Lessons Learned
- 28/08/22: para probar si el DAG funciona, acordarse de hacer la prueba con una fecha pasada como start_date.
- 18/08/22: para poder realizar una carpeta trackeada por Git, es necesario tener archivos en su interior para poder realizar los commits.
- 19/08/22: les dejo un link para que podamos transformar la fecha a un formato adecuado. Así filtramos como corresponde: https://www.postgresqltutorial.com/postgresql-date-functions/postgresql-to_date/
- 22/08/22: Para pegar texto en la consola se debe hacer click derecho en el título de la ventana -> Editar -> Pegar.
- 19/09/22: Les paso a dejar todos los pasos que tuve que hacer para lograr la instalación de Docker en Windows, y posteriormente hacer funcionar Hadoop.
- Usé la misma VM de Ubuntu que usamos para airflow
- Me aseguré de estar usando WSL 2
- Lo más importante de todo, habilitar la integración de Ubuntu con Docker (en Configuración de Docker Desktop -> Resources -> WSL Integration)

Luego:
- Monté las unidades de windows en el directorio raíz para evitarme problemas de pathing (https://youtu.be/M521KLHGaZc?t=292 hasta el min 8 nomás)
- Seguí la instrucciones de este simple video: https://www.youtube.com/watch?v=_et7H0EQ8fY (no hace nada especial pero me hizo darme cuenta que tenía que correr Docker desde la consola de Ubuntu, y no desde windows). En teoría debería andar la imagen de prueba que muestra el video.
Una vez funciona Docker:
- Siguiendo el Tutorial de Hadoop, desde la consola de Ubuntu me paro dentro la carpeta docker-hadoop, y recién ahí ejecuto
