Financial Data Analysis Made Simple — A production-grade Python toolkit for loading, cleaning, validating, and analyzing financial data with one-line pipelines.
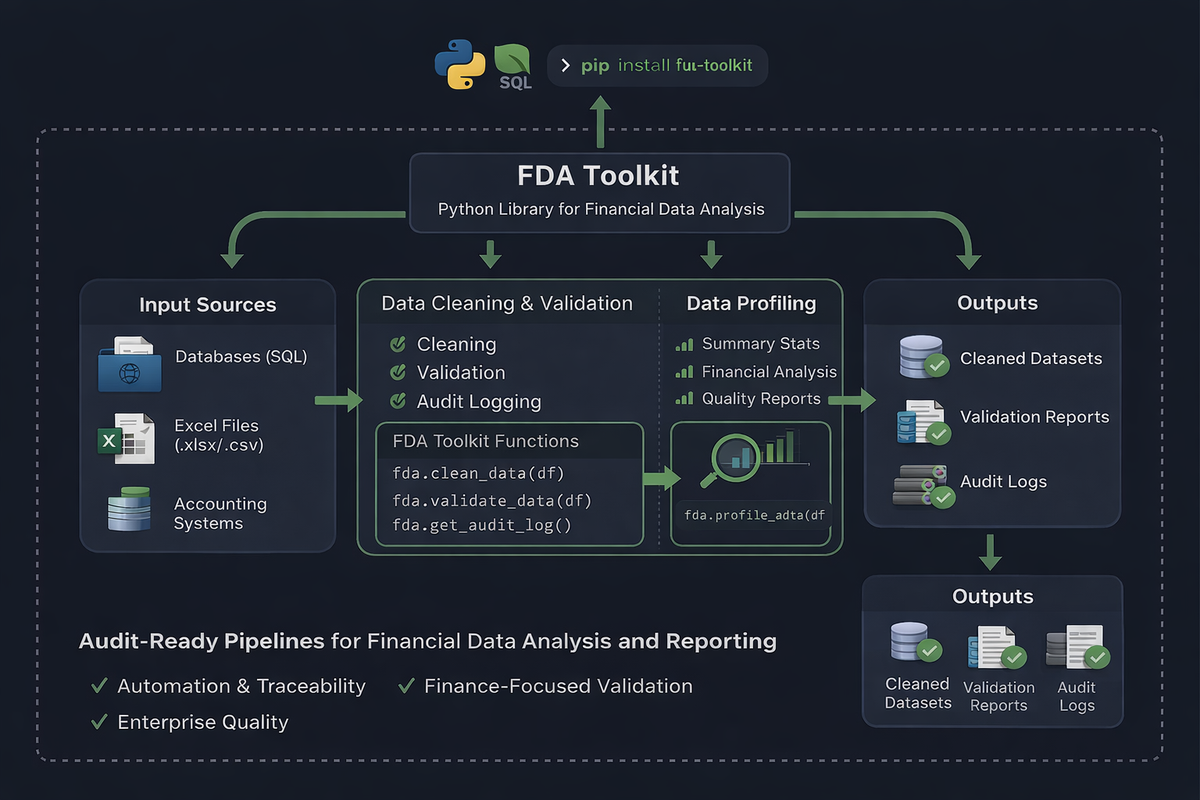
Financial data analysis is messy. You spend 80% of your time cleaning, validating, and transforming data instead of analyzing it. FDA Toolkit eliminates that pain by providing:
- 67 production-ready functions grouped into 8 intelligent modules
- One-line pipelines for common workflows (e.g.,
ftk.quick_clean_finance()) - Finance-aware validation — understand sign conventions, entity names, currency formats
- Audit trail — every operation logged for compliance and debugging
- Type-safe — full type hints and IDE autocomplete throughout
- Memory efficient — optimize dtypes, handle large files with chunking
- Professional API — pandas-like, intuitive, well-documented
| Module | Functions | Purpose |
|---|---|---|
| core | 17 | Column cleaning, types, duplicates, missing, outliers, text |
| features | 7 | Date & categorical feature engineering |
| finance | 11 | Currency parsing, entity standardization, financial validation |
| validation | 9 | Schema, ranges, integrity, reconciliation |
| reporting | 10 | Profiling, snapshots, delta reports, quick checks |
| io | 5 | Safe CSV/Excel reading, chunked processing, parquet export |
| pipelines | 2 | Pre-built quick_clean() and quick_clean_finance() |
| utils | 6 | Logging, security, memory optimization |
| TOTAL | 67 | Production-ready functions |
pip install fda-toolkitOr upgrade to latest:
pip install --upgrade fda-toolkitimport fda_toolkit as ftk
print(ftk.__version__) # 0.2.5import fda_toolkit as ftk
df = ftk.read_csv_safely("data/transactions.csv")
df_clean = ftk.quick_clean_finance(df, primary_key="transaction_id",
date_cols=["date"], currency_cols=["amount"])
ftk.quick_check(df_clean) # Profile results# See what's available (67 functions with tooltips)
ftk.info()
# Filter by category
ftk.info(category='Finance')
# Filter by module
ftk.info(module='finance.parsing')
# Combine filters
ftk.info(category='Finance', module='finance.parsing')Hover over function names to see descriptions (in Jupyter notebooks).
Handle the fundamentals with confidence:
from fda_toolkit.core import columns, duplicates, missing, outliers, text, types
df = columns.clean_column_headers(df) # 'Name ' → 'name'
