(test_)
-
-# List of decorators that produce properties, such as abc.abstractproperty. Add
-# to this list to register other decorators that produce valid properties.
-property-classes=abc.abstractproperty
-
-# Naming hint for variable names
-variable-name-hint=(([a-z][a-z0-9_]{2,30})|(_[a-z0-9_]*))$
-
-# Regular expression matching correct variable names
-variable-rgx=(([a-z][a-z0-9_]{2,30})|(_[a-z0-9_]*))$
-
-
-[FORMAT]
-
-# Expected format of line ending, e.g. empty (any line ending), LF or CRLF.
-expected-line-ending-format=
-
-# Regexp for a line that is allowed to be longer than the limit.
-ignore-long-lines=^\s*(# )??$
-
-# Number of spaces of indent required inside a hanging or continued line.
-indent-after-paren=4
-
-# String used as indentation unit. This is usually " " (4 spaces) or "\t" (1
-# tab).
-indent-string=' '
-
-# Maximum number of characters on a single line.
-max-line-length=100
-
-# Maximum number of lines in a module
-max-module-lines=2000
-
-# List of optional constructs for which whitespace checking is disabled. `dict-
-# separator` is used to allow tabulation in dicts, etc.: {1 : 1,\n222: 2}.
-# `trailing-comma` allows a space between comma and closing bracket: (a, ).
-# `empty-line` allows space-only lines.
-no-space-check=
-
-# Allow the body of a class to be on the same line as the declaration if body
-# contains single statement.
-single-line-class-stmt=no
-
-# Allow the body of an if to be on the same line as the test if there is no
-# else.
-single-line-if-stmt=no
-
-
-[LOGGING]
-
-# Logging modules to check that the string format arguments are in logging
-# function parameter format
-logging-modules=logging
-
-
-[MISCELLANEOUS]
-
-# List of note tags to take in consideration, separated by a comma.
-notes=FIXME,XXX,TODO
-
-
-[SIMILARITIES]
-
-# Ignore comments when computing similarities.
-ignore-comments=yes
-
-# Ignore docstrings when computing similarities.
-ignore-docstrings=yes
-
-# Ignore imports when computing similarities.
-ignore-imports=no
-
-# Minimum lines number of a similarity.
-min-similarity-lines=4
-
-
-[SPELLING]
-
-# Spelling dictionary name. Available dictionaries: none. To make it working
-# install python-enchant package.
-spelling-dict=
-
-# List of comma separated words that should not be checked.
-spelling-ignore-words=
-
-# A path to a file that contains private dictionary; one word per line.
-spelling-private-dict-file=
-
-# Tells whether to store unknown words to indicated private dictionary in
-# --spelling-private-dict-file option instead of raising a message.
-spelling-store-unknown-words=no
-
-
-[TYPECHECK]
-
-# List of decorators that produce context managers, such as
-# contextlib.contextmanager. Add to this list to register other decorators that
-# produce valid context managers.
-contextmanager-decorators=contextlib.contextmanager
-
-# List of members which are set dynamically and missed by pylint inference
-# system, and so shouldn't trigger E1101 when accessed. Python regular
-# expressions are accepted.
-generated-members=
-
-# Tells whether missing members accessed in mixin class should be ignored. A
-# mixin class is detected if its name ends with "mixin" (case insensitive).
-ignore-mixin-members=yes
-
-# This flag controls whether pylint should warn about no-member and similar
-# checks whenever an opaque object is returned when inferring. The inference
-# can return multiple potential results while evaluating a Python object, but
-# some branches might not be evaluated, which results in partial inference. In
-# that case, it might be useful to still emit no-member and other checks for
-# the rest of the inferred objects.
-ignore-on-opaque-inference=yes
-
-# List of class names for which member attributes should not be checked (useful
-# for classes with dynamically set attributes). This supports the use of
-# qualified names.
-ignored-classes=optparse.Values,thread._local,_thread._local
-
-# List of module names for which member attributes should not be checked
-# (useful for modules/projects where namespaces are manipulated during runtime
-# and thus existing member attributes cannot be deduced by static analysis. It
-# supports qualified module names, as well as Unix pattern matching.
-ignored-modules=
-
-# Show a hint with possible names when a member name was not found. The aspect
-# of finding the hint is based on edit distance.
-missing-member-hint=yes
-
-# The minimum edit distance a name should have in order to be considered a
-# similar match for a missing member name.
-missing-member-hint-distance=1
-
-# The total number of similar names that should be taken in consideration when
-# showing a hint for a missing member.
-missing-member-max-choices=1
-
-
-[VARIABLES]
-
-# List of additional names supposed to be defined in builtins. Remember that
-# you should avoid to define new builtins when possible.
-additional-builtins=
-
-# Tells whether unused global variables should be treated as a violation.
-allow-global-unused-variables=yes
-
-# List of strings which can identify a callback function by name. A callback
-# name must start or end with one of those strings.
-callbacks=cb_,_cb
-
-# A regular expression matching the name of sample variables (i.e. expectedly
-# not used).
-sample-variables-rgx=_+$|(_[a-zA-Z0-9_]*[a-zA-Z0-9]+?$)|sample|^ignored_|^unused_
-
-# Argument names that match this expression will be ignored. Default to name
-# with leading underscore
-ignored-argument-names=_.*|^ignored_|^unused_
-
-# Tells whether we should check for unused import in __init__ files.
-init-import=no
-
-# List of qualified module names which can have objects that can redefine
-# builtins.
-redefining-builtins-modules=six.moves,future.builtins
-
-
-[CLASSES]
-
-# List of method names used to declare (i.e. assign) instance attributes.
-defining-attr-methods=__init__,__new__,setUp
-
-# List of member names, which should be excluded from the protected access
-# warning.
-exclude-protected=_asdict,_fields,_replace,_source,_make
-
-# List of valid names for the first argument in a class method.
-valid-classmethod-first-arg=cls
-
-# List of valid names for the first argument in a metaclass class method.
-valid-metaclass-classmethod-first-arg=mcs
-
-
-[DESIGN]
-
-# Maximum number of arguments for function / method
-max-args=5
-
-# Maximum number of attributes for a class (see R0902).
-max-attributes=7
-
-# Maximum number of boolean expressions in a if statement
-max-bool-expr=5
-
-# Maximum number of branch for function / method body
-max-branches=12
-
-# Maximum number of locals for function / method body
-max-locals=15
-
-# Maximum number of parents for a class (see R0901).
-max-parents=7
-
-# Maximum number of public methods for a class (see R0904).
-max-public-methods=20
-
-# Maximum number of return / yield for function / method body
-max-returns=6
-
-# Maximum number of statements in function / method body
-max-statements=50
-
-# Minimum number of public methods for a class (see R0903).
-min-public-methods=2
-
-
-[IMPORTS]
-
-# Allow wildcard imports from modules that define __all__.
-allow-wildcard-with-all=no
-
-# Analyse import fallback blocks. This can be used to support both Python 2 and
-# 3 compatible code, which means that the block might have code that exists
-# only in one or another interpreter, leading to false positives when analysed.
-analyse-fallback-blocks=no
-
-# Deprecated modules which should not be used, separated by a comma
-deprecated-modules=regsub,TERMIOS,Bastion,rexec
-
-# Create a graph of external dependencies in the given file (report RP0402 must
-# not be disabled)
-ext-import-graph=
-
-# Create a graph of every (i.e. internal and external) dependencies in the
-# given file (report RP0402 must not be disabled)
-import-graph=
-
-# Create a graph of internal dependencies in the given file (report RP0402 must
-# not be disabled)
-int-import-graph=
-
-# Force import order to recognize a module as part of the standard
-# compatibility libraries.
-known-standard-library=
-
-# Force import order to recognize a module as part of a third party library.
-known-third-party=enchant
-
-
-[EXCEPTIONS]
-
-# Exceptions that will emit a warning when being caught. Defaults to
-# "Exception"
-overgeneral-exceptions=Exception,BaseException
diff --git a/CHANGELOG.md b/CHANGELOG.md
new file mode 100644
index 0000000..242d338
--- /dev/null
+++ b/CHANGELOG.md
@@ -0,0 +1,63 @@
+# Changelog
+
+All notable changes to this package will be documented in this file.
+
+The format is based on [Keep a Changelog](https://keepachangelog.com/),
+and this project adheres to [Semantic Versioning](https://semver.org/).
+
+## v0.4.0 - 2026-04-06
+
+### Added
+
+- `needleman_wunsch_with_scores()` function supporting custom pairwise scoring functions for alignment, enabling continuous similarity measures (e.g., spatial proximity, text edit distance) instead of binary match/mismatch.
+- Performance benchmark test for `needleman_wunsch_with_scores()` covering runtime and memory.
+- CHANGELOG.md and link from pyproject.toml for PyPI visibility.
+
+### Changed
+
+- Update Python version support to 3.10-3.14 (drop 3.9, add 3.14).
+- Upgrade PyO3 from 0.20 to 0.28 and stable ABI minimum from Python 3.7 to 3.10.
+- Replace legacy linting toolchain (black, flake8, isort, pylint, pydocstyle, bandit) with ruff and mypy; give each linter its own `--run-only-*` flag in `scripts/lint.sh`.
+- Refactor Rust Needleman-Wunsch implementation to share core DP logic via a closure-parameterized helper, eliminating code duplication between standard and score-matrix variants.
+
+### Removed
+
+- Legacy config files (`.pylintrc`, `.pydocstyle`, `.pydocstyle_test`, `.coveragerc`, `setup.cfg`, `mypy.ini`); all configuration now lives in `pyproject.toml`.
+
+## v0.3.0 - 2025-03-05
+
+### Changed
+
+- Update Python version support to 3.9-3.13.
+- Update GitHub Actions versions to fix wheel builds.
+
+## v0.2.0 - 2024-08-22
+
+### Added
+
+- `alignment_score()` function to Python API for computing Needleman-Wunsch alignment scores on pre-aligned sequences.
+
+## v0.1.2 - 2024-05-18
+
+### Fixed
+
+- Broken 0.1.1 wheels and LICENSE file.
+
+### Changed
+
+- PEP 639 compliance with license-file.
+- Update minimum Python version to 3.8.
+
+## v0.1.1 - 2023-04-13
+
+### Fixed
+
+- Bug fixes ([#10](https://github.com/kensho-technologies/sequence_align/issues/10), [#2](https://github.com/kensho-technologies/sequence_align/issues/2)).
+
+## v0.1.0 - 2023-04-05
+
+### Added
+
+- Initial release with Needleman-Wunsch and Hirschberg algorithm implementations.
+- Rust core with Python bindings via PyO3.
+- Python 3.8-3.11 support.
diff --git a/README.md b/README.md
index 805700a..78190ce 100644
--- a/README.md
+++ b/README.md
@@ -2,16 +2,19 @@


 -
-  +
+  # sequence_align
Efficient implementations of [Needleman-Wunsch](https://en.wikipedia.org/wiki/Needleman%E2%80%93Wunsch_algorithm)
and other sequence alignment algorithms written in Rust with Python bindings via [PyO3](https://github.com/PyO3/pyo3).
+Supports both binary match/mismatch scoring and custom pairwise scoring functions for applications
+like OCR text alignment, spatial matching, and other domains where continuous similarity measures
+are needed.
# sequence_align
Efficient implementations of [Needleman-Wunsch](https://en.wikipedia.org/wiki/Needleman%E2%80%93Wunsch_algorithm)
and other sequence alignment algorithms written in Rust with Python bindings via [PyO3](https://github.com/PyO3/pyo3).
+Supports both binary match/mismatch scoring and custom pairwise scoring functions for applications
+like OCR text alignment, spatial matching, and other domains where continuous similarity measures
+are needed.
