Conversation
|
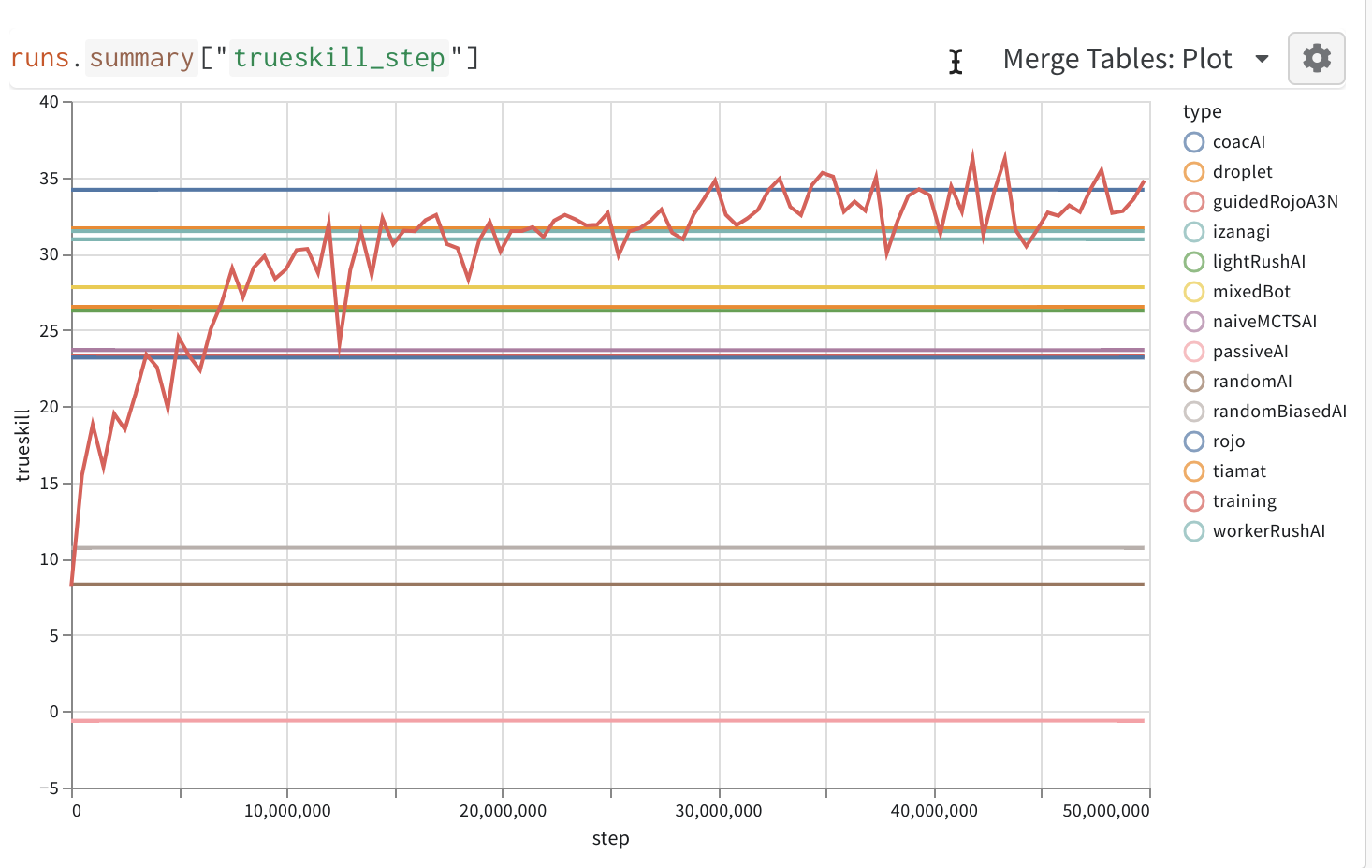
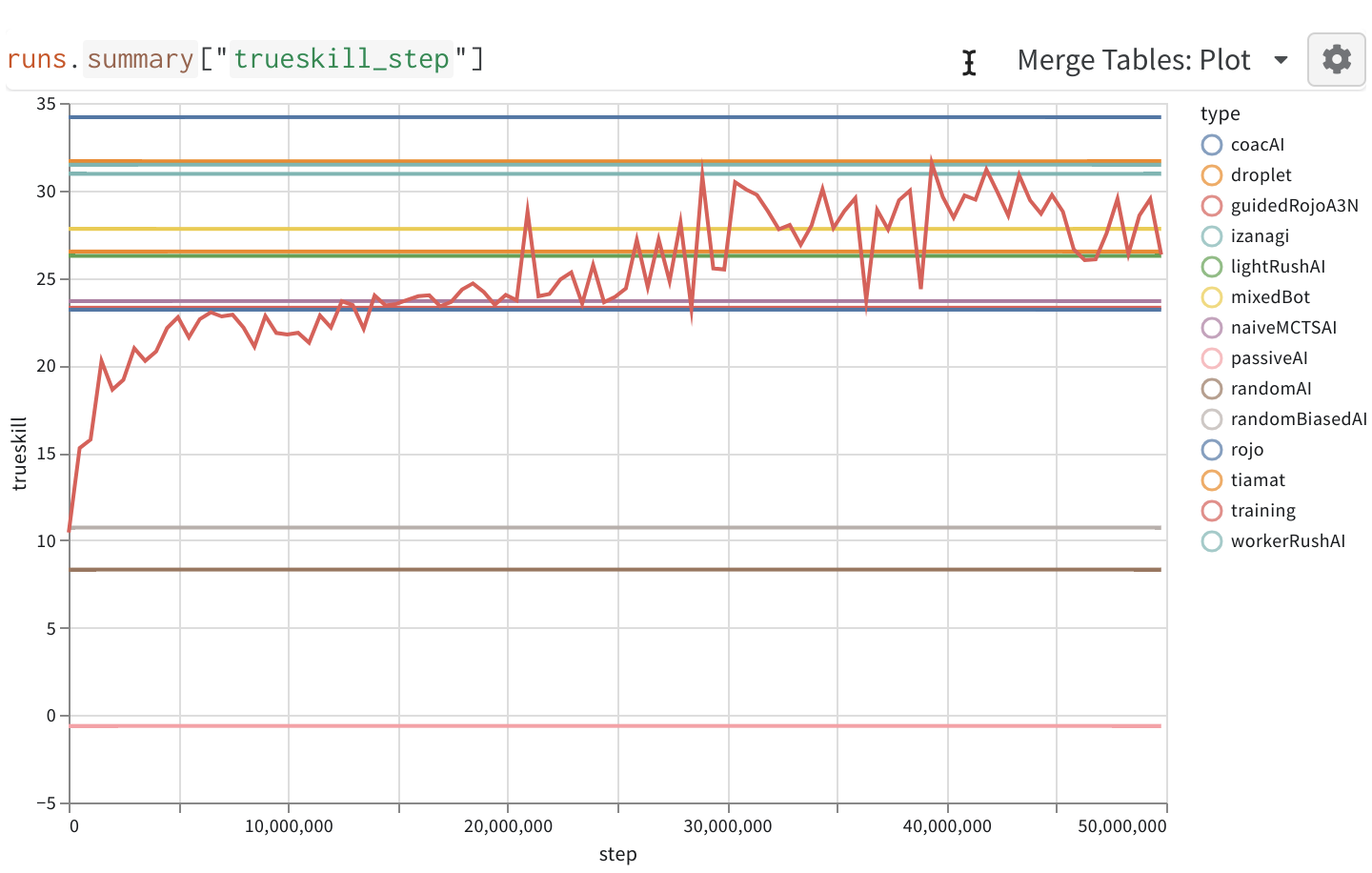
https://wandb.ai/gym-microrts/gym-microrts/runs/3k4i5p4y?workspace=user-costa-huang tracks the run.
In comparison, playing against the latest self performs much more poorly as follows:
|
 kachayev
left a comment
kachayev
left a comment
There was a problem hiding this comment.
