Backdoor Embedding in Convolutional Neural Network Models via Invisible Perturbation #9
Description
公開日
2018-08-30
1. 概要
モデル本体の精度をほとんど落とすことなく、あるトリガーを入力すると意図したラベルに間違えさせられるバックドアを埋め込むことができる手法を提案、検証した。
2. 新規性・差分
既存のadversarialなやつは、モデルのパフォーマンスを低下させるが、bayes error rateとか見るとすぐばれる。本手法は、モデル本来の精度を落とさないのでばれない。さらに視覚的な変化も少ない。
3. 手法
perturbation maskを作成して、画像にそのmaskを適用すると同じラベルになる。
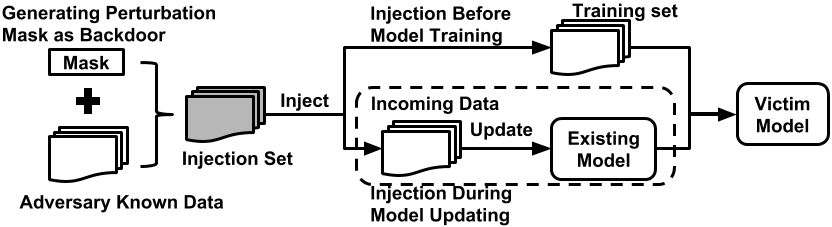
トレーニング時にバックドア画像を仕込んで置き、lossが最小になるようにトレーニングされる。

perturbation maskはstatic perturbation maskとadaptive perturbation maskの2つがある。
各maskのヒートマップは以下の通り。(最初がstatic)


static perturbation maskはヒートマップの0以外の要素cがハイパーパラメータ。
staticを適用した例(2段目がc=6, 3段目がc=10)

ただ、これだと繰り返しパターンなのであまりよくないのでadaptive perturbation maskを開発した。
基本的な考えは、deep learningは非線形でギリギリのところに決定境界線を引くので、別のところに押し込んでしまおうという感じ。
生成したサンプル↓

4. 結果
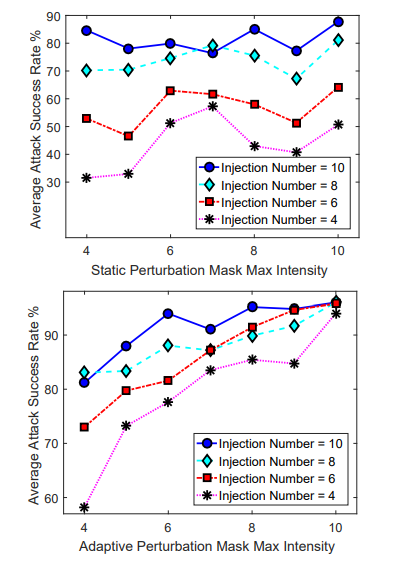
・BIB(Backdoor Injection Before model training)のまとめ
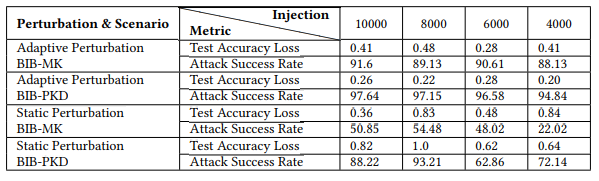
・BID(Backdoor Injection During model updating)のまとめ

5. 議論
防御手法としては、ランダムノイズを加えたりガウシアンフィルタでぼかしたりしてパターンを破壊してしまうのが手っ取り早い手法。ただ、攻撃者もぼかした画像を利用すれば守れなくなってしまう。
まぁほかにもいろいろ考えられるけど結局100%防げるものはないよね。
6. コメント
僕が昔やりたかったやつと完全一致していて感動した。
防御手法、普通にモデル複数用意してアンサンブルすればいいんじゃない?分からんけど。