## Installation
-`sequence_align` is distributed via [PyPi](https://pypi.org/project/sequence_align) for Python 3.9 - 3.13, making installation as simple as the following --
+`sequence_align` is distributed via [PyPi](https://pypi.org/project/sequence_align) for Python 3.10 - 3.14, making installation as simple as the following --
no special setup required for cross-platform compatibility, Rust installation, etc.!
``` bash
@@ -25,21 +28,25 @@ are installed on your system. Then, install [Maturin](https://www.maturin.rs/#us
from the root of your cloned repo to build and install `sequence_align` in your active Python environment.
## Quick Start
-Pairwise sequence algorithms are available in [sequence_align.pairwise](src/sequence_align/pairwise.py).
-Currently, two algorithms are implemented: the [Needleman-Wunsch algorithm](https://en.wikipedia.org/wiki/Needleman%E2%80%93Wunsch_algorithm)
-and [Hirschberg’s algorithm](https://en.wikipedia.org/wiki/Hirschberg%27s_algorithm). Needleman-Wunsch is
-commonly used for global sequence alignment, but suffers from the fact that it uses `O(M*N)` space,
-where `M` and `N` are the lengths of the two sequences being aligned. Hirschberg’s algorithm modifies Needleman-Wunsch
-to have the same time complexity (`O(M*N)`), but only use `O(min{M, N})` space, making it an appealing option
-for memory-limited applications or extremely large sequences.
+Pairwise sequence algorithms are available in [`sequence_align.pairwise`](src/sequence_align/pairwise.py).
+The following algorithms are implemented:
-One may also compute the Needleman-Wunsch alignment score for alignments produced by either algorithm
-using [sequence_align.pairwise.alignment_score](src/sequence_align/pairwise.py).
+- [**Needleman-Wunsch**](https://en.wikipedia.org/wiki/Needleman%E2%80%93Wunsch_algorithm): Global sequence alignment with `O(M*N)` time and space.
+- [**Needleman-Wunsch with custom scores**](https://en.wikipedia.org/wiki/Needleman%E2%80%93Wunsch_algorithm): A variant that accepts a custom pairwise scoring function `score_fn(a, b) -> float` instead of flat match/mismatch scores. This is useful when alignment quality depends on continuous similarity measures rather than binary element equality.
+- [**Hirschberg**](https://en.wikipedia.org/wiki/Hirschberg%27s_algorithm): A modification of Needleman-Wunsch with the same `O(M*N)` time complexity but only `O(min{M, N})` space, making it an appealing option for memory-limited applications or extremely large sequences.
+
+One may also compute the Needleman-Wunsch alignment score for alignments produced by any of the above algorithms
+using [`alignment_score`](src/sequence_align/pairwise.py).
Using these algorithms is straightforward:
``` python
-from sequence_align.pairwise import alignment_score, hirschberg, needleman_wunsch
+from sequence_align.pairwise import (
+ alignment_score,
+ hirschberg,
+ needleman_wunsch,
+ needleman_wunsch_with_scores,
+)
# See https://en.wikipedia.org/wiki/Needleman%E2%80%93Wunsch_algorithm#/media/File:Needleman-Wunsch_pairwise_sequence_alignment.png
@@ -50,10 +57,10 @@ seq_b = ["G", "C", "A", "T", "G", "C", "G"]
aligned_seq_a, aligned_seq_b = needleman_wunsch(
seq_a,
seq_b,
+ "_", # Represent gaps with this value
match_score=1.0,
mismatch_score=-1.0,
indel_score=-1.0,
- gap="_",
)
# Expects ["G", "_", "A", "T", "T", "A", "C", "A"]
@@ -66,10 +73,10 @@ print(aligned_seq_b)
score = alignment_score(
aligned_seq_a,
aligned_seq_b,
+ "_",
match_score=1.0,
mismatch_score=-1.0,
indel_score=-1.0,
- gap="_",
)
print(score)
@@ -81,10 +88,10 @@ seq_b = ["T", "A", "T", "G", "C"]
aligned_seq_a, aligned_seq_b = hirschberg(
seq_a,
seq_b,
+ "_",
match_score=2.0,
mismatch_score=-1.0,
indel_score=-2.0,
- gap="_",
)
# Expects ["A", "G", "T", "A", "C", "G", "C", "A"]
@@ -97,12 +104,54 @@ print(aligned_seq_b)
score = alignment_score(
aligned_seq_a,
aligned_seq_b,
+ "_",
match_score=2.0,
mismatch_score=-1.0,
indel_score=-2.0,
- gap="_",
)
print(score)
+
+
+# Custom pairwise scoring: align words using character overlap similarity
+words_a = ["hello", "world", "foo"]
+words_b = ["hallo", "welt", "baz", "foo"]
+
+
+def char_overlap_score(a: str, b: str) -> float:
+ """Score based on character-level overlap between two words."""
+ if a == b:
+ return 2.0
+ shared = len(set(a) & set(b))
+ total = len(set(a) | set(b))
+ return (2.0 * shared / total) - 1.0 if total > 0 else -1.0
+
+
+aligned_words_a, aligned_words_b = needleman_wunsch_with_scores(
+ words_a,
+ words_b,
+ "_",
+ score_fn=char_overlap_score,
+ indel_score=-1.0,
+)
+
+# Expects ["hello", "world", "_", "foo"]
+print(aligned_words_a)
+
+# Expects ["hallo", "welt", "baz", "foo"]
+print(aligned_words_b)
+```
+
+## Development
+
+To set up a local development environment, ensure that both
+[Python](https://wiki.python.org/moin/BeginnersGuide/Download) and [Rust](https://www.rust-lang.org/tools/install)
+are installed, then:
+
+``` bash
+maturin develop -r # build and install in the active Python environment
+./scripts/test.sh # run tests via pytest
+./scripts/lint.sh # run all linters (ruff, mypy, cargo fmt, cargo clippy)
+./scripts/lint.sh --fix # auto-fix where possible
```
## Performance Benchmarks
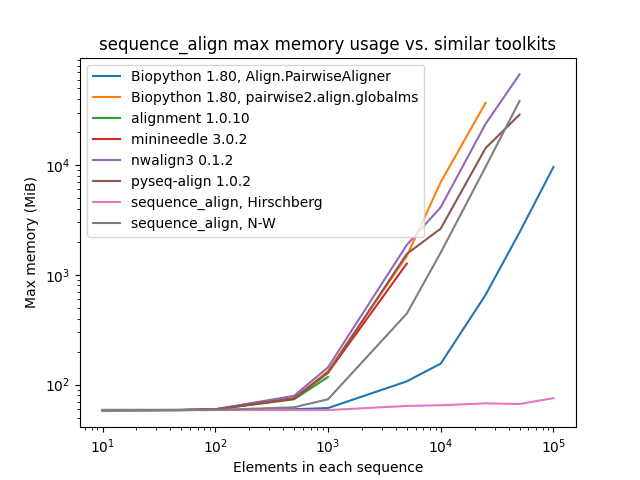
@@ -122,6 +171,9 @@ _(Please note that some lines terminate early, as some toolkits took prohibitive
+## Changelog
+See [CHANGELOG.md](CHANGELOG.md) for a full list of changes across versions.
+
## License
Licensed under the Apache 2.0 License. Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
diff --git a/codecov.yml b/codecov.yml
index 421b84e..92e23c7 100644
--- a/codecov.yml
+++ b/codecov.yml
@@ -6,4 +6,4 @@ coverage:
threshold: 0.03%
base: auto
comment:
- after_n_builds: 10 # Prevent early, spurious Codecov reports before all tests finish: https://github.com/kensho-technologies/graphql-compiler/pull/806#issuecomment-730622647. 10 is calculated here from the number of jobs to run, which is specified in the .github/workflows/tests_and_lint.yml file: 5 lint jobs (1 job per python-version) and 5 test jobs (1 job per python-version).
+ after_n_builds: 11 # Prevent early, spurious Codecov reports before all tests finish. 11 is calculated from the number of jobs: 1 lint job + 10 test jobs (1 per python-version and unit/perf).
diff --git a/mypy.ini b/mypy.ini
deleted file mode 100644
index 73f60ca..0000000
--- a/mypy.ini
+++ /dev/null
@@ -1,3 +0,0 @@
-[mypy]
-strict = True
-show_error_codes = True
diff --git a/pyproject.toml b/pyproject.toml
index 53a9fd0..0ceb176 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -4,10 +4,10 @@ build-backend = "maturin"
[project]
name = "sequence_align"
-version = "0.3.0"
+version = "0.4.0"
description = "Efficient implementations of Needleman-Wunsch and other sequence alignment algorithms in Rust with Python bindings."
readme = "README.md"
-requires-python = ">=3.9,<3.14"
+requires-python = ">=3.10,<3.15"
authors = [
{name = "Kensho Technologies LLC.", email = "sequence-align-maintainer@kensho.com"},
]
@@ -17,11 +17,11 @@ maintainers = [
license = {file = "LICENSE"} # Apache 2.0
classifiers = [
"Operating System :: OS Independent",
- "Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
+ "Programming Language :: Python :: 3.14",
"Programming Language :: Rust",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Scientific/Engineering :: Bio-Informatics",
@@ -32,34 +32,74 @@ classifiers = [
source = "https://github.com/kensho-technologies/sequence_align"
"Homepage" = "https://github.com/kensho-technologies/sequence_align"
"Bug Tracker" = "https://github.com/kensho-technologies/sequence_align/issues"
+"Changelog" = "https://github.com/kensho-technologies/sequence_align/blob/main/CHANGELOG.md"
[project.optional-dependencies]
dev = [
- "bandit",
- "black",
- "flake8",
- "isort>=5.0.0,<6",
- "mypy",
- "psutil",
- "pydocstyle",
- "pylint",
- "pytest",
- "pytest-cov",
- "pytest-subtests",
- "pyyaml",
+ "mypy>=1.10,<2",
+ "psutil>=7,<8",
+ "pytest>=9,<10",
+ "pytest-cov>=7,<8",
+ "pytest-subtests>=0.15.0,<0.16",
+ "pyyaml>=6,<7",
+ "ruff>=0.15,<0.16",
"types-psutil",
"types-pyyaml",
]
-[tool.black]
-line-length = 100
-
[tool.maturin]
# See https://www.maturin.rs/project_layout.html#import-rust-as-a-submodule-of-your-project
# Allows "from sequence_align import _sequence_align" import
module-name = "sequence_align._sequence_align"
-# "extension-module" tells pyo3 we want to build an extension module (skips linking against libpython.so)
-features = ["pyo3/extension-module"]
-[tool.bandit]
-exclude_dirs = ["tests"]
+[tool.ruff]
+line-length = 100
+extend-exclude = [".venv"]
+output-format = "grouped"
+unsafe-fixes = true
+
+[tool.ruff.lint]
+select = [
+ "E", # pycodestyle errors
+ "F", # pyflakes
+ "W", # pycodestyle warnings
+ "I", # isort
+ "D2", # pydocstyle formatting
+ "D3", # pydocstyle quote formatting
+ "UP", # pyupgrade
+]
+ignore = [
+ "E501", # line too long (handled by formatter)
+ "D203", # one-blank-line-before-class (incompatible with D211)
+ "D213", # multi-line-summary-second-line (incompatible with D212)
+]
+
+[tool.ruff.lint.per-file-ignores]
+"tests/**" = ["D"] # Ignore pydocstyle checks on tests
+
+[tool.ruff.lint.isort]
+combine-as-imports = true
+lines-after-imports = 2
+force-sort-within-sections = true
+
+[tool.mypy]
+strict = true
+show_error_codes = true
+
+[tool.pytest.ini_options]
+testpaths = ["tests"]
+
+[tool.coverage.run]
+branch = true
+omit = ["tests/*"]
+
+[tool.coverage.report]
+show_missing = true
+exclude_lines = [
+ "pragma: no cover",
+ "def __repr__",
+ "raise AssertionError",
+ "raise NotImplementedError",
+ "if __name__ == .__main__.:",
+ "^\\s*\\.\\.\\.\\s*$",
+]
diff --git a/rust/Cargo.toml b/rust/Cargo.toml
index da356d0..e9f9058 100644
--- a/rust/Cargo.toml
+++ b/rust/Cargo.toml
@@ -1,7 +1,7 @@
[package]
name = "sequence_align"
-version = "0.1.2"
-edition = "2021"
+version = "0.4.0"
+edition = "2021" # 2024 not yet supported by Maturin
license = "Apache-2.0"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
@@ -10,9 +10,9 @@ name = "sequence_align"
crate-type = ["cdylib"]
[dependencies.pyo3]
-version = "0.20.0"
-# "abi3-py37" tells pyo3 (and maturin) to build using the stable ABI with minimum Python version 3.7
-features = ["abi3-py37"]
+version = "0.28.3"
+# "abi3-py310" tells pyo3 (and maturin) to build using the stable ABI with minimum Python version 3.10
+features = ["abi3-py310"]
# Some additional optimizations; see https://deterministic.space/high-performance-rust.html
[profile.release]
diff --git a/rust/src/lib.rs b/rust/src/lib.rs
index 6dbc017..c606194 100644
--- a/rust/src/lib.rs
+++ b/rust/src/lib.rs
@@ -3,64 +3,33 @@ use pyo3::exceptions::PyValueError;
use pyo3::prelude::*;
use std::cmp;
-/// Computes an optimal global pairwise alignment between two sequences of integers using the
-/// Needleman-Wunsch algorithm and returns the corresponding aligned sequences, with any gaps
-/// represented by `gap_val`.
