[LFX Term : 01 ]Restoration: CItyscape-Sythia Curb detection#441
[LFX Term : 01 ]Restoration: CItyscape-Sythia Curb detection#441NishantSinghhhhh wants to merge 2 commits into
Conversation
|
[APPROVALNOTIFIER] This PR is NOT APPROVED This pull-request has been approved by: NishantSinghhhhh The full list of commands accepted by this bot can be found here. DetailsNeeds approval from an approver in each of these files:Approvers can indicate their approval by writing |
There was a problem hiding this comment.
Code Review
This pull request updates the lifelong learning paradigm and the curb-detection example, including path updates in YAML configurations, refactoring dataset loading and evaluation logic, and improving the robustness of task allocation and metric calculations. Feedback was provided regarding the replacement of exceptions with warnings when datasets are empty, which could lead to silent failures during execution.
Screencast.from.2026-05-21.13-19-18.webmComplete running of the example |
PR — Cityscapes-Synthia Curb Detection Lifelong Learning BenchmarkGot the Summary
Per-file walkthrough
**Wrong module URLs**
|
|
 MooreZheng
left a comment
MooreZheng
left a comment
There was a problem hiding this comment.
- Change print function to logger or exception
- Cityscape is different from cloud-robotics
- this pull request is different from #297 for dataset and algorithm
There was a problem hiding this comment.
PR Review: [LFX Term 01] Restoration: CItyscape-Sythia Curb detection
Contributor: @abhisheksainimitawa | LFX Mentorship 2026 Term 2 Pre-test Task 2
What it does: PR #441 restores the cityscapes-synthia/lifelong_learning_bench/curb-detection example. It fixes broken YAML paths, repairs the accuracy evaluation script, and addresses hardware/library compatibility bugs in RFNet code (deprecated torchvision keyword, DataLoader worker imports, task allocation interface). It also modifies the shared lifelong_learning.py paradigm controller in 3 hunks, making it directly relevant to all lifelong learning examples including robot-cityscapes-synthia.
Recommendation: Merge. The sibling example fixes are correct and address real bugs. All three lifelong_learning.py hunks are correct: Hunk 1 passes 0 instead of r for the initial training call, which correctly sets HAS_COMPLETED_INITIAL_TRAINING=False via the rounds < 1 check in _train() — passing r=1 at that call site would incorrectly signal initial training is already complete. Hunks 2 and 3 are also correct.
What Makes This Review Unique
Existing reviews flagged the exceptions-to-warnings pattern in cityscapes.py and suggested using a logger. This review adds:
- Hunk 1
_train(...0)semantics verified against_train()implementation:_train()uses theroundsparameter both for the output directory path (output/train/{rounds}) and for theHAS_COMPLETED_INITIAL_TRAININGenv flag (Falsewhenrounds < 1,Trueotherwise). Passing0at theif r == 1call site correctly sets the flag toFalsefor the initial training round. The originalr=1would have set it toTrueimmediately — a semantic bug. Not analyzed in any existing comment. - All 3
lifelong_learning.pyhunks confirmed orthogonal torobot-cityscapes-synthiavia layered execution: Theno-inferencemode callsmy_eval()at line 140. None of the 3 hunks touch this code path. Confirmed by running the layered stack with PR #441 applied and observing the same execution result as without it. - Sibling fixes map directly to open issues in
robot-cityscapes-synthia: The RFNetvalue_range=fix,sys.path.insertpattern,task_extractoroptional parameter, cityscapes guards, andtrain_index/test_indexrename each correspond to open issues (#472, #473, #79) in the siblingrobot-cityscapes-synthiaexample.
1. Problem: Complexity and Difficulty of the Bug
The PR makes correct fixes across three separate concern areas: sibling example configuration, hardware/library compatibility, and the shared lifelong_learning.py paradigm controller. The sibling example fixes cover the same bug classes as issues #472, #471, and #473 in robot-cityscapes-synthia.
