十进制计数是使用 10 作为基数,那么二进制就是使用 2 作为基数,类比过来,二进制的数位就是 2^n 的形式。如果需要将这个数字转化为人们易于理解的十进制,我们就可以这样来计算:
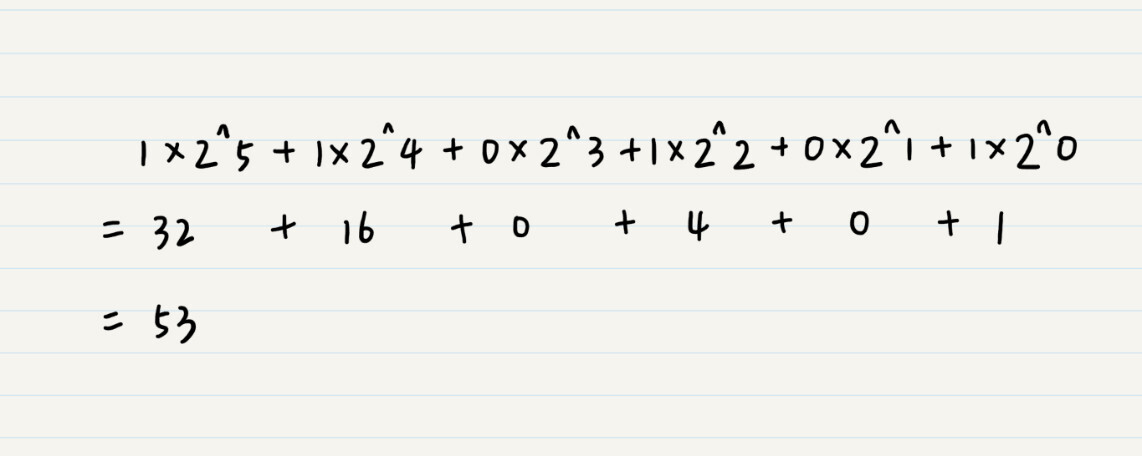
/**
* @Description: 十进制转换成二进制
* @param decimalSource
* @return String
*/
public static String decimalToBinary(int decimalSource) {
BigInteger bi = new BigInteger(String.valueOf(decimalSource)); // 转换成 BigInteger 类型,默认是十进制
return bi.toString(2); // 参数 2 指定的是转化成二进制
}
/**
* @Description: 二进制转换成十进制
* @param binarySource
* @return int
*/
public static int binaryToDecimal(String binarySource) {
BigInteger bi = new BigInteger(binarySource, 2); // 转换为 BigInteger 类型,参数 2 指定的是二进制
return Integer.parseInt(bi.toString()); // 默认转换成十进制
}
计算机使用二进制和现代计算机系统的硬件实现有关。组成计算机系统的逻辑电路通常只有两个状态,即开关的接通与断开。 断开的状态我们用“0”来表示,接通的状态用“1”来表示。由于每位数据只有断开与接通两种状态,所以即便系统受到一定程度的干扰时,它仍然能够可靠地分辨出数字是“0”还是“1”。因此,在具体的系统实现中,二进制的数据表达具有抗干扰能力强、可靠性高的优点。
-
左移右移 二进制 110101 向左移一位,就是在末尾添加一位 0,因此 110101 就变成了 1101010。请注意,这里讨论的是数字没有溢出的情况。 所谓数字溢出,就是二进制数的位数超过了系统所指定的位数。目前主流的系统都支持至少 32 位的整型数字,而 1101010 远未超过 32 位,所以不会溢出。如果进行左移操作的二进制已经超出了 32 位,左移后数字就会溢出,需要将溢出的位数去除。 二进制左移一位,其实就是将数字翻倍。 二进制右移一位,就是将数字除以 2 并求整数商的操作。 左移位是 <<, java/python 中逻辑右移>>>和算术右移>>
