Before diving into Databricks and Spark, it will help to have a baseline understanding of a few key concepts. Judge your understanding of these five key concepts:
- APIs, libraries, and packages
- Notebook architecture
- Map and reduce functions
- Switching between programming languages in a notebook (Spark calls this magic commands)
- Mutability and data structures such as graphs, lists, and datasets
Were any of these topics brand new? Did you need to look them up before answering? If you are not comfortable with notebooks, distributing computing, clusters, and modular programming, try to do some research on your own and come back to this page.
Now, it is important to understand the term big data. Big data refers to working with and analyzing data sets that are too large or complex to be dealt with by traditional data-processing software. Common characteristics of big data are volume, velocity, and variety.
Volume Data comes in from IoT devices, industrial equipment, points of sale, and social media.
Velocity Data comes in constantly, in real time, and sometimes late.
Variety Data comes in all forms - structured, unstructured, numeric, text, times, and anything else you can imagine.
How do we deal with the volume, velocity, and variety? Splitting the data and tasks into chunks and working on them at the same time. This known as distributed computing and parallel processing. This is where Spark and Databricks come in.
Spark is a programming framework built for high-performance distributed computing. It is a tool to organize data engineering and data science tasks to perform well over a large dataset on a specialized (Spark) cluster configuration.
Spark Capabilities and Connections
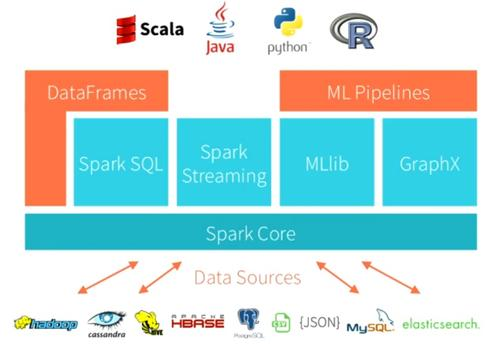 /
/
Databricks is a platform built on top of Spark. It makes using Spark easy. It provides its users an interactive, notebook-based development environment to quickly build Spark code and helps them create and manage clusters to run Spark code. It also provides many more bells and whistles to make using Spark as easy as possible.
Example Azure Spark Streaming Achitecture
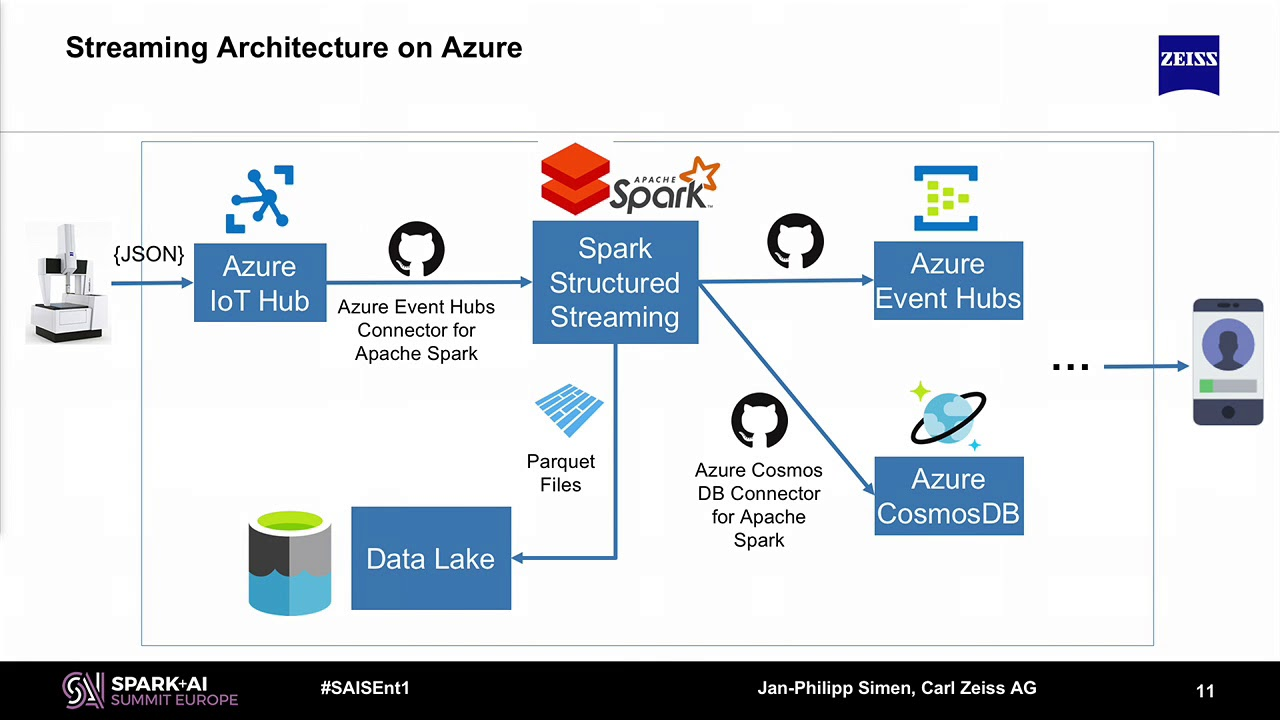 Photo: databricks.com
Photo: databricks.com
Application developers and data scientists incorporate Spark into their applications to rapidly query, analyze, and transform data at scale. Tasks most frequently associated with Spark include ETL and SQL batch jobs across large data sets, processing of streaming data from sensors, IoT, or financial systems, and machine learning tasks.