docker-compose up -d. (Importante hacerlo consudo, o antes haber puestosudo su, porque sino te tira un error de config file). - En teoría ya levanta todos los containers correctamente y quedan funcionando. Entonces seguimos el tutorial y cuando tenemos que crear los archivos "mapper.py" y "reducer.py" es importarte guardarlos con formato de final de linea "LF", porque sino te va a tirar un montón de errores java con exit code 127 en los subprocesos del mapReduce. Para hacer esto, fijarse en VSCode a la hora de guardar estos archivos:
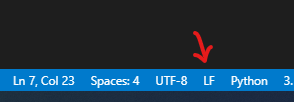
- Ya debería funcionar correctamente, y para chequear los resultados:
hadoop fs -cat output11/part-00000cambiando "output11" por el nombre que le hayas dado al output (los podés chequear todos conhadoop dfs -ls -R).
20/09/22
Uso de Repo propuesto en Tutorial de Hadoop
- Se prueba sin poder correr correctamente por diferencia de arquitectura entre chip M1 (máquina local) y AMD64 (imagen de nodos Docker).
-
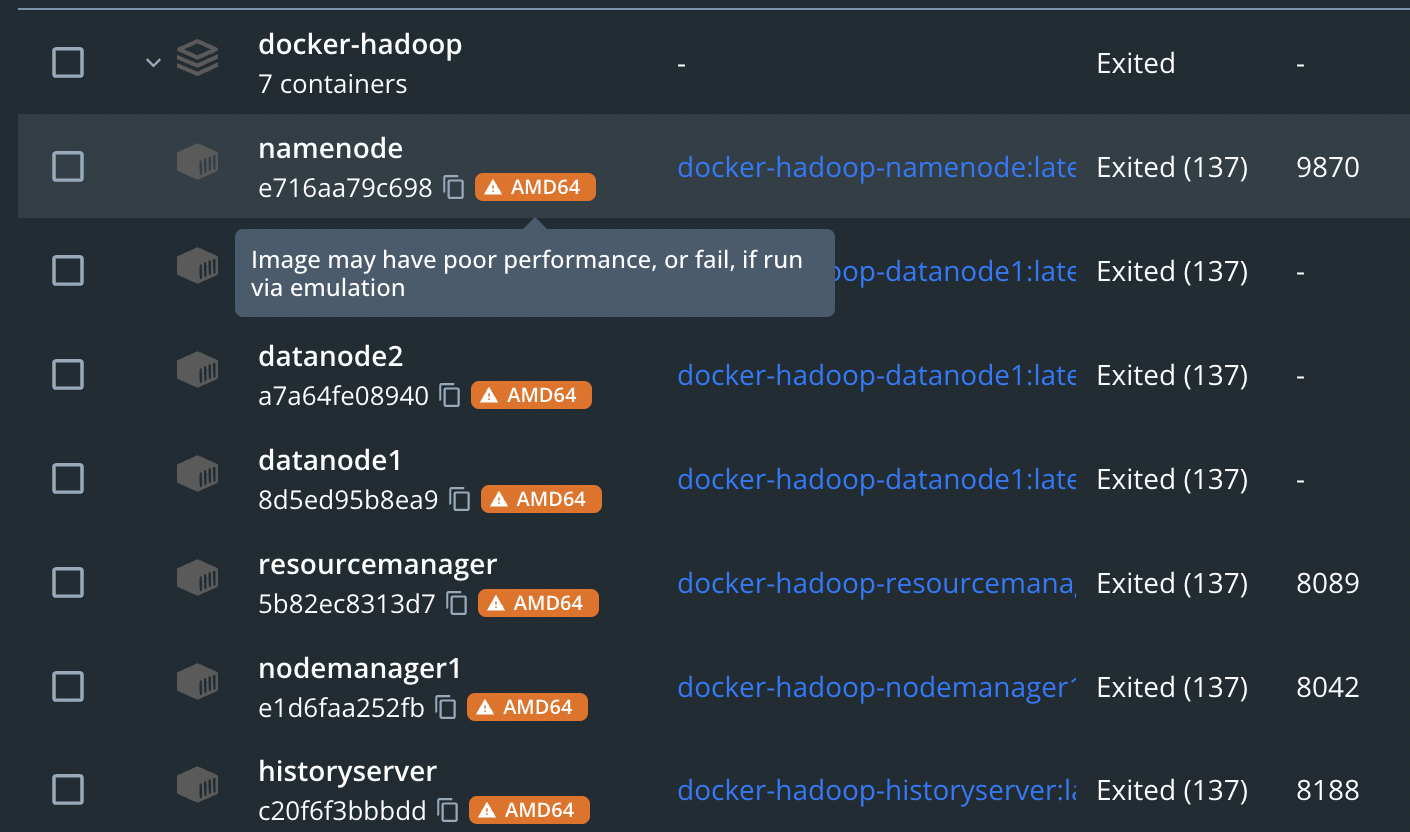
- Se decide buscar otro repo que se adapte a la máquina local.
- Se siguen los pasos del repo de Matt y se levantan los nodos de Hadoop sin problemas.
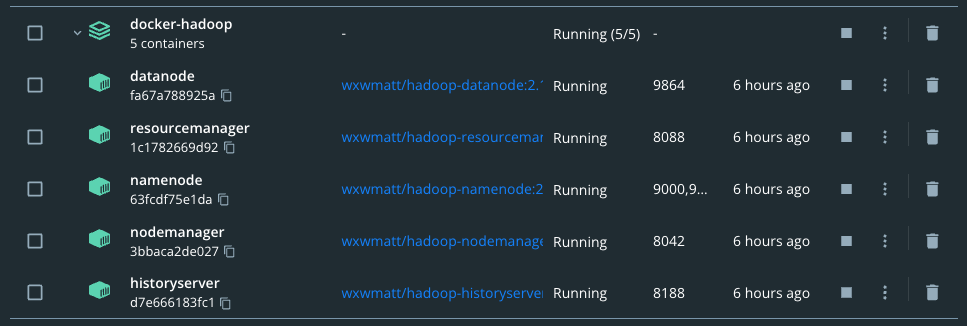
- Se realiza la configuración de los archivos de forma manual siguiendo los pasos del repo.
- Se utilizan los archivos
mapper.pyyreducer.pydel tutorial de Boyu1997 y se experimenta el error:Error: java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 127. - Para arreglar este error, es necesario revisar instalación de python2 o python3 en el
nodename. En caso de no estar presentes, se procede a instalar desde la carpeta donde está el repo de Docker-Hadoop como se detalla en la wiki de este repo:
- Para python2:
docker exec -it namenode bash -c "apt update && apt install python -y"- Para python3:
docker exec -it namenode bash -c "apt update && apt install python3 -y"
- El uso de cada python en particular se debe a como inicia el código del
mapper.pyy elreducer.py(shebang):
- Para python2:
#!/usr/bin/env python.- Para python3:
#!/usr/bin/env python3.