逻辑右移 1 位,左边补 0 即可。算术右移时保持符号位不变,除符号位之外的右移一位并补符号位 1。补的 1 仍然在符号位之后。 c/c++中逻辑右移和算数右移共享同一个运算符 >>如果运算数类型是 unsigned,则采用逻辑右移;而是 signed,则采用算数右移。如果你针对 unsigned 类型的数据使用算数右移,或者针对 signed 类型的数据使用逻辑右移,那么你首先需要进行类型的转换。
-
按位“或”
|、“与”&、“异或”^
-
验证奇偶数
x & 1 == 0 时为偶数 ///由于1的二进制前n-1位都0,故结果是最后一位按最后与的结果,x的最后一位为1(奇数)才为真 -
交换两个数字(利用异或)
利用异或,相同为0,不同为1 x = x ^ y y = x ^ y //代入第一步 y = x ^ y = x ^ y ^ y = x ^ (y ^ y) = x ^ 0 = x x = x ^ y //代入第一步与第二步的结果 x = x^y^x = y ^ 0 = yx = x(原来)^y(原来) //推导y = x(原来) = x(原来)^0 = x(原来)^y(原来)^y(原来) = x^y(原来) //y需要== x时 推导的结果为 y = x(新)^y(原来) //此时y已经等于原来的x //推导x = y(原来) = y(原来)^0 = y(原来)^x(新)^x(新) = y(新)^x(新) //x需要= y时 x = x(新)^y(新) -
集合操作 取交集、并集
如两个集合{1,3,8}和{4,8},先把两个集合转两个8位的二进制数,其中{1,3,8}代表第1、3、8位为1,即
10000101与10001000,按位与得1000 0000即交集{8},按位或得10001101即并集{1,3,4,8}
符号位:符号位是有符号二进制数中的最高位,需要用它来表示负数 如果有符号数,当符号位为0,表示正数,当符号位为1,表示负数 如果无符号数,最高位不是符号位,只表示正数
负数对计算机中的二进制减法至关重要。3-2可以看作是 3+(-2)
溢出,超出上限,叫上溢出,超出下限叫下溢出 上溢出之后,又从下限开始,最大的数值加1,变成最小的数,周而复始,即余数和取模的概念

取模的除数:$2^{n-1}-1-(-2^{n-1}) +1 = (2^n -1) +1$(不直接写成2^n,2^n是n+1位,超出了n位能表示的范围,无符号能表示2^n-1)
设i-j,(其中j为正数),i-j加上取模的除数形成溢出刚好等于我们要得结果,其实由于溢出所以还是等于其本身 i-j =(i-j)+(2^n-1)+1 = i+(2^n-1-j+1) ,其中2^n-1-j即是负数j的反码,2^n-1-j +1即为补码

例j=2, 2^n-1 - ,即为11…111 - 00…010 = 11..101,刚好是2的补码 因此i-j =(i-j)+(2^n-1)+1 = i+(2^n-1-j+1) = i + j的补码