Avanade utilizes Databricks for different purposes depending on our client's needs. Here are a few examples:
One communications client had trouble performing big data calculations. They took too long and could not be performed in real-time. This diminished the precision of the results because by the time the calculations were completed, new information was available and needed to be accounted for. Avanade created an Azure Databricks solution in a PoC, proving real time calculations were possible.
Databricks was leveraged to create a predictive maintenance program for an automotive client. The program recommends maintenance actions to replace or adjust driving chains during routine workshop visits. The project increased customer satisfaction and resulted in cost savings through reduced shop visits and warranty cases.
A banking client had a problem with customers abandoning the credit card application process before completion. After starting a project to remedy the abandonment issue, the client realized there were many improvements to data, process, and systems that needed to happen in parallel to scale the solution they created. Avanade created a data platform based in Azure PaaS to improve insight into the customer throughout the credit card application process. To enable this vision, Avanade used Databricks to build a unified view into every metric for each of the client's customers across multiple time intervals, which became the data model upon which the churn models were built for the abandonment use case.
In the insurance industry, Avanade and Accenture worked to bring together multiple insurance quote data sources, as well as data from the client's websites into a curated data lake. The team used Databricks to provide data transformations before making the data available to the client's data science team and creating a data warehouse to support the client's reporting needs.
Before starting any studying, read through this guide to familiarize yourself with the available resources. Although the steps are listed in order, you may skip or repeat sections based on your progression or deep-dive into a specific use case you find interesting.

- Complete the Set Up section below.
- If you are new to python, scala, or big data you may find it helpful to begin by using one of the Understanding Spark, Python, & Scala resources below. We recommend Python unless you have previous Scala knowledge. If you understand the purpose of clusters and distributed computing (such as MapReduce), datastructures such as lists and arrays, and syntax, you can probably skip this step.
- Complete the Avanade University regimen HERE. These are fantastic courses that come straight from the horse's mouth. You will need to request a voucher for the courses, which may take time due to limited availability of vouchers. In the meantime, you can study the resources on this page.
- If at any point you feel like you need more information, try one of the Databricks Architecture & Best Practices resources below to hone the concepts. Some resources here may be more specifically tailored to your daily work. For example, a data engineer may want to focus on Data ingestion with Azure Data Factory.
- Explore the Azure connections most relevant to your work using the Azure Databricks resources below.
- Practice by working with the notebooks on this page. You can download them to your local box then submit a pull request here with a solution.
- Create a pull request and suggest changes or additions to this pathway. If you roll-off a Databricks project, feel free to write a brief client story on this repository.
- You need an Azure subscription to use Azure Databricks. If you do not already have a subscription, it is available through Avanade. You can practice on the Databricks Community Edition, however you will find the Azure subscription necessary when diving into Azure Databricks.
- Join the Databricks Teams Channel.
Functional Programming in Scala
If you prefer reading a book to online courses, this book is excellent.
Introduction to Azure DataBricks
Azure Databricks: Getting Started
DS320 DataStax Enterprise Analytics with Spark
Note: This resource focuses on Scala and Cassandra but is a useful resource for understanding Spark under the hood regardless of your preferred language or connectors.
Best Practices Resources from Databricks
Databricks provided us with these best practices as part of our partnership. This link will only work once you are in the Databricks Teams Channel.
Official documentation can be dry but also helpful! Read this overview and then peruse the documentation links at the bottom of the page. There is a plethora of information.
Example Data Flow
 Photo: azure.microsoft.com
Photo: azure.microsoft.com
Perform Basic Data Transformations in Azure Databricks
Create Data Visualizations using Azure Databricks and Power BI
Data Ingestion with Azure Data Factory
Access SQL Data Warehouse Instances with Azure Databricks
This pathway gave guidance on learning about Spark and Databricks. You should now be able to apply these skills to data engineering, data science, azure architectures, and any unique work you are faced with. You may also be interested in taking the Databricks Certified Developer exam. We recommend the Python version unless you have previous Scala knowledge.
Next, it is important to share the Databricks work you complete with the TC. Please make suggestions on this page by creating a pull request with changes. If you roll off a Databricks project, share your client stories and challenges with a pull request or work with Grant Stephens to schedule a time to present to the TC. We will be rewarding excellent contributors with Go Team! awards. Pull request instructions can be found HERE.
Requests will be reviewed monthly. If you would like your request reviewed sooner, please contact Jennifer Gagner, Matt Russell, or Grant Stephens.