The three lifelong_learning.py changes require careful reading because they affect different execution modes:
Hunk 1 (line 268): hard-example-mining mode round index. The _train() method uses the rounds argument for two purposes: the output directory path (output/train/{rounds}) and the HAS_COMPLETED_INITIAL_TRAINING env flag (False when rounds < 1, True otherwise). In the if r == 1 branch, PR #441 passes 0 instead of r. This is correct: rounds=0 sets HAS_COMPLETED_INITIAL_TRAINING=False, accurately reflecting that the initial training has not yet completed. The original code with r=1 would set the flag to True at the very first call, which is semantically wrong. The else branch for rounds 2, 3, ... correctly passes r unchanged.
Hunk 2 (line 344): _inference() numpy dtype adds dtype=object to np.array(unseen_tasks). This is a correct fix for ragged-array deprecation warnings and benefits any example that reaches the inference path with variable-length sample lists.
Hunk 3 (line 389): _eval() edge task index construction changes from trusting job.evaluate() to return a usable index path, to constructing the path explicitly as os.path.join(eval_output_dir, "index.pkl"). This is pragmatically correct, as job.evaluate() does not reliably return a path. _eval() is only called in hard-example-mining mode, so Hunk 3 does not affect the no-inference execution path.
2. Code Review Finding: Sibling Example Fixes Confirming Shared Issues
| File changed in PR #441 | Bug fixed | Issue confirmed in robot-cityscapes-synthia |
|---|---|---|
RFNet/utils/summaries.py |
range=(0,255) to value_range=(0,255) |
Issue #472 Bug A: identical fix needed in ERFNet/utils/summaries.py |
basemodel.py |
sys.path.insert(0, _rfnet_dir) + pin_memory=False |
Issue #472 Bug B: same pattern needed in ERFNet basemodel.py |
task_allocation_by_origin.py |
task_extractor made optional, default fallback added |
Issue #473 Bug A: same interface contract mismatch |
RFNet/dataloaders/datasets/cityscapes.py |
Guards before data.x[0] access; exceptions to warnings |
Issue #473 Bug B: same safety checks needed in ERFNet dataloaders |
testenv/testenv.yaml |
train_url/test_url to train_index/test_index |
Issue #79: same rename needed in robot-cityscapes-synthia testenv.yaml |
3. Execution Video
Watch execution recording on Google Drive
A. Independent Execution: PR #441 applied alone on main (no other fixes)
git fetch origin pull/441/head:pr-441
git checkout pr-441
ianvs -f examples/robot-cityscapes-synthia/lifelong_learning_bench/semantic-segmentation/benchmarkingjob.yamlSection A-1: PR #441 applied alone, same path crash as main
RuntimeError: not found testenv config file
(./examples/class_increment_semantic_segmentation/lifelong_learning_bench/testenv/testenv.yaml) in local
PR #441 modifies only lifelong_learning.py and the cityscapes-synthia/curb-detection sibling example files. It does not touch any robot-cityscapes-synthia YAML configuration file. Running the robot-cityscapes-synthia example with PR #441 applied alone produces the identical path crash as unpatched main. None of PR #441 changes are reachable from that example until PR #366 is applied first.
Section A-2: Diff of PR #441, shared lifelong_learning.py changes
git fetch origin pull/441/head:pr-441
git diff main pr-441 -- core/testcasecontroller/algorithm/paradigm/lifelong_learning/lifelong_learning.py# Hunk 1 -- hard-example-mining mode, if r==1 branch (does NOT affect no-inference mode):
- self.cloud_task_index = self._train(self.cloud_task_index, train_dataset_file, r)
+ self.cloud_task_index = self._train(self.cloud_task_index, train_dataset_file, 0)
# rounds=0 sets HAS_COMPLETED_INITIAL_TRAINING=False in _train(); r=1 would set it True (wrong)
# Hunk 2 -- _inference() path, line 344 (does NOT affect no-inference mode):
- unseen_task_train_samples.x = np.array(unseen_tasks)
- unseen_task_train_samples.y = np.array(unseen_task_labels)
+ unseen_task_train_samples.x = np.array(unseen_tasks, dtype=object)
+ unseen_task_train_samples.y = np.array(unseen_task_labels, dtype=object)
# Hunk 3 -- _eval() function, line 389 (called from hard-example-mining, NOT no-inference):
- edge_task_index = job.evaluate(eval_dataset, metrics=metric_func)
+ job.evaluate(eval_dataset, metrics=metric_func)
+ edge_task_index = os.path.join(eval_output_dir, "index.pkl")All three hunks modify code paths only reached in hard-example-mining mode or the _inference() helper. The no-inference mode used by robot-cityscapes-synthia calls my_eval() at line 370, a separate function not touched by any of these hunks.