Overall this makes sense. And I can see why playing against the last version leads to overfitting of some sort (I guess). I'm not sure how well does this scale with the number of historical version, but this is perfectly sounds approach for the simplest approach.
|
Thanks for reviewing @kachayev I just discovered a problem with this implementation: We are only training the reason that starts from the top left of the map, and when we randomly sample selfs from the past, this self is not trained to start from the bottom left. As a result, we are essentially training an agent to play against a random player... I will need to fix this by placing with |
|
Oh, that's a really good point! Should this be a part of the environment setting, like a random placement of opponents? It should be simple to add, just need to be careful with flipping player ids in observations |
I considered something like this but abandoned the idea because it made training twice as slow. We thought this was good kind of slow because maybe the agent learns something general such as to move towards the enemy instead of "just going to the bottom right". However, it turns out the agent just learned "going to the bottom right" and "going to the top left", so not that exciting from the generalization standpoint and therefore kind of a waste of compute. Ultimately this is something we should do (at least give an option to do randomized starting location), but it's probably not a big priority right now. |
|
I have done some index manipulation: Now the agent issues action for the player starting from the bottom right (the |
|
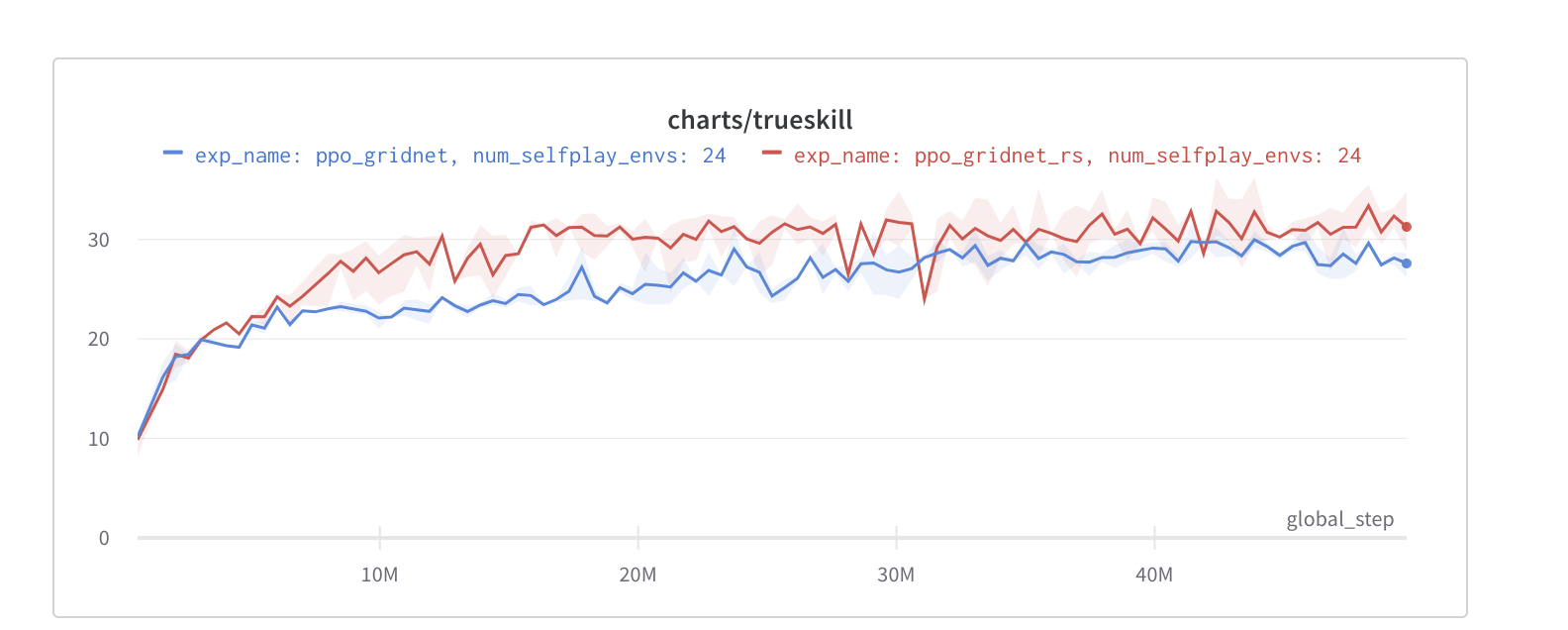
Interestingly, the current runs we have suggest just playing with an almost-random player (red line) is still better than playing against the latest selfs (blue lines). The experiments are done with three random seeds each. I am going to run the experiments for the correct
|
|
When using the correct implementation, random selfplay performs no better than naive / latest selfplay
|
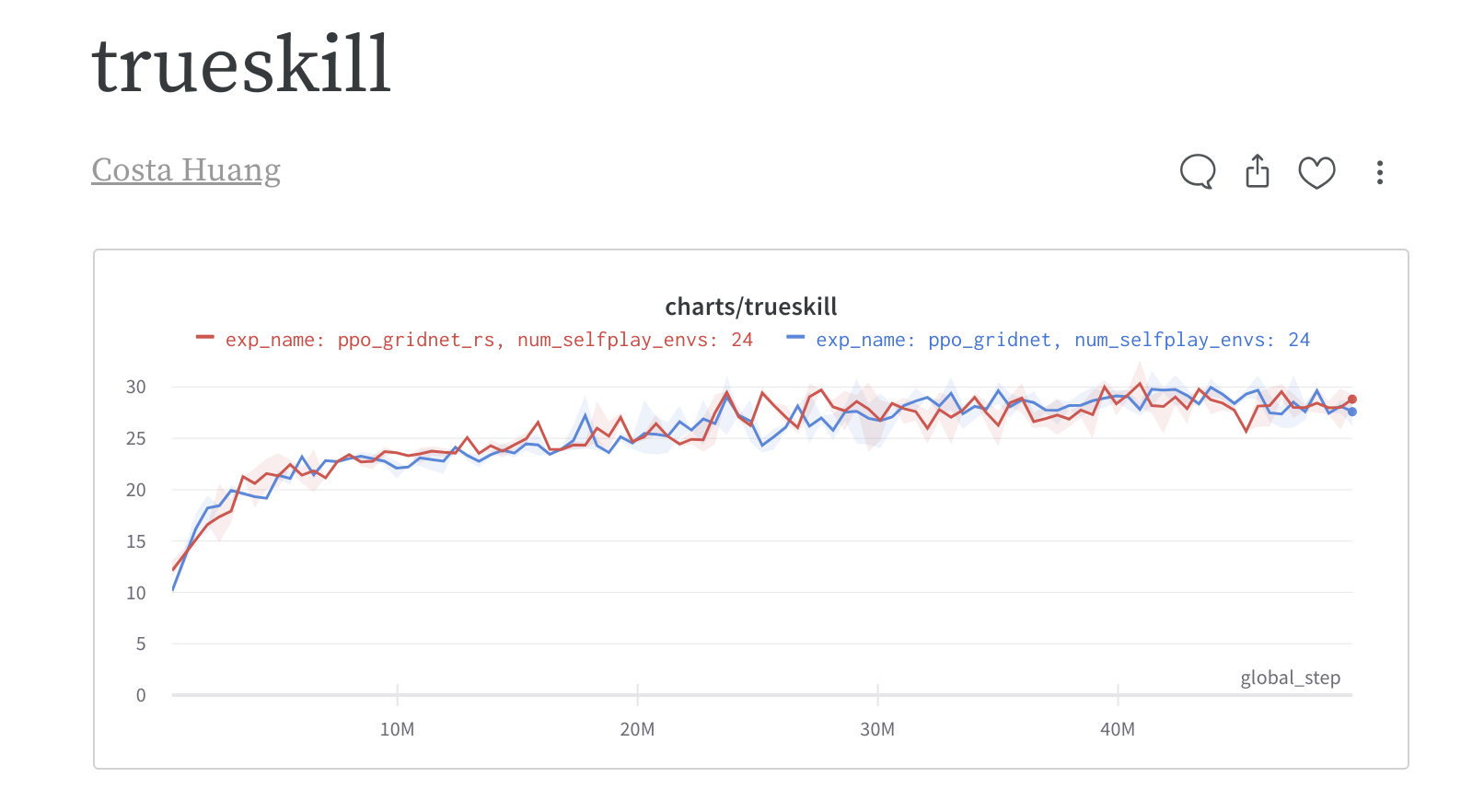
Continue from #35