-///
-/// # Notes
-/// Unlike other implementations, this only considers a **single backpointer** when backtracing the
-/// optimal pairwise alignment, rather than potentially two or three backpointers for each cell if
-/// the scores are equal. Rather, this will prioritize "up" transitions (*i.e.*, gap in `seq_two`)
-/// over "left" transitions (*i.e.*, gap in `seq_one`), which in turn is prioritized over "diagonal"
-/// transitions (*i.e.*, no gap). This is a somewhat arbitrary distinction, but is consistent and
-/// leads to a simpler implementation that is both faster and uses less memory.
+/// Core Needleman-Wunsch implementation parameterized by a scoring closure.
///
-/// # Complexity
-/// This takes O(mn) time and O(mn) space complexity, where m and n are the lengths of the two
-/// sequences, respectively.
+/// The `score_fn(row_idx, col_idx)` closure returns the pairwise score for aligning
+/// `seq_one[row_idx]` with `seq_two[col_idx]`. This is monomorphized at each call site, so the
+/// closure is inlined directly into the hot inner loop with zero runtime overhead.
///
-/// # References
-/// https://en.wikipedia.org/wiki/Needleman%E2%80%93Wunsch_algorithm
-#[pyfunction]
-#[pyo3(signature = (seq_one, seq_two, match_score=1.0, mismatch_score=-1.0, indel_score=-1.0, gap_val=-1))]
-pub fn needleman_wunsch(
- seq_one: Vec,
- seq_two: Vec,
- match_score: f64,
- mismatch_score: f64,
+/// Both `needleman_wunsch` and `needleman_wunsch_with_score_matrix` delegate to this function,
+/// differing only in the closure they pass.
+fn needleman_wunsch_core(
+ seq_one: &[i64],
+ seq_two: &[i64],
indel_score: f64,
gap_val: i64,
-) -> PyResult<(Vec, Vec)> {
- // Invariant -- gap_val cannot be in either sequence
- if (seq_one.contains(&gap_val)) || (seq_two.contains(&gap_val)) {
- return Err(PyValueError::new_err(
- "Gap value {gap_val} cannot be present in either sequence",
- ));
- }
-
- // Use the shorter of the two sequences for the column dimension so that there's less memory
- // fragmentation
+ score_fn: impl Fn(usize, usize) -> f64,
+) -> (Vec, Vec) {
let seq_one_len = seq_one.len();
let seq_two_len = seq_two.len();
- let (swapped, seq_one_proc, seq_two_proc) = if seq_two_len > seq_one_len {
- (true, seq_two, seq_one)
- } else {
- (false, seq_one, seq_two)
- };
- let seq_one_proc_len = seq_one_proc.len();
- let seq_two_proc_len = seq_two_proc.len();
- let minimum_seq_len = cmp::max(seq_one_proc_len, seq_two_proc_len);
- let mut aligned_seq_one_proc = Vec::::with_capacity(minimum_seq_len);
- let mut aligned_seq_two_proc = Vec::::with_capacity(minimum_seq_len);
+ let minimum_seq_len = cmp::max(seq_one_len, seq_two_len);
+ let mut aligned_seq_one = Vec::::with_capacity(minimum_seq_len);
+ let mut aligned_seq_two = Vec::::with_capacity(minimum_seq_len);
if minimum_seq_len == 0 {
- // Both sequences empty -- no alignment needed
- return Ok((aligned_seq_one_proc, aligned_seq_two_proc));
+ return (aligned_seq_one, aligned_seq_two);
}
- // Convenience aliases
- let num_rows = seq_one_proc_len + 1;
- let num_cols = seq_two_proc_len + 1;
+ let num_rows = seq_one_len + 1;
+ let num_cols = seq_two_len + 1;
// Initialize score matrix with "border" cells marked with indel penalties increasing from the
// origin
@@ -101,24 +70,17 @@ pub fn needleman_wunsch(
.collect();
// Iterate row-by-row, calculating scores for each cell by comparing sequence values at the
- // respective indices to determine if a match or mismatch, then adding an insertion-deletion
+ // respective indices to determine the pairwise score, then adding an insertion-deletion
// (indel) score if moving left or up (not diagonally).
for row_idx in 1..num_rows {
- let seq_one_proc_idx = row_idx - 1;
+ let seq_one_idx = row_idx - 1;
for col_idx in 1..num_cols {
let cell_idx = (row_idx * num_cols) + col_idx;
+ let seq_two_idx = col_idx - 1;
- let seq_two_proc_idx = col_idx - 1;
-
- // Check if match or mismatch
- let compare_score = if seq_one_proc[seq_one_proc_idx] == seq_two_proc[seq_two_proc_idx]
- {
- match_score
- } else {
- mismatch_score
- };
+ let compare_score = score_fn(seq_one_idx, seq_two_idx);
- // Now, score transitions from diagonal, up and left, then pick the best
+ // Score transitions from diagonal, up and left, then pick the best
let diagonal_idx = cell_idx - num_cols - 1;
let diagonal_score = scores[diagonal_idx] + compare_score;
@@ -144,9 +106,8 @@ pub fn needleman_wunsch(
}
}
- // Now, trace back the backpointers to find the optimal sequence, constructing the aligned
- // sequences in the process. Preallocate to the longer of the two sequences, as it will be at
- // least that long no matter what.
+ // Trace back the backpointers to find the optimal sequence, constructing the aligned
+ // sequences in the process.
// Start from bottom right corner
let mut current_backpointer = (num_rows * num_cols) - 1;
@@ -161,42 +122,159 @@ pub fn needleman_wunsch(
let next_bp_row_idx = (next_backpointer - next_bp_col_idx) / num_cols;
if current_bp_row_idx == 0 {
- // Already exhausted sequence A -- add gap
- aligned_seq_one_proc.push(gap_val);
+ aligned_seq_one.push(gap_val);
} else {
- let current_seq_one_proc_idx = current_bp_row_idx - 1;
+ let current_seq_one_idx = current_bp_row_idx - 1;
if next_bp_row_idx == current_bp_row_idx {
- aligned_seq_one_proc.push(gap_val);
+ aligned_seq_one.push(gap_val);
} else {
- aligned_seq_one_proc.push(seq_one_proc[current_seq_one_proc_idx]);
+ aligned_seq_one.push(seq_one[current_seq_one_idx]);
}
}
if current_bp_col_idx == 0 {
- // Already exhausted sequence B -- add gap
- aligned_seq_two_proc.push(gap_val);
+ aligned_seq_two.push(gap_val);
} else {
- let current_seq_two_proc_idx = current_bp_col_idx - 1;
+ let current_seq_two_idx = current_bp_col_idx - 1;
if next_bp_col_idx == current_bp_col_idx {
- aligned_seq_two_proc.push(gap_val);
+ aligned_seq_two.push(gap_val);
} else {
- aligned_seq_two_proc.push(seq_two_proc[current_seq_two_proc_idx]);
+ aligned_seq_two.push(seq_two[current_seq_two_idx]);
}
}
current_backpointer = next_backpointer;
}
- // Reverse sequence, swap back if needed, and return!
- aligned_seq_one_proc.reverse();
- aligned_seq_two_proc.reverse();
+ aligned_seq_one.reverse();
+ aligned_seq_two.reverse();
- let (aligned_seq_one, aligned_seq_two) = if swapped {
- (aligned_seq_two_proc, aligned_seq_one_proc)
+ (aligned_seq_one, aligned_seq_two)
+}
+
+/// Computes an optimal global pairwise alignment between two sequences of integers using the
+/// Needleman-Wunsch algorithm and returns the corresponding aligned sequences, with any gaps
+/// represented by `gap_val`.
+///
+/// # Notes
+/// Unlike other implementations, this only considers a **single backpointer** when backtracing the
+/// optimal pairwise alignment, rather than potentially two or three backpointers for each cell if
+/// the scores are equal. Rather, this will prioritize "up" transitions (*i.e.*, gap in `seq_two`)
+/// over "left" transitions (*i.e.*, gap in `seq_one`), which in turn is prioritized over "diagonal"
+/// transitions (*i.e.*, no gap). This is a somewhat arbitrary distinction, but is consistent and
+/// leads to a simpler implementation that is both faster and uses less memory.
+///
+/// # Complexity
+/// This takes O(mn) time and O(mn) space complexity, where m and n are the lengths of the two
+/// sequences, respectively.
+///
+/// # References
+///
+#[pyfunction]
+#[pyo3(signature = (seq_one, seq_two, match_score=1.0, mismatch_score=-1.0, indel_score=-1.0, gap_val=-1))]
+pub fn needleman_wunsch(
+ seq_one: Vec,
+ seq_two: Vec,
+ match_score: f64,
+ mismatch_score: f64,
+ indel_score: f64,
+ gap_val: i64,
+) -> PyResult<(Vec, Vec)> {
+ // Invariant -- gap_val cannot be in either sequence
+ if (seq_one.contains(&gap_val)) || (seq_two.contains(&gap_val)) {
+ return Err(PyValueError::new_err(
+ "Gap value {gap_val} cannot be present in either sequence",
+ ));
+ }
+
+ // Use the shorter of the two sequences for the column dimension so that there's less memory
+ // fragmentation
+ let seq_one_len = seq_one.len();
+ let seq_two_len = seq_two.len();
+ let (swapped, seq_one_proc, seq_two_proc) = if seq_two_len > seq_one_len {
+ (true, seq_two, seq_one)
} else {
- (aligned_seq_one_proc, aligned_seq_two_proc)
+ (false, seq_one, seq_two)
};
+ let (mut aligned_seq_one, mut aligned_seq_two) = needleman_wunsch_core(
+ &seq_one_proc,
+ &seq_two_proc,
+ indel_score,
+ gap_val,
+ |i, j| {
+ if seq_one_proc[i] == seq_two_proc[j] {
+ match_score
+ } else {
+ mismatch_score
+ }
+ },
+ );
+
+ // Swap back if we swapped sequences for the column optimization
+ if swapped {
+ std::mem::swap(&mut aligned_seq_one, &mut aligned_seq_two);
+ }
+
+ Ok((aligned_seq_one, aligned_seq_two))
+}
+
+/// Computes an optimal global pairwise alignment between two sequences of integers using the
+/// Needleman-Wunsch algorithm with a precomputed score matrix, and returns the corresponding
+/// aligned sequences, with any gaps represented by `gap_val`.