df = types.clean_numeric_column(df['amount']) # '$1,234.56' → 1234.56
df = missing.fill_missing(df, strategy='mean') # Handle NaN intelligently
df = duplicates.remove_duplicates(df, subset=['id'])
df = outliers.flag_outliers(df, 'amount') # Flag statistical outliersDomain expertise built-in:
from fda_toolkit.finance import parsing, entities, rules
df['amount'] = parsing.parse_currency(df['amount']) # Handle $, €, £
df['vendor'] = entities.strip_legal_suffixes(df['vendor']) # ACME Ltd → ACME
rules.validate_sign_conventions(df, rules_config) # Verify debit/creditPrepare data for ML in seconds:
from fda_toolkit.features import datetime, categorical
df = datetime.extract_date_features(df, 'date') # Add year, month, quarter
df['category'] = categorical.limit_cardinality(df['category'], top_n=10)Catch issues before they become problems:
from fda_toolkit.validation import schema, ranges, integrity
schema.validate_required_fields(df, ['id', 'date', 'amount'])
violations = ranges.validate_data_ranges(df, {'amount': (0, 1_000_000)})
integrity.reconciliation_check(original_df, clean_df, value_cols=['amount'])Pre-built, battle-tested workflows:
# Generic pipeline
df_clean = ftk.quick_clean(df)
# Finance pipeline (smart defaults for financial data)
df_clean = ftk.quick_clean_finance(
df,
primary_key="invoice_id",
date_cols=["invoice_date", "due_date"],
currency_cols=["amount", "tax"]
)Understand your data instantly:
# Quick diagnosis
ftk.quick_check(df)
# Detailed profile
profile = ftk.profile_report(df) # Types, missingness, memory, outliers
# Track changes
snapshot_v1 = ftk.snapshot_dataset(df_before, name="before_clean")
snapshot_v2 = ftk.snapshot_dataset(df_after, name="after_clean")
delta = ftk.compare_snapshots(snapshot_v1, snapshot_v2)Read and write without surprises:
# Safe reading with encoding detection
df = ftk.read_csv_safely("messy_file.csv")
df = ftk.read_excel_safely("workbook.xlsx", sheet_name="Data")
# Process huge files in chunks
for chunk in ftk.chunked_processing("huge_file.csv", chunksize=50_000):
process(chunk)
# Export in optimized formats
ftk.export_parquet(df, "output.parquet") # Fast, compressedEvery function self-registers via decorator — no manual __all__ lists:
from fda_toolkit.registry import register_function
@register_function(
name="detect_fraud",
category="Validation",
module="custom.fraud"
)
def detect_fraud(df: pd.DataFrame) -> pd.DataFrame:
"""Your custom logic here."""
