Text summarization is the process of using a computer program to generate a shorter version of a text document while retaining its main ideas. The amount of information available to people has increased exponentially with the advent of the internet, which has led to the problem of information overload. This has made automatic summarization an increasingly popular and useful tool. Manually summarizing long documents can be a daunting and time-consuming task, and automatic summarization tools have been developed to make the process easier and more efficient.
AnacondaorJupyter NotebookorGoogle Colaboratory
Note:Pythonshould be installed on your machine if you are usingJupyter Notebookand you may need to manually install some of the packages needed usingpipcommand.
Text summarization is the process of creating a short, coherent, and fluent summary of a longer text document. The critical tasks in extraction-based summarization are identifying key phrases in the document and using them to discover relevant information. There are two different approaches that are used for text summarization:
- Extractive Summarization
- Abstractive Summarizing
Extractive Summarization
How do you extract the most important words from the text and stitch them together to produce a condensed version.
Abstractive Summarization
Machine learning algorithms can generate new phrases and sentences to capture the meaning of the source document. This technique relies on being able to paraphrase and shorten parts of a document using advanced natural language techniques. When such abstraction is done correctly, they can assist in overcoming grammatical inaccuracies.
- Automatic extraction based on weighting
Weighting of word, Weighting of sentence, choosing all sentence above a certain weight threshold so we Ordering the selected sentence as they appear in the original article The approach of weighting is based on frequencies and the Frequencies is the number of the time the word occurs. The filtered sentences are put in the original order as they appear in the document. This approach is a statistical method that purely relies on term level content of the story. This method involves preprocessing on terms like removing stop words, normalizing terms, replacing synonyms etc. - Automatic summary extraction based on user query
This approach performs weighting of sentences based on the incoming user query. The weight of sentence This finds applications in creating a story search engine where a user can query for a story subject like “student wizard magic potions” and the search engine would present books like Harry Potter with a summary of the books extracted using this query. This will present the user with relevant stories and the part of the stories they are interested in. - Information extraction
This method works in 2 phases. Selection of useful information and generation of a summary using the information. This method captures the meaning of sentences by grammatical analysis which is why it is better than the automatic extraction approach. It can help in development of intelligent agents that gain better semantic knowledge of text. - Cue word method
Weight is assigned to text based on its significance like positive weights "verified, significant, best, this paper" and negative weights like "hardly, impossible". Cue phrases are usually genre dependent. The sentence consisting such cue phrases can be included in summary. The cue phrase method is based on the assumption that such phrases provide a "rhetorical" context for identifying important sentences. The source abstraction in this case is a set of cue phrases and the sentences that contain them. Above all statistical features are used by extractive text summarization. - Location method
Weights are assigned to text based on location whether it appears in lead, medial or final position in a paragraph or in appears in the prominent section of the document such as conclusion or introduction. Leading several sentences of a document or last few sentences or conclusion are considered to be more important and included in summary. Hovy& Lin and Edmundson used this method. The location method relies on the following intuition headings, sentences in the beginning and end of the text, text formatted in bold, contain important information to the summary.
-
Frequency Based Approach
First clean the document means remove the stop words from the document. Then count the frequency of each word in remaining text file by comparing select world with each word. Then select the keyword which have highest frequency. After that select the sentences which have these keywords. -
Frequency detection method
In this technique, we first eliminate commonly occurring words and then find keywords according to the frequency of the occurrence of the word. This assumes that if a passage is given, more attention will be paid to the topic on which it is written, hence increasing the frequency of the occurrence of the word and words similar to it. Now we need to extract those lines in which these words occur since the other sentences wouldn’t be as related to the topic as the ones containing the keywords would be. Thus, a summary is generated containing only useful sentences. -
Keyword Frequency method
This algorithm takes the previous algorithm to a further level. This takes into account facts such as the first few words of an article has more weights as compared to the rest, since they represent the first paragraph generally contains a gist of what is being said in the rest of the article. Secondly, it also takes into account the frequency of occurrence of keywords obtained in the previous algorithm in a particular sentence. Higher the keyword count within a sentence, more is its relevance to the topic at hand.
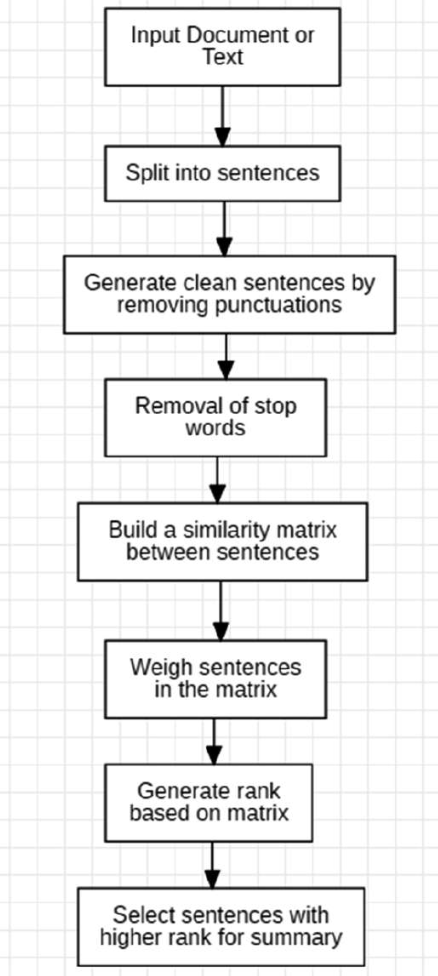
There are different approaches for text summarization and some algorithms are identified to implement these approaches.
In this paper, unsupervised learning approach is implemented and cosine similarity technique is used to find the similarity between sentences. To generate rank based on similarity, text rank algorithm is used and sentences with top rank are placed in summarized text.
And also, addition to the existing model, we are going to provide the feature of summarizing the text of any language with the help of google translator API. First the text will be converted to English using translator and the summarization takes place in English.
After the completion of summarization again the text in English will be converted into the input language using translator.
This helps in extending the existing models which does the summarization only in English to summarizing the text of any language.
Input