**原码:**二进制的原始表示,如+2的原码为000..010 ,-2的原码为100...010
不能直接用负数的原码来进行计算,应该怎么办?
计算机可以通过补码正确的运算二进制减法
余数总是在一个固定的范围内,取余操作本身就是个哈希函数 同余定理。简单来说,就是两个整数 a 和 b,如果它们除以正整数 m 得到的余数相等,我们就可以说 a 和 b 对于模 m 同余。同余定理其实就是用来分类的
哈希简单来说,它就是将任意长度的输入,通过哈希算法,压缩为某一固定长度的输出。
如何快速读写 100 万条数据记录?(没有能够容纳 100 万条记录的连续地址空间)
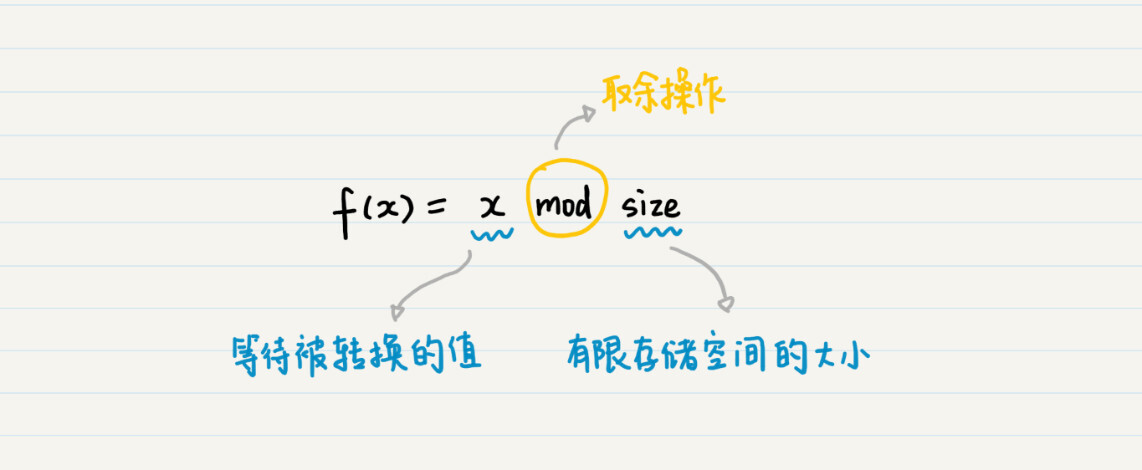
其中x 表示等待被转换的数值,而 size 表示有限存储空间的大小,mod 表示取余操作。通过余数,你就能将任何数值,转换为有限范围内的一个数值,然后根据这个新的数值,来确定将数据存放在何处。
假设有两条记录,它们的记录标号分别是 1 和 101。我们把这些模 100 之后余数都是 1 的,存放到第 1 个可用空间里。以此类推,将余数为 2 的 2、102、202 等,存放到第 2 个可用空间,将 100、200、300 等存放到第 100 个可用空间里。 这样,我们就可以根据求余的快速数字变化,对数据进行分组,并把它们存放到不同的地址空间里。而求余操作本身非常简单,因此几乎不会增加寻址时间。
还可以进行优化f(x)= (x + max) mod size,max为随机数,增加数列的随机程序
**迭代法,简单来说,其实就是不断地用旧的变量值,递推计算新的变量值。**迭代法的思想,很容易通过计算机语言中的循环语言来实现
应用场景
- 求数值的精确或者近似解。典型的方法包括二分法(Bisection method)和牛顿迭代法(Newton’s method)。 迭代可以帮助我们进行无穷次地逼近,求得方程的精确或者近似解。
- **在一定范围内查找目标值。**典型的方法包括二分查找。
- 机器学习算法中的迭代。相关的算法或者模型有很多,比如 K- 均值算法(K-means clustering)、PageRank 的马尔科夫链(Markov chain)、梯度下降法(Gradient descent)等等。迭代法之所以在机器学习中有广泛的应用,是因为很多时候机器学习的过程,就是根据已知的数据和一定的假设,求一个局部最优解。而迭代法可以帮助学习算法逐步搜索,直至发现这种解。
-
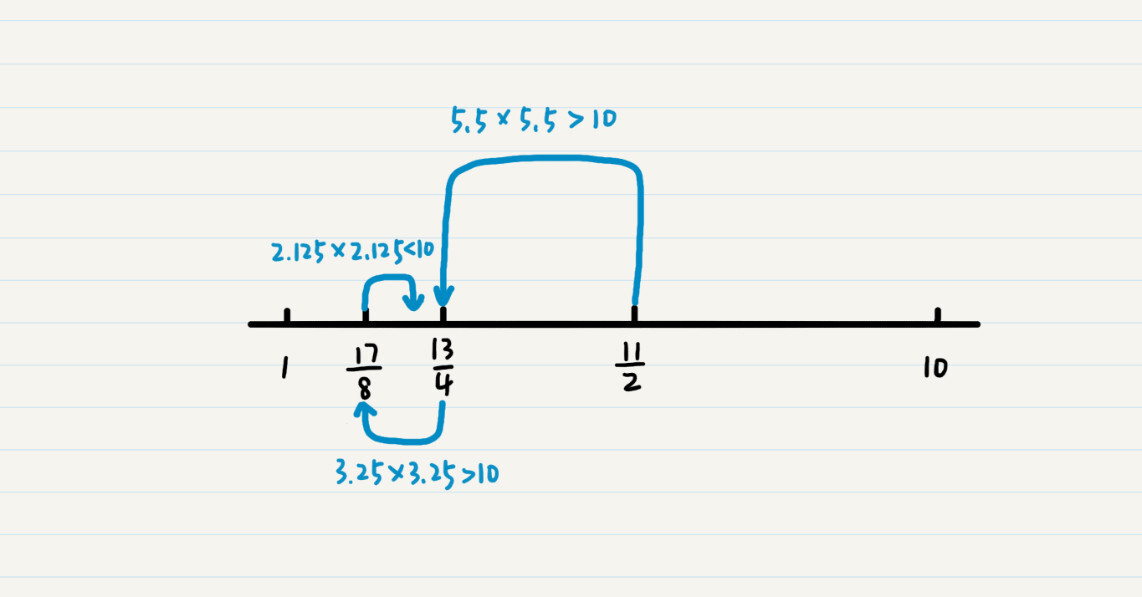
比如说,我们想计算某个给定正整数 n(n>1)的平方根,如果不使用编程语言自带的函数,你会如何来实现呢?