+///
+/// Unlike the standard `needleman_wunsch` function which uses binary match/mismatch scoring, this
+/// variant accepts a full `len(seq_one) x len(seq_two)` score matrix where `score_matrix[i][j]`
+/// gives the score for aligning `seq_one[i]` with `seq_two[j]`. This enables custom pairwise
+/// scoring functions (e.g., text similarity, spatial proximity) to be used in the alignment.
+///
+/// # Complexity
+/// This takes O(mn) time and O(mn) space complexity, where m and n are the lengths of the two
+/// sequences, respectively.
+///
+/// # References
+///
+#[pyfunction]
+#[pyo3(signature = (seq_one, seq_two, score_matrix, indel_score=-1.0, gap_val=-1))]
+pub fn needleman_wunsch_with_score_matrix(
+ seq_one: Vec,
+ seq_two: Vec,
+ score_matrix: Vec>,
+ indel_score: f64,
+ gap_val: i64,
+) -> PyResult<(Vec, Vec)> {
+ // Invariant -- gap_val cannot be in either sequence
+ if (seq_one.contains(&gap_val)) || (seq_two.contains(&gap_val)) {
+ return Err(PyValueError::new_err(
+ "Gap value {gap_val} cannot be present in either sequence",
+ ));
+ }
+
+ let seq_one_len = seq_one.len();
+ let seq_two_len = seq_two.len();
+
+ // Validate score matrix dimensions
+ if score_matrix.len() != seq_one_len {
+ return Err(PyValueError::new_err(
+ "score_matrix must have len(seq_one) rows",
+ ));
+ }
+ for (i, row) in score_matrix.iter().enumerate() {
+ if row.len() != seq_two_len {
+ return Err(PyValueError::new_err(format!(
+ "score_matrix row {i} has length {} but expected {seq_two_len}",
+ row.len()
+ )));
+ }
+ }
+
+ // NOTE: We do NOT swap sequences here (unlike the standard NW), because the score matrix
+ // is indexed as score_matrix[seq_one_idx][seq_two_idx] and swapping would invalidate that.
+ let (aligned_seq_one, aligned_seq_two) =
+ needleman_wunsch_core(&seq_one, &seq_two, indel_score, gap_val, |i, j| {
+ score_matrix[i][j]
+ });
+
Ok((aligned_seq_one, aligned_seq_two))
}
@@ -307,7 +385,7 @@ fn nw_score(
/// two sequences, respectively.
///
/// # References
-/// https://en.wikipedia.org/wiki/Hirschberg%27s_algorithm
+///
#[pyfunction]
#[pyo3(signature = (seq_one, seq_two, match_score=1.0, mismatch_score=-1.0, indel_score=-1.0, gap_val=-1))]
pub fn hirschberg(
@@ -450,7 +528,7 @@ fn score_pair(
/// This takes O(n) time and O(1) space complexity, where n is the length of the sequence.
///
/// # References
-/// https://en.wikipedia.org/wiki/Needleman%E2%80%93Wunsch_algorithm
+///
#[pyfunction]
#[pyo3(signature = (seq_one, seq_two, match_score=1.0, mismatch_score=-1.0, indel_score=-1.0, gap_val=-1))]
pub fn alignment_score(
@@ -479,8 +557,9 @@ pub fn alignment_score(
/// A Python module implemented in Rust.
#[pymodule]
-fn _sequence_align(_py: Python, m: &PyModule) -> PyResult<()> {
+fn _sequence_align(m: &Bound<'_, PyModule>) -> PyResult<()> {
m.add_function(wrap_pyfunction!(needleman_wunsch, m)?)?;
+ m.add_function(wrap_pyfunction!(needleman_wunsch_with_score_matrix, m)?)?;
m.add_function(wrap_pyfunction!(hirschberg, m)?)?;
m.add_function(wrap_pyfunction!(alignment_score, m)?)?;
Ok(())
diff --git a/scripts/lint.sh b/scripts/lint.sh
index 8642b29..5a59bc2 100755
--- a/scripts/lint.sh
+++ b/scripts/lint.sh
@@ -11,68 +11,60 @@ shopt -s globstar nullglob
# Break on first error.
set -e
-
-function get_physical_cores() {
- if [[ -f /proc/cpuinfo ]]
- then
- grep "core id" /proc/cpuinfo |
- sort -u |
- wc -l
- else
- sysctl -n hw.physicalcpu 2>/dev/null || echo 4
- fi
-}
-
-
# Parse input arguments.
-diff_only=0
any_run_only_set=0
-run_fast_linters=0 # copyright line check, isort, black, flake8, pydocstyle, cargo fmt
-run_pylint=0
+run_copyright_check=0
+run_ruff_check=0
+run_ruff_format=0
+run_cargo_fmt=0
run_mypy=0
-run_bandit=0
run_cargo_clippy=0
fix=0
for i in "$@"; do
case $i in
- --diff )
- diff_only=1
+ --run-only-copyright-check )
+ if [ "$any_run_only_set" -eq 1 ]; then
+ echo "Multiple run-only options set, this is not supported.";
+ exit 1;
+ fi
+ any_run_only_set=1
+ run_copyright_check=1
shift;;
- --run-only-fast-linters )
+ --run-only-ruff-check )
if [ "$any_run_only_set" -eq 1 ]; then
echo "Multiple run-only options set, this is not supported.";
exit 1;
fi
any_run_only_set=1
- run_fast_linters=1
+ run_ruff_check=1
shift;;
- --run-only-pylint )
+ --run-only-ruff-format )
if [ "$any_run_only_set" -eq 1 ]; then
echo "Multiple run-only options set, this is not supported.";
exit 1;
fi
any_run_only_set=1
- run_pylint=1
+ run_ruff_format=1
shift;;
- --run-only-mypy )
+ --run-only-cargo-fmt )
if [ "$any_run_only_set" -eq 1 ]; then
echo "Multiple run-only options set, this is not supported.";
exit 1;
fi
any_run_only_set=1
- run_mypy=1
+ run_cargo_fmt=1
shift;;
- --run-only-bandit )
+ --run-only-mypy )
if [ "$any_run_only_set" -eq 1 ]; then
echo "Multiple run-only options set, this is not supported.";
exit 1;
fi
any_run_only_set=1
- run_bandit=1
+ run_mypy=1
shift;;
--run-only-cargo-clippy )
@@ -96,75 +88,53 @@ for i in "$@"; do
done
if [ "$any_run_only_set" -eq 0 ]; then
- run_fast_linters=1
- run_pylint=1
+ run_copyright_check=1
+ run_ruff_check=1
+ run_ruff_format=1
+ run_cargo_fmt=1
run_mypy=1
- run_bandit=1
run_cargo_clippy=1
fi
# Make sure the current working directory for this script is the root directory.
cd "$(git -C "$(dirname "${0}")" rev-parse --show-toplevel )"
-# Get all Python files or directories that need to be linted.
-py_lintable_locations="."
-
-# pylint doesn't support linting directories that aren't packages:
-# https://github.com/PyCQA/pylint/issues/352
-# Use **/*.py to supply all Python files for individual linting.
-pylint_lintable_locations="**/*.py *.py"
-
-if [ "$diff_only" -eq 1 ] ; then
- # Quotes don't need to be escaped because they nest with $( ).
- py_lintable_locations="$(git diff --name-only main... | grep ".*\.py$")"
- pylint_lintable_locations="$py_lintable_locations"
-fi
-
# Continue on error to allow ignoring certain linters.
# Errors are manually aggregated at the end.
set +e
-if [ "$run_fast_linters" -eq 1 ]; then
+if [ "$run_copyright_check" -eq 1 ]; then
echo -e '*** Running copyright line check... ***\n'
./scripts/copyright_line_check.sh
copyright_line_check_exit_code=$?
echo -e "\n*** End of copyright line check run; exit: $copyright_line_check_exit_code ***\n"
+fi
- echo -e '*** Running isort... ***\n'
+if [ "$run_ruff_check" -eq 1 ]; then
+ echo -e '*** Running ruff check... ***\n'
if [ "$fix" -eq 1 ]; then
- isort --recursive --settings-path=setup.cfg $py_lintable_locations
- isort_exit_code=$?
+ ruff check --fix .
+ ruff_check_exit_code=$?
else
- isort --recursive --check-only --diff --settings-path=setup.cfg $py_lintable_locations
- isort_exit_code=$?
+ ruff check .
+ ruff_check_exit_code=$?
fi
- echo -e "\n*** End of isort run; exit: $isort_exit_code ***\n"
+ echo -e "\n*** End of ruff check run; exit: $ruff_check_exit_code ***\n"
+fi
- echo -e '*** Running black... ***\n'
+if [ "$run_ruff_format" -eq 1 ]; then
+ echo -e '*** Running ruff format... ***\n'
if [ "$fix" -eq 1 ]; then
- black .
- black_exit_code=$?
+ ruff format .
+ ruff_format_exit_code=$?
else
- black --check --diff .
- black_exit_code=$?
+ ruff format --check --diff .
+ ruff_format_exit_code=$?
fi
- echo -e "\n*** End of black run; exit: $black_exit_code ***\n"
-
- echo -e '*** Running flake8... ***\n'
- flake8 --config=setup.cfg $py_lintable_locations
- flake_exit_code=$?
- echo -e "\n*** End of flake8 run, exit: $flake_exit_code ***\n"
-
- echo -e '\n*** Running pydocstyle... ***\n'
- pydocstyle --config=.pydocstyle $py_lintable_locations
- pydocstyle_exit_code=$?
- echo -e "\n*** End of pydocstyle run, exit: $pydocstyle_exit_code ***\n"
-
- echo -e '\n*** Running pydocstyle on tests... ***\n'
- pydocstyle --config=.pydocstyle_test $py_lintable_locations
- pydocstyle_test_exit_code=$?
- echo -e "\n*** End of pydocstyle on tests run, exit: $pydocstyle_test_exit_code ***\n"
+ echo -e "\n*** End of ruff format run; exit: $ruff_format_exit_code ***\n"
+fi
+if [ "$run_cargo_fmt" -eq 1 ]; then
echo -e '\n*** Running cargo fmt...\n'
if [ "$fix" -eq 1 ]; then
cargo fmt -v --all --manifest-path=./rust/Cargo.toml
@@ -178,26 +148,11 @@ fi
if [ "$run_mypy" -eq 1 ]; then
echo -e '*** Running mypy... ***\n'
- mypy $py_lintable_locations
+ mypy .
mypy_exit_code=$?
echo -e "\n*** End of mypy run, exit: $mypy_exit_code ***\n"
fi
-if [ "$run_pylint" -eq 1 ]; then
- physical_core_count="$(get_physical_cores)"
- echo -e "\n*** Running pylint using ${physical_core_count} cores... ***\n"
- pylint --jobs="$physical_core_count" $pylint_lintable_locations
- pylint_exit_code=$?