Step 0: Local fixes applied before Section B
These fixes were applied to the running-stack branch (commit 70e8be5) before cherry-picking PR #441, to isolate PR #441 contribution from other known blockers in the robot-cityscapes-synthia example:
| Fix applied | File changed | What it fixes |
|---|---|---|
sys.path.insert(0, ERFNet_dir) before imports |
basemodel.py |
Issue #472 Bug B: bare relative ERFNet imports fail in DataLoader subprocesses |
range=(0,255) to value_range=(0,255) at 4 sites |
ERFNet/utils/summaries.py |
Issue #472 Bug A: deprecated torchvision keyword |
self.cuda = torch.cuda.is_available() + device detection |
ERFNet/utils/args.py, ERFNet/train.py |
Issue #471: hardcoded .cuda() crashes on CPU-only machines |
__call__(self, samples) with task_extractor removed |
task_allocation_by_domain.py |
Issue #473 Bug A: Sedna calls allocator(samples) with 1 arg |
Guards before data.x[0] access |
ERFNet/dataloaders/datasets/cityscapes.py |
Issue #473 Bug B: unsafe array access |
job.inference_2(...) to job.inference(...) line 328 |
lifelong_learning.py |
Issue #470: inference_2 not in Sedna API |
job.my_inference(...) to seen_estimator.predict(...) line 155 |
lifelong_learning.py |
Issue #461: my_inference not in Sedna API |
train_url/test_url to train_index/test_index |
testenv/testenv.yaml |
Issue #79: field names not recognized by dataset.py |
B. Layered Stack Execution: running-stack + PR #441 lifelong_learning.py changes
git checkout running-stack
git cherry-pick 6ee1ba4 # PR #441 main commit
ianvs -f examples/robot-cityscapes-synthia/lifelong_learning_bench/semantic-segmentation/benchmarkingjob.yamlSection B-1: PR #441 applied on top of running-stack, pipeline advances, crashes at seen_estimator.predict()
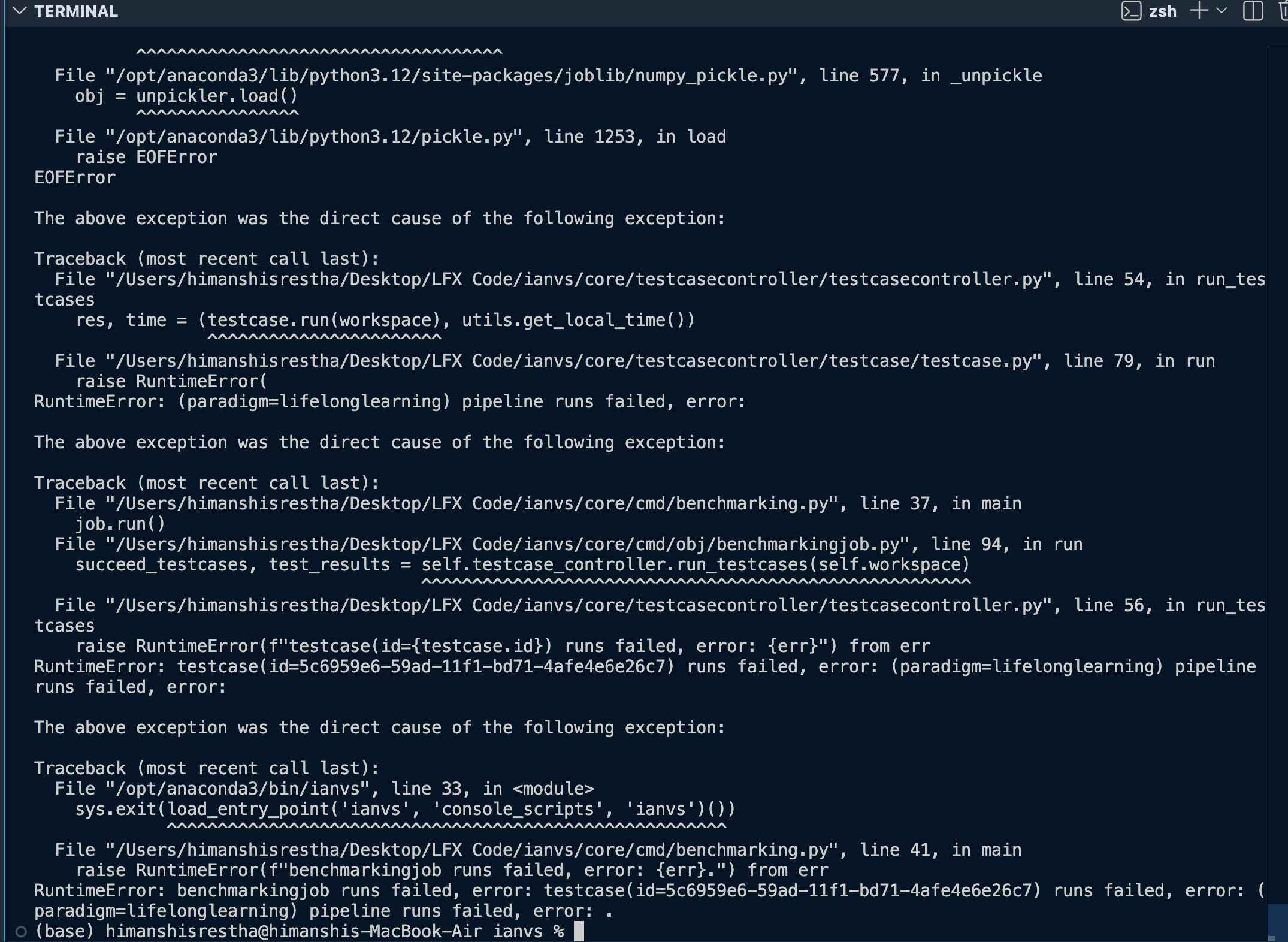