注意绝对值
/** * 求1-n的平方根 * @param n * @return */ public static double hlSqrt(int n) { double low = 1; double high = n; double mid = low + (high - low)/2; double deltaThreshold = 0.001; // 注意点,这里的绝对值容易忘 while (Math.abs(mid * mid - n ) > deltaThreshold) { if (mid * mid > n) { high = mid; } else if (mid *mid < n) { low = mid; } else { return mid; } mid = low + (high - low)/2; // System.out.println(mid); } return mid; }还可以这么做
public static double getSqureRoot(int n, double deltaThreshold, int maxTry) { }1.精确度由外面传入,避免耗费大量时间, 2.传入最大尝试次数,出于良好习惯,避免死循环
-
二分查找,针对有序数组(int,string,只要有序都可以)
//注意点1.low <= high,(1个元素,最容易想) 2.low = mid +1; 下标+/- 1,3.如果用右移操作符,记得括号,4.value没有判空,做为传入参数比较好 public static int biniarySearch(String[] list,String value) { if (list == null) { return -1; } int low = 0; int high = list.length -1; while (low <= high) { int mid = low + ((high - low)>>1); if (value == list[mid]) { return mid; //value没有判空,做为传入参数比较好 } else if (list[mid].compareTo(value) < 1) { low = mid + 1; } else { high = mid -1; } } return -1; }
数学归纳法的一般步骤是这样的: 1.证明基本情况(通常是 n=1n=1 的时候)是否成立; 2.假设 n=k−1n=k−1 成立,再证明 n=kn=k 也是成立的(kk 为任意大于 11 的自然数)。
和使用迭代法的计算相比,数学归纳法最大的特点就在于“归纳”二字。它已经总结出了规律。只要我们能够证明这个规律是正确的,就没有必要进行逐步的推算,可以节省很多时间和资源。
数学归纳法在理论上证明了命题是否成立,而无需迭代那样反复计算,因此可以帮助我们节约大量的资源,并大幅地提升系统的性能。 数学归纳法实现的运行时间几乎为 0。不过,数学归纳法需要我们能做出合理的命题假设,然后才能进行证明。虽然很多时候要做这点比较难,确实也没什么捷径。你就是要多做题,多去看别人是怎么解题的,自己去积累经验。 最后,我通过函数的递归调用,模拟了数学归纳法的证明过程。如果你细心的话,会发现递归的函数值返回实现了从 k=1开始到 k=n的迭代
既然递归的函数值返回过程和基于循环的迭代法一致,我们直接用迭代法不就好了,为什么还要用递归的数学思想和编程方法呢?这是因为,在某些场景下,递归的解法比基于循环的迭代法更容易实现。
1、2、5、10元组成总共为10元的组合有多少种?下面有重复
//有个问题,有重复的数据
static int[] compositions = {1,2,5,10};
public static int getAllCompositionSolutions(int totoal, LinkedList<Integer> list) {
if (totoal == 0) {
System.out.println(list);
return 1;
} else if (totoal < 0) {
return 0;
}
int sum = 0;
for (int i = 0; i < compositions.length; i++) {
//
LinkedList<Integer> newList = new LinkedList<>(list);
newList.add(compositions[i]);
sum += getAllCompositionSolutions(totoal - compositions[i] , newList);
}
return sum;
}
归并排序(merge sort) 核心:就是把两个有序的数列合并起来,形成一个更大的有序数列。
public static List<Comparable> mergeSort(List<Comparable> list) {
System.out.println(list);
if (list == null) {
return null;
}
if (list.size() <= 1) {
return list;
}
int left = 0;
int right = list.size();
int mid = left + ((right - left)>>1);
System.out.println("left:");
List<Comparable> leftList = mergeSort(list.subList(left, mid));