- echo -e "\n*** End of pylint run, exit: $pylint_exit_code ***\n"
-fi
-
-if [ "$run_bandit" -eq 1 ]; then
- echo -e '\n*** Running bandit... ***\n'
- bandit -c ./pyproject.toml -r $py_lintable_locations
- bandit_exit_code=$?
- echo -e "\n*** End of bandit run, exit: $bandit_exit_code ***\n"
-fi
-
if [ "$run_cargo_clippy" -eq 1 ]; then
# Warn about pedantic stuff; deny all other defaults
echo -e '\n*** Running cargo clippy...\n'
@@ -217,45 +172,36 @@ fi
if [[
(
- ("$run_fast_linters" == 1) && (
- ("$copyright_line_check_exit_code" != "0") ||
- ("$isort_exit_code" != "0") ||
- ("$black_exit_code" != "0") ||
- ("$flake_exit_code" != "0") ||
- ("$pydocstyle_exit_code" != "0") ||
- ("$pydocstyle_test_exit_code" != "0") ||
- ("$cargo_fmt_exit_code" != "0")
- )
+ ("$run_copyright_check" == 1) && ("$copyright_line_check_exit_code" != "0")
) || (
- ("$run_mypy" == 1) && ("$mypy_exit_code" != "0")
+ ("$run_ruff_check" == 1) && ("$ruff_check_exit_code" != "0")
) || (
- ("$run_pylint" == 1) && ("$pylint_exit_code" != "0")
+ ("$run_ruff_format" == 1) && ("$ruff_format_exit_code" != "0")
) || (
- ("$run_bandit" == 1) && ("$bandit_exit_code" != "0")
+ ("$run_cargo_fmt" == 1) && ("$cargo_fmt_exit_code" != "0")
+ ) || (
+ ("$run_mypy" == 1) && ("$mypy_exit_code" != "0")
) || (
("$run_cargo_clippy" == 1) && ("$cargo_clippy_exit_code" != "0")
)
]]; then
echo -e "\n*** Lint failed. ***\n"
- if [ "$run_fast_linters" -eq 1 ]; then
+ if [ "$run_copyright_check" -eq 1 ]; then
echo -e "copyright line check exit: $copyright_line_check_exit_code"
- echo -e "isort exit: $isort_exit_code"
- echo -e "black exit: $black_exit_code"
- echo -e "flake8 exit: $flake_exit_code"
- echo -e "pydocstyle exit: $pydocstyle_exit_code"
- echo -e "pydocstyle on tests exit: $pydocstyle_test_exit_code"
+ fi
+ if [ "$run_ruff_check" -eq 1 ]; then
+ echo -e "ruff check exit: $ruff_check_exit_code"
+ fi
+ if [ "$run_ruff_format" -eq 1 ]; then
+ echo -e "ruff format exit: $ruff_format_exit_code"
+ fi
+ if [ "$run_cargo_fmt" -eq 1 ]; then
echo -e "cargo fmt exit: $cargo_fmt_exit_code"
fi
if [ "$run_mypy" -eq 1 ]; then
echo -e "mypy exit: $mypy_exit_code"
fi
- if [ "$run_pylint" -eq 1 ]; then
- echo -e "pylint exit: $pylint_exit_code"
- fi
- if [ "$run_bandit" -eq 1 ]; then
- echo -e "bandit exit: $bandit_exit_code"
- fi
if [ "$run_cargo_clippy" -eq 1 ]; then
echo -e "cargo clippy exit: $cargo_clippy_exit_code"
fi
diff --git a/scripts/test.sh b/scripts/test.sh
index 3948ceb..8ff6e9c 100755
--- a/scripts/test.sh
+++ b/scripts/test.sh
@@ -1,3 +1,4 @@
#!/usr/bin/env bash
# Copyright 2023-present Kensho Technologies, LLC.
-python -m pytest -s --cov=src/sequence_align "$@"
+set -euxo pipefail
+python -m pytest "$@"
diff --git a/setup.cfg b/setup.cfg
deleted file mode 100644
index bb456ba..0000000
--- a/setup.cfg
+++ /dev/null
@@ -1,27 +0,0 @@
-[isort]
-profile = black
-multi_line_output = 3
-line_length = 100
-lines_after_imports = 2
-force_sort_within_sections = 1
-
-[flake8]
-max-line-length = 100
-show-source = True
-inline-quotes = single
-multiline-quotes = '''
-docstring-quotes = """
-select =
- E,
- F,
- W,
- Q,
- T
-ignore =
- W503,
- W504
-exclude =
- .git,
- __pycache__,
- .pytest_cache,
- .mypy_cache
diff --git a/src/sequence_align/pairwise.py b/src/sequence_align/pairwise.py
index d16c9e4..1892bb2 100644
--- a/src/sequence_align/pairwise.py
+++ b/src/sequence_align/pairwise.py
@@ -1,9 +1,13 @@
# Copyright 2023-present Kensho Technologies, LLC.
-from typing import Sequence
+from collections.abc import Callable, Sequence
+from typing import TypeVar
from sequence_align import _sequence_align # type: ignore
+T = TypeVar("T")
+
+
_GAP_VAL = -1
@@ -44,24 +48,24 @@ def _idx2entry(
def needleman_wunsch(
seq_a: Sequence[str],
seq_b: Sequence[str],
+ gap: str,
match_score: float = 1.0,
mismatch_score: float = -1.0,
indel_score: float = -1.0,
- gap: str = "-",
) -> tuple[list[str], list[str]]:
"""Compute an optimal global pairwise alignment using the Needleman-Wunsch algorithm.
Args:
seq_a: First sequence in pair to align.
seq_b: Second sequence in pair to align.
+ gap: Value to use for marking a gap in one sequence in the final output. Cannot be present
+ in `seq_a` and/or `seq_b`.
match_score: Score to apply for transitions where the sequences match each other at a given
index. Defaults to 1.
mismatch_score: Score to apply for transitions where the sequences do _not_ match each other
at a given index. Defaults to -1.
indel_score: Score to apply for insertion/deletion transitions where one sequence advances
without the other advancing (thus inserting a gap). Defaults to -1.
- gap: Value to use for marking a gap in one sequence in the final output. Cannot be present
- in `seq_a` and/or `seq_b`. Defaults to "-".
Returns:
Sequences A and B, respectively, aligned to each other with gaps represented by `gap`.
@@ -99,27 +103,101 @@ def needleman_wunsch(
return _idx2entry(idx2symbol, seq_a_indices_aligned, seq_b_indices_aligned, gap)
+def needleman_wunsch_with_scores(
+ seq_a: Sequence[T],
+ seq_b: Sequence[T],
+ gap: T,
+ score_fn: Callable[[T, T], float],
+ indel_score: float = -1.0,
+) -> tuple[list[T], list[T]]:
+ """Compute an optimal global pairwise alignment using Needleman-Wunsch with a custom score fn.
+
+ Unlike the standard ``needleman_wunsch`` which uses flat match/mismatch scores, this variant
+ accepts an arbitrary pairwise scoring function ``score_fn(a_i, b_j) -> float`` that is called
+ for every pair of elements. The Python wrapper precomputes the full score matrix and passes it
+ to the Rust implementation.
+
+ This is useful when alignment quality depends on continuous similarity measures (e.g., spatial
+ proximity, text edit distance, width compatibility) rather than binary equality.
+
+ Args:
+ seq_a: First sequence in pair to align.
+ seq_b: Second sequence in pair to align.
+ gap: Value to use for marking a gap in one sequence in the final output. Cannot be present
+ in ``seq_a`` and/or ``seq_b``.
+ score_fn: A callable that takes one element from ``seq_a`` and one from ``seq_b`` and
+ returns a float score. Higher scores indicate better alignment between the two elements.
+ indel_score: Score to apply for insertion/deletion transitions where one sequence advances
+ without the other advancing (thus inserting a gap). Defaults to -1.
+
+ Returns:
+ Sequences A and B, respectively, aligned to each other with gaps represented by ``gap``.
+
+ Raises:
+ ValueError: If ``gap`` is found in ``seq_a`` and/or ``seq_b``.
+
+ Note:
+ This takes O(mn) time and O(mn) space complexity, where m and n are the lengths of the two
+ sequences, respectively.
+
+ See https://en.wikipedia.org/wiki/Needleman%E2%80%93Wunsch_algorithm for more information.
+ """
+ if gap in seq_a or gap in seq_b:
+ raise ValueError(f'Gap entry "{gap}" found in seq_a and/or seq_b; must not exist in either')
+
+ seq_a_list = list(seq_a)
+ seq_b_list = list(seq_b)
+
+ if len(seq_a_list) == 0 and len(seq_b_list) == 0:
+ return ([], [])
+
+ # Precompute the full score matrix
+ score_matrix: list[list[float]] = [
+ [score_fn(a_elem, b_elem) for b_elem in seq_b_list] for a_elem in seq_a_list
+ ]
+
+ # Use element indices instead of values so that the score matrix indices stay aligned with the
+ # original elements even when elements compare equal but are different objects.
+ seq_a_indices = list(range(len(seq_a_list)))
+ seq_b_indices = list(range(len(seq_b_list)))
+
+ # Run alignment in Rust
+ aligned_a_indices, aligned_b_indices = _sequence_align.needleman_wunsch_with_score_matrix(
+ seq_a_indices,
+ seq_b_indices,
+ score_matrix,
+ indel_score=indel_score,
+ gap_val=_GAP_VAL,
+ )
+
+ # Map back to original elements
+ aligned_a: list[T] = [gap if idx == _GAP_VAL else seq_a_list[idx] for idx in aligned_a_indices]
+ aligned_b: list[T] = [gap if idx == _GAP_VAL else seq_b_list[idx] for idx in aligned_b_indices]
+
+ return (aligned_a, aligned_b)
+
+
def hirschberg(
seq_a: Sequence[str],
seq_b: Sequence[str],
+ gap: str,
match_score: float = 1.0,
mismatch_score: float = -1.0,
indel_score: float = -1.0,
- gap: str = "-",
) -> tuple[list[str], list[str]]:
"""Compute an optimal global pairwise alignment using the Hirschberg algorithm.
Args:
seq_a: First sequence in pair to align.
seq_b: Second sequence in pair to align.
+ gap: Value to use for marking a gap in one sequence in the final output. Cannot be present
+ in `seq_a` and/or `seq_b`.
match_score: Score to apply for transitions where the sequences match each other at a given
index. Defaults to 1.
mismatch_score: Score to apply for transitions where the sequences do _not_ match each other
at a given index. Defaults to -1.
indel_score: Score to apply for insertion/deletion transitions where one sequence advances
without the other advancing (thus inserting a gap). Defaults to -1.
- gap: Value to use for marking a gap in one sequence in the final output. Cannot be present
- in `seq_a` and/or `seq_b`. Defaults to "-".
Returns:
Sequences A and B, respectively, aligned to each other with gaps represented by `gap`.
@@ -165,23 +243,23 @@ def hirschberg(
def alignment_score(
aligned_seq_a: Sequence[str],
aligned_seq_b: Sequence[str],
+ gap: str,
match_score: float = 1.0,
mismatch_score: float = -1.0,
indel_score: float = -1.0,
- gap: str = "-",
) -> float:
"""Compute the alignment score for the pair of sequences.
Args:
aligned_seq_a: First aligned sequence.
aligned_seq_b: Second aligned sequence.
+ gap: Value used for marking gaps in the aligned sequences.
match_score: Score to apply for transitions where the sequences match each other at a given
index. Defaults to 1.
mismatch_score: Score to apply for transitions where the sequences do _not_ match each other
at a given index. Defaults to -1.
indel_score: Score to apply for insertion/deletion transitions where one sequence advances
without the other advancing (thus inserting a gap). Defaults to -1.