result = df[df['amount'] > threshold]
audit_log("detect_fraud", before=len(df), after=len(result))
return result
# Automatically appears in ftk.info()!Every operation is logged automatically:
from fda_toolkit.utils.logging import get_global_audit_log
log = get_global_audit_log()
for event in log.events:
print(f"✓ {event.name} at {event.timestamp_utc}")
# Export for compliance teams
audit_json = log.to_dict() # JSON-readyimport fda_toolkit as ftk
# 1. Load and diagnose
df = ftk.read_csv_safely("sales_transactions_2024.csv")
ftk.quick_check(df)
# → Reports: types, missing %, duplicates, outliers, memory usage
# 2. Clean for analysis
df_clean = ftk.quick_clean_finance(
df,
primary_key="transaction_id",
date_cols=["date", "due_date"],
currency_cols=["amount", "tax"]
)
# 3. Validate
from fda_toolkit.validation import integrity
integrity.reconciliation_check(
original=df,
cleaned=df_clean,
value_cols=["amount"],
group_cols=["vendor_id"]
)
# 4. Engineer features for ML
df_ml = ftk.extract_date_features(df_clean, "date")
df_ml = ftk.limit_cardinality(df_ml, "vendor", top_n=20)
# 5. Export and log
ftk.export_parquet(df_ml, "ready_for_ml.parquet")
print("✅ Pipeline complete with full audit trail!")# Run all tests
pytest
# Run specific module
pytest tests/test_core/
# Verbose output
pytest -vExample test:
import pandas as pd
from fda_toolkit.core.columns import clean_column_headers
def test_clean_headers():
df = pd.DataFrame({'Name ': [1], 'Age (years)': [2]})
result = clean_column_headers(df)
assert result.columns.tolist() == ['name', 'age_years']# Clone or download
cd fda_toolkit_project
# Install in editable mode (dev)
pip install -e .
# With dev dependencies (if available)
pip install -e ".[dev]"- Python 3.9+
- pandas (data manipulation)
- numpy (numerical operations)
- Audit logging — Every operation tracked with timestamps
- Data masking —
mask_sensitive_fields()for PII protection - Type safety — Full type hints prevent common errors
- Error handling — Clear, actionable error messages
- Memory optimization — Control data footprint
Explore the full API:
ftk.info() # List all functions
ftk.info(category="Finance") # Filter by domain
ftk.get_data_summary(df) # Profile a dataset
ftk.profile_report(df) # Detailed analysisFor detailed docs on each function:
from fda_toolkit.core.outliers import detect_outliers_iqr
help(detect_outliers_iqr) # Full docstring with examplesSee QUICK_REFERENCE.md for common patterns.
✅ Financial Reporting — Prepare data for compliance audits
✅ ML Pipelines — Clean & engineer features for models
✅ Data Migration — Validate and transform during transfers
✅ Anomaly Detection — Flag outliers in transactions
✅ Time Series Analysis — Extract date features automatically
✅ Data Quality Monitoring — Profile and compare snapshots
- Explore functions:
ftk.info() - Try examples: See examples/01_quick_check.py
- Read docs: docs/function_reference.md
- Run tests:
pytest - Extend: Add your own functions using
@register_function
MIT License — see LICENSE for details.
Found a bug? Have an idea? Open an issue or PR!
Built for financial analysts who value time, accuracy, and peace of mind. 📊✨
FDA Toolkit: Where data cleaning stops being painful and starts being productive.