List<Comparable> rightList;
if (mid > right) {
rightList = new LinkedList<>();
} else {
System.out.println("right:");
rightList = mergeSort(list.subList(mid, right));
}
int index = leftList.size() < rightList.size() ? leftList.size():rightList.size();
List<Comparable> result = new LinkedList<>();
int i = 0,j = 0;
while (i<leftList.size() && j<rightList.size()) {
if (leftList.get(i).compareTo(rightList.get(i)) < 0) {
result.add(leftList.get(i));
i ++;
} else {
result.add(rightList.get(j));
j++;
}
}
for (; i < leftList.size(); i++) {
result.add(leftList.get(i));
}
for (; j < rightList.size(); j++) {
result.add(rightList.get(j));
}
System.out.println("result:"+result);
return result;
}
步骤理解
[1, 5, 2, 3, 4, 8, 9, 6, 7, 29, 43, 23]
left: [1, 5, 2, 3, 4, 8]
left: [1, 5, 2]
left: [1]
right: [5, 2]
left: [5]
right: [2]
result:[2, 5]
result:[1, 2, 5]
right: [3, 4, 8]
left: [3]
right: [4, 8]
left: [4]
right: [8]
result:[4, 8]
result:[3, 4, 8]
result:[1, 2, 5, 3, 4, 8]
right: [9, 6, 7, 29, 43, 23]
left: [9, 6, 7]
left: [9]
right: [6, 7]
left: [6]
right: [7]
result:[6, 7]
result:[6, 7, 9]
right: [29, 43, 23]
left: [29]
right: [43, 23]
left: [43]
right: [23]
result:[23, 43]
result:[23, 43, 29]
result:[6, 7, 9, 23, 43, 29]
result:[1, 2, 5, 3, 4, 8, 6, 7, 9, 23, 43, 29]
[1, 2, 5, 3, 4, 8, 6, 7, 9, 23, 43, 29]
分布式系统中的分治思想
数组很大(如1024GB)时如何处理?

上图1、2、3没有被安排排序工作,可以进一步优化性能

转化为类似MapReduce的架构

从 n 个不同的元素中取出 m(1≤m≤n)个不同的元素,按照一定的顺序排成一列,这个过程就叫排列(Permutation)。当 m=n 这种特殊情况出现的时候,比如说,在田忌赛马的故事中,田忌的三匹马必须全部出战,这就是全排列(All Permutation)。
如果选择出的这 m 个元素可以有重复的,这样的排列就是为重复排列(Permutation with Repetition),否则就是不重复排列(Permutation without Repetition)。
- 对于 n 个元素的全排列,所有可能的排列数量就是 nx(n-1)x(n-2)x…x2x1,也就是 n!;
- 对于 n 个元素里取出 m(0<m≤n) 个元素的不重复排列数量是 nx(n-1)x(n-2)x…x(n - m + 1),也就是 n!/(n-m)!。
// O(n!) 全排列
public static void permutate(ArrayList<String> restArray, ArrayList<String> result) {
if ( restArray == null || restArray.size() == 0) {
System.out.println(result);
return;
}
for (int i = 0; i < restArray.size(); i++) {
ArrayList<String> newRestArray = (ArrayList<String>) restArray.clone();
String value = newRestArray.remove(i);
ArrayList<String> newResult = (ArrayList<String>) result.clone();
newResult.add(value);
permutate(newRestArray, newResult);
}
}
[A, B, C]
[A, C, B]
[B, A, C]
[B, C, A]
[C, A, B]
[C, B, A]
组合是指,从 n 个不同元素中取出 m(1≤m≤n)个不同的元素。 对于所有 m 取值的组合之全集合,我们可以叫作全组合(All Combination)。例如对于集合{1, 2, 3}而言,全组合就是{空集, {1}, {2}, {3}, {1, 2}, {1,3} {2, 3}, {1, 2, 3}}。