- gap: Value to use for marking gaps in the aligned sequences. Defaults to "-".
Returns:
Needleman-Wunsch alignment score representing the sum of match, mismatch and
diff --git a/tests/perf/expected_perf.yml b/tests/perf/expected_perf.yml
index 6de4379..92ae51e 100644
--- a/tests/perf/expected_perf.yml
+++ b/tests/perf/expected_perf.yml
@@ -9,6 +9,15 @@ needleman_wunsch:
# More consistent
median: 1500.0 # MiB
tolerance: 0.20 # +/- 20%
+needleman_wunsch_with_scores:
+ runtime:
+ # Dominated by Python-side score matrix precomputation (O(m*n) calls to score_fn)
+ median: 15.0 # Seconds
+ tolerance: 0.50 # +/- 50% (7.5 - 22.5s)
+ memory:
+ # Larger than standard NW due to Python-side score matrix (list of lists of floats)
+ median: 5400.0 # MiB
+ tolerance: 0.20 # +/- 20%
hirschberg:
runtime:
# Generally more sensitive to machine/environment
diff --git a/tests/perf/test_hirschberg.py b/tests/perf/test_hirschberg.py
index 5cad518..c4c36c0 100644
--- a/tests/perf/test_hirschberg.py
+++ b/tests/perf/test_hirschberg.py
@@ -40,10 +40,10 @@ def test_runtime(self) -> None:
hirschberg(
seq_a,
seq_b,
+ DEFAULT_GAP,
match_score=MATCH_SCORE,
mismatch_score=MISMATCH_SCORE,
indel_score=INDEL_SCORE,
- gap=DEFAULT_GAP,
)
end_t = time.perf_counter()
runtimes.append(end_t - start_t)
@@ -58,8 +58,8 @@ def test_runtime(self) -> None:
self.assertLessEqual(
abs(diff_pct),
tolerance,
- msg=f"""Expected runtime to be within {tolerance * 100.}% of {exp_median:.3f}s.
-Got {median_runtime:.3f}s ({sign}{100. * diff_pct}%) instead.
+ msg=f"""Expected runtime to be within {tolerance * 100.0}% of {exp_median:.3f}s.
+Got {median_runtime:.3f}s ({sign}{100.0 * diff_pct}%) instead.
Consider adjusting the median number and/or tolerance if this change in performance is expected.""",
)
@@ -71,12 +71,11 @@ def test_memory(self) -> None:
for _ in range(MEMORY_TRIALS):
max_mem = max_memory_usage(
hirschberg,
- (seq_a, seq_b),
+ (seq_a, seq_b, DEFAULT_GAP),
{
"match_score": MATCH_SCORE,
"mismatch_score": MISMATCH_SCORE,
"indel_score": INDEL_SCORE,
- "gap": DEFAULT_GAP,
},
)
max_mems.append(max_mem)
@@ -91,8 +90,8 @@ def test_memory(self) -> None:
self.assertLessEqual(
abs(diff_pct),
tolerance,
- msg=f"""Expected memory to be within {tolerance * 100.}% of {exp_median:.3f}MiB.
-Got {median_max_mem:.3f}MiB ({sign}{100. * diff_pct}%) instead.
+ msg=f"""Expected memory to be within {tolerance * 100.0}% of {exp_median:.3f}MiB.
+Got {median_max_mem:.3f}MiB ({sign}{100.0 * diff_pct}%) instead.
Consider adjusting the median number and/or tolerance if this change in performance is expected.""",
)
diff --git a/tests/perf/test_needleman_wunsch.py b/tests/perf/test_needleman_wunsch.py
index 5919bcf..b057d2d 100644
--- a/tests/perf/test_needleman_wunsch.py
+++ b/tests/perf/test_needleman_wunsch.py
@@ -40,10 +40,10 @@ def test_runtime(self) -> None:
needleman_wunsch(
seq_a,
seq_b,
+ DEFAULT_GAP,
match_score=MATCH_SCORE,
mismatch_score=MISMATCH_SCORE,
indel_score=INDEL_SCORE,
- gap=DEFAULT_GAP,
)
end_t = time.perf_counter()
runtimes.append(end_t - start_t)
@@ -58,8 +58,8 @@ def test_runtime(self) -> None:
self.assertLessEqual(
abs(diff_pct),
tolerance,
- msg=f"""Expected runtime to be within {tolerance * 100.}% of {exp_median:.3f}s.
-Got {median_runtime:.3f}s ({sign}{100. * diff_pct}%) instead.
+ msg=f"""Expected runtime to be within {tolerance * 100.0}% of {exp_median:.3f}s.
+Got {median_runtime:.3f}s ({sign}{100.0 * diff_pct}%) instead.
Consider adjusting the median number and/or tolerance if this change in performance is expected.""",
)
@@ -71,12 +71,11 @@ def test_memory(self) -> None:
for _ in range(MEMORY_TRIALS):
max_mem = max_memory_usage(
needleman_wunsch,
- (seq_a, seq_b),
+ (seq_a, seq_b, DEFAULT_GAP),
{
"match_score": MATCH_SCORE,
"mismatch_score": MISMATCH_SCORE,
"indel_score": INDEL_SCORE,
- "gap": DEFAULT_GAP,
},
)
max_mems.append(max_mem)
@@ -91,8 +90,8 @@ def test_memory(self) -> None:
self.assertLessEqual(
abs(diff_pct),
tolerance,
- msg=f"""Expected memory to be within {tolerance * 100.}% of {exp_median:.3f}MiB.
-Got {median_max_mem:.3f}MiB ({sign}{100. * diff_pct}%) instead.
+ msg=f"""Expected memory to be within {tolerance * 100.0}% of {exp_median:.3f}MiB.
+Got {median_max_mem:.3f}MiB ({sign}{100.0 * diff_pct}%) instead.
Consider adjusting the median number and/or tolerance if this change in performance is expected.""",
)
diff --git a/tests/perf/test_needleman_wunsch_with_scores.py b/tests/perf/test_needleman_wunsch_with_scores.py
new file mode 100644
index 0000000..10f8bc1
--- /dev/null
+++ b/tests/perf/test_needleman_wunsch_with_scores.py
@@ -0,0 +1,98 @@
+# Copyright 2023-present Kensho Technologies, LLC.
+import time
+from typing import Any
+import unittest
+
+from sequence_align.pairwise import needleman_wunsch_with_scores
+
+from .utils import create_seq_pair, get_expected_perf, max_memory_usage
+
+
+INDEL_SCORE = -1.0
+DEFAULT_GAP = "_"
+
+RUNTIME_SEQ_A_LEN = 5_000
+RUNTIME_TRIALS = 3
+
+MEMORY_SEQ_A_LEN = 10_000
+MEMORY_TRIALS = 3
+
+
+def char_overlap_score(a: str, b: str) -> float:
+ """Score based on character set overlap — a continuous similarity measure."""
+ if a == b:
+ return 2.0
+ shared = len(set(a) & set(b))
+ total = len(set(a) | set(b))
+ return (2.0 * shared / total) - 1.0 if total > 0 else -1.0
+
+
+class TestNeedlemanWunschWithScores(unittest.TestCase):
+ # Needed for mypy to not complain
+ expected_perf: dict[str, Any] = dict()
+
+ @classmethod
+ def setUpClass(cls) -> None:
+ super().setUpClass()
+
+ cls.expected_perf = get_expected_perf("needleman_wunsch_with_scores")
+
+ def test_runtime(self) -> None:
+ seq_a, seq_b = create_seq_pair(RUNTIME_SEQ_A_LEN)
+
+ runtimes = list()
+ for _ in range(RUNTIME_TRIALS):
+ start_t = time.perf_counter()
+ needleman_wunsch_with_scores(
+ seq_a,
+ seq_b,
+ DEFAULT_GAP,
+ char_overlap_score,
+ indel_score=INDEL_SCORE,
+ )
+ end_t = time.perf_counter()
+ runtimes.append(end_t - start_t)
+
+ median_runtime = sorted(runtimes)[len(runtimes) // 2]
+ exp_median = self.expected_perf["runtime"]["median"]
+ diff = median_runtime - exp_median
+ sign = "+" if diff > 0 else "-"
+ diff_pct = abs(diff / exp_median)
+
+ tolerance = self.expected_perf["runtime"]["tolerance"]
+ self.assertLessEqual(
+ abs(diff_pct),
+ tolerance,
+ msg=f"""Expected runtime to be within {tolerance * 100.0}% of {exp_median:.3f}s.
+Got {median_runtime:.3f}s ({sign}{100.0 * diff_pct}%) instead.
+
+Consider adjusting the median number and/or tolerance if this change in performance is expected.""",
+ )
+
+ def test_memory(self) -> None:
+ seq_a, seq_b = create_seq_pair(MEMORY_SEQ_A_LEN)
+
+ max_mems = list()
+ for _ in range(MEMORY_TRIALS):
+ max_mem = max_memory_usage(
+ needleman_wunsch_with_scores,
+ (seq_a, seq_b, DEFAULT_GAP, char_overlap_score),
+ {"indel_score": INDEL_SCORE},
+ )
+ max_mems.append(max_mem)
+
+ median_max_mem = sorted(max_mems)[len(max_mems) // 2]
+ exp_median = self.expected_perf["memory"]["median"]
+ diff = median_max_mem - exp_median
+ sign = "+" if diff > 0 else "-"
+ diff_pct = abs(diff / exp_median)
+
+ tolerance = self.expected_perf["memory"]["tolerance"]
+ self.assertLessEqual(
+ abs(diff_pct),
+ tolerance,
+ msg=f"""Expected memory to be within {tolerance * 100.0}% of {exp_median:.3f}MiB.
+Got {median_max_mem:.3f}MiB ({sign}{100.0 * diff_pct}%) instead.
+
+Consider adjusting the median number and/or tolerance if this change in performance is expected.""",
+ )
diff --git a/tests/perf/utils.py b/tests/perf/utils.py
index 86d02b6..0576445 100644
--- a/tests/perf/utils.py
+++ b/tests/perf/utils.py
@@ -1,8 +1,9 @@
# Copyright 2023-present Kensho Technologies, LLC.
+from collections.abc import Callable
import multiprocessing as mp
import os
import random
-from typing import Any, Callable
+from typing import Any
import psutil
import yaml
@@ -57,7 +58,7 @@ def create_seq_pair(seq_a_len: int) -> tuple[list[str], list[str]]:
def get_expected_perf(key: str) -> Any:
"""Load the expected performance dictionary for the provided key."""
- with open(EXPECTED_PERF_YML, "r") as fd:
+ with open(EXPECTED_PERF_YML) as fd:
expected_perf_full = yaml.safe_load(fd)
return expected_perf_full[key]
diff --git a/tests/unit/test_alignment_score.py b/tests/unit/test_alignment_score.py
index 03099cf..68e0f02 100644
--- a/tests/unit/test_alignment_score.py
+++ b/tests/unit/test_alignment_score.py
@@ -11,12 +11,12 @@
class TestAlignmentScore(unittest.TestCase):
def test_empty(self) -> None:
"""Score of two empty sequences should always be zero."""
- self.assertEqual(alignment_score([], []), 0)
+ self.assertEqual(alignment_score([], [], DEFAULT_GAP), 0)
def test_unequal(self) -> None:
"""Should fail with sequences of different length."""
with self.assertRaises(ValueError):
- alignment_score(["A", "B", "C"], ["D", "E"])
+ alignment_score(["A", "B", "C"], ["D", "E"], DEFAULT_GAP)
def test_normal(self) -> None:
"""Score of two nonempty sequences should match and in both directions."""