- n 个元素里取出 m 个的组合,可能性数量就是 n 个里取 m 个的排列数量,除以 m 个全排列的数量,也就是 (n! / (n-m)!) / m!。
- 对于全组合而言,可能性为 2^n 种。例如,当 n=3 的时候,全组合包括了 8 种情况。
public static void combine(ArrayList<String> restArray, ArrayList<String> result,int m) {
if ( result.size() == m) {
System.out.println(result);
return;
}
for (int i = 0; i < restArray.size(); i++) {
ArrayList<String> newResult = (ArrayList<String>) result.clone();
newResult.add(restArray.get(i));
//选完前面的之后直接从后面开始选
ArrayList<String> newRestArray = new BakedArrayList(restArray.subList(i+1, restArray.size()));
combine(newRestArray, newResult, m);
}
}
A、B、C、D中选2个
[A, B]
[A, C]
[A, D]
[B, C]
[B, D]
[C, D]
我们可以通过不断分解问题,将复杂的任务简化为最基本的小问题,比如基于递归实现的归并排序、排列和组合等。不过有时候,我们并不用处理所有可能的情况,只要找到满足条件的最优解就行了。在这种情况下,我们需要在各种可能的局部解中,找出那些可能达到最优的局部解,而放弃其他的局部解。这个寻找最优解的过程其实就是动态规划。
动态规划需要通过子问题的最优解,推导出最终问题的最优解,因此这种方法特别注重子问题之间的转移关系。我们通常把这些子问题之间的转移称为状态转移,并把用于刻画这些状态转移的表达式称为状态转移方程。很显然,找到合适的状态转移方程,是动态规划的关键。
搜索下拉提示和关键词纠错,这两个功能其实就是查询推荐。查询推荐的核心思想其实就是,对于用户的输入,查找相似的关键词并进行返回。而测量拉丁文的文本相似度,最常用的指标是编辑距离(Edit Distance)。
由一个字符串转成另一个字符串所需的最少编辑操作次数,我们就叫作编辑距离。这个概念是俄罗斯科学家莱文斯坦提出来的,所以我们也把编辑距离称作莱文斯坦距离(Levenshtein distance)。很显然,编辑距离越小,说明这两个字符串越相似,可以互相作为查询推荐。编辑操作有这三种:把一个字符替换成另一个字符;插入一个字符;删除一个字符。


我们假设字符数组 A[] 和 B[] 分别表示字符串 A 和 B,A[i] 表示字符串 A 中第 i 个位置的字符,B[i] 表示字符串 B 中第 i 个位置的字符。二维数组 d[,] 表示刚刚用于推导的二维表格,而 d[i,j] 表示这张表格中第 i 行、第 j 列求得的最终编辑距离。函数 r(i, j) 表示替换时产生的编辑距离。如果 A[i] 和 B[j] 相同,函数的返回值为 0,否则返回值为 1
- 如果i==0,j==0,则d[i,j]=0
- 如果i==0,j>0,则d[i,j] = j
- 如果j==0,i>0,则d[i,j] = i;
- 如果i > 0,j>0, 则d[i,j] = min( **d[i-1,j]+1 ** , **d[i,j-1]+1 ** , **d[i-1,j-1]+r(i,j) ** ) 。状态转移方程,可以求出数组中的每一个值
//O(m*n)
public static int getStrDistance(String a,String b ) {
if (a == null || b == null) return -1;
int[][] d = new int[a.length()+1][b.length()+1];
for (int i = 0; i <= a.length(); i++) {
d[i][0] = i;
}
for (int j = 0; j < b.length(); j++) {
d[0][j] = j;
}
for (int i = 0; i < a.length(); i++) {
for (int j = 0; j < b.length(); j++) {
//编辑距离
int r = 0;
if (a.charAt(i) != b.charAt(j)) {
r = 1;
}
int first_append = d[i][j+1] + 1;
int second_append = d[i+1][j] + 1;
int min = Math.min(first_append, second_append);
min = Math.min(min, r + d[i][j]);
d[i+1][j+1] = min;
}
}
for (int i = 0; i < a.length(); i++) {
for (int j = 0; j < b.length(); j++) {
System.out.print(d[i][j] + " ");
}
System.out.println();
}
return d[a.length()][b.length()];
}
钱币组合问题变种: 给定总金额和可能的钱币面额,能否找出钱币数量最少的奖赏方式?

这题和青蛙跳台阶好一样
Trie
所谓树的深度优先搜索,其实就是从树中的某个结点出发,沿着和这个结点相连的边向前走,找到下一个结点,然后以这种方式不断地发现新的结点和边,一直搜索下去,直到访问了所有和出发点连通的点、或者满足某个条件后停止。
如果到了某个点,发现和这个点直接相连的所有点都已经被访问过,那么就回退到在这个点的父结点,继续查看是否有新的点可以访问;如果没有就继续回退,一直到出发点。由于单棵树中所有的结点都是连通的,所以通过深度优先的策略可以遍历树中所有的结点,因此也被称为深度优先遍历。

其中,结点上的数字表示结点的 ID,而虚线表示遍历前进的方向,结点边上的数字表示该结点在深度优先搜索中被访问的顺序。在深度优先的策略下,我们从点 110 出发,然后发现和 110 相连的点 123,访问 123 后继续发现和 123 相连的点 162,再往后发现 162 没有出度,因此回退到 123,查看和 123 相连的另一个点 587,根据 587 的出度继续往前推进,如此类推。
深度优先搜索 使用stack,先入栈根结点,再pop,然后入栈pop这个结点的所有子结点,再pop,入栈pop这个结点的所有子结点直到没有子结点
我来总结一下,其实深度优先搜索的核心思想,就是按照当前的通路,不断地向前进,当遇到走不通的时候就回退到上一个结点,通过另一个新的边进行尝试。如果这一个点所有的方向都走不通的时候,就继续回退。这样一次一次循环下去,直到到达目标结点。树中的每个结点,既可以表示某个子问题和它所对应的抽象状态,也可以表示某个数据结构中一部分具体的值。
总结
如果一个问题可以被迭代法解决,而且是有关数值计算的,那你就看看是否可以假设命题,并优先考虑使用数学归纳法来证明; 如果需要借助计算机,那么优先考虑是否可以使用循环来实现。如果问题本身过于复杂,再考虑函数的嵌套调用,是否可以通过递归将问题逐级简化; 如果数据量过大,可以考虑采用分治思想的分布式系统来处理。
广度优先搜索(Breadth First Search),也叫宽度优先搜索,是指从图中的某个结点出发,沿着和这个点相连的边向前走,去寻找和这个点距离为 1 的所有其他点。只有当和起始点距离为 1 的所有点都被搜索完毕,才开始搜索和起始点距离为 2 的点。当所有和起始点距离为 2 的点都被搜索完了,才开始搜索和起始点距离为 3 的点,如此类推。
使用队列queue,先入队root节点,然后dequeue,再enquue当前节点的所有子结点,重复dequeue,enqueue其所有子结点
双向广度优先搜索 高效地求两个用户间的最短距离
练习题
- 在 1 到 n 的数字中,有且只有唯一的一个数字 m 重复出现了,其它的数字都只出现一次。请把这个数字找出来。提示:可以充分利用异或的两个特性。
对于有的全部数字进行异或再和 1-n 这 n 个数字进行异或,最终得出的结果就是 m
复杂度分析的6个通用法则
- 四则运算法则
- 主次分明法则
- 齐头并进法则
- 排列组合法则
- 一图千言法则
- 时空互换法则
我们用随机变量(Random Variable)来描述事件所有可能出现的状态,并使用概率分布(Probability Distribution)来描述每个状态出现的可能性。
而随机变量又可以分为离散型随机变量(Discrete Random Variable)和连续型随机变量(Continuous Random Variable)。举几个例子,抛硬币出现正反面的次数以及每周下雨的天数,都是离散的值,所以对应的随机变量为离散型。而汽车每小时行驶的速度和银行排队的时间,都是连续的值,对应的随机变量为连续型。换句话,从计算的角度来说,我们可以直接求和得出的,就是“离散的”,需要用积分计算的,就是“连续的”。
联合概率是指在多元的概率分布中多个随机变量分别满足各自条件的概率
对于离散型随机变量,通过联合概率 P(x, y) 在 y 上求和,就可以得到 P(x),这个 P(x) 就是边缘概率(Marginal Probability)
对于连续型随机变量,我们可以通过联合概率 P(x, y) 在 y 上的积分,推导出边缘概率 P(x)。
ios优化,重复网络取消
离散数学及其应用
概率统计
线性代数及其应用
程序员的数学 系列
数学之美