@@ -37,10 +37,10 @@ def test_normal(self) -> None:
alignment_score(
seq_a_proc,
seq_b_proc,
+ DEFAULT_GAP,
match_score=match_score,
mismatch_score=mismatch_score,
indel_score=indel_score,
- gap=DEFAULT_GAP,
),
expected_score,
)
diff --git a/tests/unit/test_hirschberg.py b/tests/unit/test_hirschberg.py
index ca50994..aeae0ba 100644
--- a/tests/unit/test_hirschberg.py
+++ b/tests/unit/test_hirschberg.py
@@ -10,7 +10,7 @@
class TestHirschberg(unittest.TestCase):
def test_empty(self) -> None:
- aligned_seq_a, aligned_seq_b = hirschberg([], [])
+ aligned_seq_a, aligned_seq_b = hirschberg([], [], DEFAULT_GAP)
self.assertEqual(len(aligned_seq_a), 0)
self.assertEqual(len(aligned_seq_b), 0)
@@ -24,10 +24,10 @@ def test_normal(self) -> None:
aligned_seq_a, aligned_seq_b = hirschberg(
seq_a,
seq_b,
+ DEFAULT_GAP,
match_score=2.0,
mismatch_score=-1.0,
indel_score=-2.0,
- gap=DEFAULT_GAP,
)
self.assertEqual(aligned_seq_a, exp_seq_a)
self.assertEqual(aligned_seq_b, exp_seq_b)
@@ -64,8 +64,8 @@ def test_words(self) -> None:
seq_a_aligned, seq_b_aligned = hirschberg(
seq_a,
seq_b,
+ DEFAULT_GAP,
indel_score=0.0, # Don't punish gaps
- gap=DEFAULT_GAP,
)
self.assertEqual(seq_a_aligned, exp_seq_a_aligned)
self.assertEqual(seq_b_aligned, exp_seq_b_aligned)
@@ -82,10 +82,10 @@ def test_encourage_gaps(self) -> None:
aligned_seq_a, aligned_seq_b = hirschberg(
seq_a,
seq_b,
+ DEFAULT_GAP,
match_score=1.0,
mismatch_score=-1.0,
indel_score=100.0,
- gap=DEFAULT_GAP,
)
self.assertEqual(aligned_seq_a, exp_seq_a)
self.assertEqual(aligned_seq_b, exp_seq_b)
@@ -94,10 +94,10 @@ def test_encourage_gaps(self) -> None:
aligned_seq_a, aligned_seq_b = hirschberg(
seq_a,
seq_b,
+ DEFAULT_GAP,
match_score=-1.0,
mismatch_score=1.0,
indel_score=100.0,
- gap=DEFAULT_GAP,
)
self.assertEqual(aligned_seq_a, exp_seq_a)
self.assertEqual(aligned_seq_b, exp_seq_b)
@@ -112,10 +112,10 @@ def test_encourage_mismatches(self) -> None:
aligned_seq_a, aligned_seq_b = hirschberg(
seq_a,
seq_b,
+ DEFAULT_GAP,
match_score=1.0,
mismatch_score=100.0,
indel_score=-1.0,
- gap=DEFAULT_GAP,
)
self.assertEqual(aligned_seq_a, exp_seq_a)
self.assertEqual(aligned_seq_b, exp_seq_b)
@@ -128,10 +128,10 @@ def test_encourage_mismatches(self) -> None:
aligned_seq_a, aligned_seq_b = hirschberg(
seq_a,
seq_b,
+ DEFAULT_GAP,
match_score=-10.0,
mismatch_score=100.0,
indel_score=-1.0,
- gap=DEFAULT_GAP,
)
self.assertEqual(aligned_seq_a, exp_seq_a)
self.assertEqual(aligned_seq_b, exp_seq_b)
@@ -146,12 +146,12 @@ def test_one_empty(self) -> None:
# Should work in either configuration
with self.subTest(msg="AB"):
- aligned_seq_a, aligned_seq_b = hirschberg(nonempty, [], gap=DEFAULT_GAP)
+ aligned_seq_a, aligned_seq_b = hirschberg(nonempty, [], DEFAULT_GAP)
self.assertEqual(aligned_seq_a, nonempty_aligned)
self.assertEqual(aligned_seq_b, empty_aligned)
with self.subTest(msg="BA"):
- aligned_seq_a, aligned_seq_b = hirschberg([], nonempty, gap=DEFAULT_GAP)
+ aligned_seq_a, aligned_seq_b = hirschberg([], nonempty, DEFAULT_GAP)
self.assertEqual(aligned_seq_a, empty_aligned)
self.assertEqual(aligned_seq_b, nonempty_aligned)
@@ -160,7 +160,7 @@ def test_invalid_gap(self) -> None:
for gap in ["A", "B", "C"]:
with self.subTest(gap=gap):
with self.assertRaises(ValueError):
- hirschberg(["A", "B", "D"], ["A", "C", "D"], gap=gap)
+ hirschberg(["A", "B", "D"], ["A", "C", "D"], gap)
def test_exhaust_sequence(self) -> None:
# Test that exhausting one sequence early still yields correct results
@@ -174,8 +174,8 @@ def test_exhaust_sequence(self) -> None:
aligned_seq_a, aligned_seq_b = hirschberg(
large,
small,
+ DEFAULT_GAP,
indel_score=0.0, # Don't punish gaps
- gap=DEFAULT_GAP,
)
self.assertEqual(aligned_seq_a, large_aligned)
self.assertEqual(aligned_seq_b, small_aligned)
@@ -184,8 +184,8 @@ def test_exhaust_sequence(self) -> None:
aligned_seq_a, aligned_seq_b = hirschberg(
small,
large,
+ DEFAULT_GAP,
indel_score=0.0, # Don't punish gaps
- gap=DEFAULT_GAP,
)
self.assertEqual(aligned_seq_a, small_aligned)
self.assertEqual(aligned_seq_b, large_aligned)
@@ -200,10 +200,10 @@ def test_encourage_matches(self) -> None:
aligned_seq_a, aligned_seq_b = hirschberg(
seq_a,
seq_b,
+ DEFAULT_GAP,
match_score=100.0,
mismatch_score=-1.0,
indel_score=-10.0,
- gap=DEFAULT_GAP,
)
self.assertEqual(aligned_seq_a, exp_seq_a)
self.assertEqual(aligned_seq_b, exp_seq_b)
@@ -216,10 +216,10 @@ def test_encourage_matches(self) -> None:
aligned_seq_a, aligned_seq_b = hirschberg(
seq_a,
seq_b,
+ DEFAULT_GAP,
match_score=100.0,
mismatch_score=-10.0,
indel_score=-1.0,
- gap=DEFAULT_GAP,
)
self.assertEqual(aligned_seq_a, exp_seq_a)
self.assertEqual(aligned_seq_b, exp_seq_b)
@@ -235,10 +235,10 @@ def test_normal_needleman_wunsch(self) -> None:
aligned_seq_a, aligned_seq_b = hirschberg(
seq_a,
seq_b,
+ DEFAULT_GAP,
match_score=1.0,
mismatch_score=-1.0,
indel_score=-1.0,
- gap=DEFAULT_GAP,
)
self.assertEqual(aligned_seq_a, exp_seq_a)
self.assertEqual(aligned_seq_b, exp_seq_b)
diff --git a/tests/unit/test_needleman_wunsch.py b/tests/unit/test_needleman_wunsch.py
index d043c83..4ac3eee 100644
--- a/tests/unit/test_needleman_wunsch.py
+++ b/tests/unit/test_needleman_wunsch.py
@@ -10,7 +10,7 @@
class TestNeedlemanWunsch(unittest.TestCase):
def test_empty(self) -> None:
- aligned_seq_a, aligned_seq_b = needleman_wunsch([], [])
+ aligned_seq_a, aligned_seq_b = needleman_wunsch([], [], DEFAULT_GAP)
self.assertEqual(len(aligned_seq_a), 0)
self.assertEqual(len(aligned_seq_b), 0)
@@ -22,12 +22,12 @@ def test_one_empty(self) -> None:
# Should work in either configuration
with self.subTest(msg="AB"):
- aligned_seq_a, aligned_seq_b = needleman_wunsch(nonempty, [], gap=DEFAULT_GAP)
+ aligned_seq_a, aligned_seq_b = needleman_wunsch(nonempty, [], DEFAULT_GAP)
self.assertEqual(aligned_seq_a, nonempty_aligned)
self.assertEqual(aligned_seq_b, empty_aligned)
with self.subTest(msg="BA"):
- aligned_seq_a, aligned_seq_b = needleman_wunsch([], nonempty, gap=DEFAULT_GAP)
+ aligned_seq_a, aligned_seq_b = needleman_wunsch([], nonempty, DEFAULT_GAP)
self.assertEqual(aligned_seq_a, empty_aligned)
self.assertEqual(aligned_seq_b, nonempty_aligned)
@@ -36,7 +36,7 @@ def test_invalid_gap(self) -> None:
for gap in ["A", "B", "C"]:
with self.subTest(gap=gap):
with self.assertRaises(ValueError):
- needleman_wunsch(["A", "B", "D"], ["A", "C", "D"], gap=gap)
+ needleman_wunsch(["A", "B", "D"], ["A", "C", "D"], gap)
def test_words(self) -> None:
# Test that words also work (i.e., verify that the Python logic to map into and out of
@@ -69,8 +69,8 @@ def test_words(self) -> None:
seq_a_aligned, seq_b_aligned = needleman_wunsch(
seq_a,
seq_b,
+ DEFAULT_GAP,
indel_score=0.0, # Don't punish gaps
- gap=DEFAULT_GAP,
)
self.assertEqual(seq_a_aligned, exp_seq_a_aligned)
self.assertEqual(seq_b_aligned, exp_seq_b_aligned)
@@ -87,8 +87,8 @@ def test_exhaust_sequence(self) -> None:
aligned_seq_a, aligned_seq_b = needleman_wunsch(
large,
small,
+ DEFAULT_GAP,
indel_score=0.0, # Don't punish gaps
- gap=DEFAULT_GAP,
)
self.assertEqual(aligned_seq_a, large_aligned)
self.assertEqual(aligned_seq_b, small_aligned)
@@ -97,8 +97,8 @@ def test_exhaust_sequence(self) -> None:
aligned_seq_a, aligned_seq_b = needleman_wunsch(
small,
large,
+ DEFAULT_GAP,
indel_score=0.0, # Don't punish gaps
- gap=DEFAULT_GAP,
)
self.assertEqual(aligned_seq_a, small_aligned)
self.assertEqual(aligned_seq_b, large_aligned)
@@ -113,10 +113,10 @@ def test_encourage_matches(self) -> None:
aligned_seq_a, aligned_seq_b = needleman_wunsch(
seq_a,
seq_b,
+ DEFAULT_GAP,
match_score=100.0,
mismatch_score=-1.0,
indel_score=-10.0,
- gap=DEFAULT_GAP,
)
self.assertEqual(aligned_seq_a, exp_seq_a)
self.assertEqual(aligned_seq_b, exp_seq_b)
@@ -129,10 +129,10 @@ def test_encourage_matches(self) -> None:
aligned_seq_a, aligned_seq_b = needleman_wunsch(
seq_a,
seq_b,
+ DEFAULT_GAP,
match_score=100.0,
mismatch_score=-10.0,
indel_score=-1.0,
- gap=DEFAULT_GAP,
)
self.assertEqual(aligned_seq_a, exp_seq_a)
self.assertEqual(aligned_seq_b, exp_seq_b)
@@ -147,10 +147,10 @@ def test_encourage_mismatches(self) -> None:
aligned_seq_a, aligned_seq_b = needleman_wunsch(
seq_a,
seq_b,
+ DEFAULT_GAP,
match_score=1.0,
mismatch_score=100.0,
indel_score=-1.0,
- gap=DEFAULT_GAP,
)
self.assertEqual(aligned_seq_a, exp_seq_a)
self.assertEqual(aligned_seq_b, exp_seq_b)
@@ -163,10 +163,10 @@ def test_encourage_mismatches(self) -> None:
aligned_seq_a, aligned_seq_b = needleman_wunsch(
seq_a,
seq_b,
+ DEFAULT_GAP,
match_score=-10.0,
mismatch_score=100.0,
indel_score=-1.0,
- gap=DEFAULT_GAP,
)
self.assertEqual(aligned_seq_a, exp_seq_a)
self.assertEqual(aligned_seq_b, exp_seq_b)
@@ -183,10 +183,10 @@ def test_encourage_gaps(self) -> None:
aligned_seq_a, aligned_seq_b = needleman_wunsch(
seq_a,
seq_b,
+ DEFAULT_GAP,
match_score=1.0,
mismatch_score=-1.0,
indel_score=100.0,
- gap=DEFAULT_GAP,
)
self.assertEqual(aligned_seq_a, exp_seq_a)
self.assertEqual(aligned_seq_b, exp_seq_b)
@@ -195,10 +195,10 @@ def test_encourage_gaps(self) -> None:
aligned_seq_a, aligned_seq_b = needleman_wunsch(
seq_a,
seq_b,
+ DEFAULT_GAP,
match_score=-1.0,
mismatch_score=1.0,
indel_score=100.0,
- gap=DEFAULT_GAP,
)
self.assertEqual(aligned_seq_a, exp_seq_a)
self.assertEqual(aligned_seq_b, exp_seq_b)
@@ -214,10 +214,10 @@ def test_normal(self) -> None:
aligned_seq_a, aligned_seq_b = needleman_wunsch(
seq_a,
seq_b,
+ DEFAULT_GAP,
match_score=1.0,
mismatch_score=-1.0,
indel_score=-1.0,
- gap=DEFAULT_GAP,
)
self.assertEqual(aligned_seq_a, exp_seq_a)
self.assertEqual(aligned_seq_b, exp_seq_b)
diff --git a/tests/unit/test_needleman_wunsch_with_scores.py b/tests/unit/test_needleman_wunsch_with_scores.py
new file mode 100644
index 0000000..74f3c70
--- /dev/null
+++ b/tests/unit/test_needleman_wunsch_with_scores.py
@@ -0,0 +1,182 @@
+# Copyright 2023-present Kensho Technologies, LLC.
+from typing import Any
+import unittest
+
+from sequence_align.pairwise import needleman_wunsch_with_scores
+
+
+DEFAULT_GAP = "_"
+
+
+def match_mismatch(a: Any, b: Any) -> float:
+ """Same score as default Needleman-Wunsch."""
+ return 1.0 if a == b else -1.0
+
+
+class TestNeedlemanWunschWithScores(unittest.TestCase):
+ def test_empty(self) -> None:
+ aligned_seq_a, aligned_seq_b = needleman_wunsch_with_scores(
+ [], [], DEFAULT_GAP, match_mismatch
+ )
+ self.assertEqual(len(aligned_seq_a), 0)
+ self.assertEqual(len(aligned_seq_b), 0)
+
+ def test_one_empty(self) -> None:
+ nonempty = ["A", "B", "C"]
+ nonempty_aligned = ["A", "B", "C"]
+ empty_aligned = [DEFAULT_GAP, DEFAULT_GAP, DEFAULT_GAP]
+
+ with self.subTest(msg="AB"):
+ aligned_seq_a, aligned_seq_b = needleman_wunsch_with_scores(
+ nonempty, [], DEFAULT_GAP, match_mismatch
+ )
+ self.assertEqual(aligned_seq_a, nonempty_aligned)
+ self.assertEqual(aligned_seq_b, empty_aligned)
+
+ with self.subTest(msg="BA"):
+ aligned_seq_a, aligned_seq_b = needleman_wunsch_with_scores(
+ [], nonempty, DEFAULT_GAP, match_mismatch
+ )
+ self.assertEqual(aligned_seq_a, empty_aligned)
+ self.assertEqual(aligned_seq_b, nonempty_aligned)
+
+ def test_invalid_gap(self) -> None:
+ for gap in ["A", "B", "C"]:
+ with self.subTest(gap=gap):
+ with self.assertRaises(ValueError):
+ needleman_wunsch_with_scores(
+ ["A", "B", "D"], ["A", "C", "D"], gap, match_mismatch
+ )
+
+ def test_identity_score_matches_standard_nw(self) -> None:
+ """When score_fn returns match_score/mismatch_score, results should match standard NW."""
+ seq_a = ["G", "A", "T", "T", "A", "C", "A"]
+ seq_b = ["G", "C", "A", "T", "G", "C", "G"]
+
+ indel_score = -1.0
+
+ exp_seq_a = ["G", DEFAULT_GAP, "A", "T", "T", "A", "C", "A"]
+ exp_seq_b = ["G", "C", "A", DEFAULT_GAP, "T", "G", "C", "G"]
+
+ aligned_seq_a, aligned_seq_b = needleman_wunsch_with_scores(
+ seq_a, seq_b, DEFAULT_GAP, match_mismatch, indel_score=indel_score
+ )
+ self.assertEqual(aligned_seq_a, exp_seq_a)
+ self.assertEqual(aligned_seq_b, exp_seq_b)
+
+ def test_custom_continuous_scores(self) -> None:
+ """Test with continuous (non-binary) scores to verify the matrix-based approach."""
+ # Elements are numbers-as-strings; score by numeric proximity
+ seq_a = ["1", "5", "9"]
+ seq_b = ["2", "6", "8"]
+
+ def numeric_proximity(a: str, b: str) -> float:
+ return -abs(int(a) - int(b))
+
+ aligned_seq_a, aligned_seq_b = needleman_wunsch_with_scores(
+ seq_a, seq_b, DEFAULT_GAP, numeric_proximity, indel_score=-5.0
+ )
+ # Proximity: 1-2=-1, 5-6=-1, 9-8=-1 -> total=-3 (matched)
+ # vs any gap arrangement which costs -5 per gap
+ # So matching 1:1 is optimal
+ self.assertEqual(aligned_seq_a, ["1", "5", "9"])
+ self.assertEqual(aligned_seq_b, ["2", "6", "8"])
+
+ def test_scores_prefer_gaps_over_bad_match(self) -> None:
+ """When the score function returns very negative values, gaps should be preferred."""
+ seq_a = ["A", "B", "C"]
+ seq_b = ["X", "B", "Y"]
+
+ def score_fn(a: str, b: str) -> float:
+ if a == b:
+ return 10.0
+ return -100.0 # Very bad mismatch
+
+ aligned_seq_a, aligned_seq_b = needleman_wunsch_with_scores(
+ seq_a, seq_b, DEFAULT_GAP, score_fn, indel_score=-1.0
+ )
+ # Should match B:B and gap the rest rather than force A:X or C:Y mismatches.
+ # The algorithm's tie-breaking (diagonal > left > up) produces this 5-position
+ # alignment which also scores optimally: -1 + -1 + 10 + -1 + -1 = 6.
+ self.assertEqual(aligned_seq_a, ["A", DEFAULT_GAP, "B", "C", DEFAULT_GAP])
+ self.assertEqual(aligned_seq_b, [DEFAULT_GAP, "X", "B", DEFAULT_GAP, "Y"])
+
+ def test_asymmetric_scores(self) -> None:
+ """Test that asymmetric score functions are handled correctly."""
+ seq_a = ["A", "B"]
+ seq_b = ["B", "A"]
+
+ def asymmetric_score(a: str, b: str) -> float:
+ if a == "A" and b == "B":
+ return 5.0 # A aligning to B is great
+ if a == "B" and b == "A":
+ return -5.0 # B aligning to A is terrible
+ if a == b:
+ return 1.0
+ return -1.0
+
+ aligned_seq_a, aligned_seq_b = needleman_wunsch_with_scores(
+ seq_a, seq_b, DEFAULT_GAP, asymmetric_score, indel_score=-2.0
+ )
+ # A->B scores 5.0, B->A scores -5.0
+ # Best: align A:B (score 5) + gap B + gap A = 5 + (-2) + (-2) = 1
+ # vs: gap A + B:B (1) + gap A = -2 + 1 + -2 = -3
+ # vs: A:B (5) + B:A (-5) = 0
+ # So A:B + gaps is best
+ self.assertEqual(aligned_seq_a, ["A", "B", DEFAULT_GAP])
+ self.assertEqual(aligned_seq_b, ["B", DEFAULT_GAP, "A"])
+
+ def test_non_string_elements(self) -> None:
+ """Test that non-string sequences work (the function is generic over T)."""
+ seq_a = [1, 2, 3]
+ seq_b = [2, 3, 4]
+
+ def score_fn(a: int, b: int) -> float:
+ return 1.0 if a == b else -1.0
+
+ aligned_seq_a, aligned_seq_b = needleman_wunsch_with_scores(
+ seq_a, seq_b, 0, score_fn, indel_score=-1.0
+ )
+ # Should align 2:2 and 3:3
+ self.assertEqual(aligned_seq_a, [1, 2, 3, 0])
+ self.assertEqual(aligned_seq_b, [0, 2, 3, 4])
+
+ def test_words_with_custom_score(self) -> None:
+ """Test word alignment with a custom similarity function."""
+ seq_a = ["hello", "world", "foo"]
+ seq_b = ["hallo", "welt", "baz", "foo"]
+
+ def char_overlap_score(a: str, b: str) -> float:
+ if a == b:
+ return 2.0
+ shared = len(set(a) & set(b))
+ total = len(set(a) | set(b))
+ return (2.0 * shared / total) - 1.0 if total > 0 else -1.0
+
+ aligned_seq_a, aligned_seq_b = needleman_wunsch_with_scores(
+ seq_a, seq_b, DEFAULT_GAP, char_overlap_score, indel_score=-1.0
+ )
+ # "hello" and "hallo" share {h, l, o} out of {h, e, a, l, o} -> 6/5 - 1 = 0.2
+ # "world" and "welt" share {w, l} out of {w, o, r, l, d, e, t} -> 4/7 - 1 ~ -0.43
+ # "foo" and "foo" -> 2.0
+ # Best alignment should pair hello:hallo, world:welt, gap:baz, foo:foo
+ self.assertEqual(aligned_seq_a, ["hello", "world", DEFAULT_GAP, "foo"])
+ self.assertEqual(aligned_seq_b, ["hallo", "welt", "baz", "foo"])
+
+ def test_exhaust_sequence(self) -> None:
+ large = ["A", "B", "C", "D"]
+ small = ["C", "D"]
+
+ with self.subTest(msg="AB"):
+ aligned_seq_a, aligned_seq_b = needleman_wunsch_with_scores(
+ large, small, DEFAULT_GAP, match_mismatch, indel_score=0.0
+ )
+ self.assertEqual(aligned_seq_a, ["A", "B", "C", "D"])
+ self.assertEqual(aligned_seq_b, [DEFAULT_GAP, DEFAULT_GAP, "C", "D"])
+
+ with self.subTest(msg="BA"):
+ aligned_seq_a, aligned_seq_b = needleman_wunsch_with_scores(
+ small, large, DEFAULT_GAP, match_mismatch, indel_score=0.0
+ )
+ self.assertEqual(aligned_seq_a, [DEFAULT_GAP, DEFAULT_GAP, "C", "D"])
+ self.assertEqual(aligned_seq_b, ["A", "B", "C", "D"])