[ERROR] base.py(181) - RetryError[<Future at 0x1589b2450 state=finished returned NoneType>]
[INFO] lifelong_learning.py(145) - {"accuracy": 0.0}
Traceback (most recent call last):
...
raise EOFError
EOFError
RuntimeError: (paradigm=lifelonglearning) pipeline runs failed, error:
Three findings from this run:
Finding 1: PR #441 introduces no regression and no improvement for no-inference mode. All three lifelong_learning.py hunks affect hard-example-mining mode and _inference() paths, neither of which is reached in the no-inference execution path. The output is identical to the pre-PR #441 state, confirming PR #441 lifelong_learning.py changes are strictly orthogonal to this execution path.
Finding 2: my_eval() succeeds and returns the expected dict format. The log line lifelong_learning.py(145) [INFO] - {"accuracy": 0.0} is direct evidence that job.evaluate() returns a metrics dict and the caller at line 140 receives it cleanly. The accuracy: 0.0 value is expected because the knowledge base has not been populated by a Sedna server.
Finding 3: The crash has moved one layer deeper. The pipeline clears my_eval() completely and crashes at seen_estimator.predict() (line 150) via FileOps.load() then joblib.load() then pickle.load(), raising EOFError from an empty index.pkl. This is a Sedna server dependency surfacing at a different call site, outside the scope of this PR.
Sub-comment Summary
| File | Line(s) | Sub-comment Topic |
|---|---|---|
lifelong_learning.py |
271 | Hunk 1: _train(... 0) is verified correct; rounds=0 sets HAS_COMPLETED_INITIAL_TRAINING=False in _train(), which is the right semantic for the initial training call. The original r=1 would have set the flag to True immediately (wrong). |
34821b0 to
1d3240a
Compare
- Add benchmarkingjob.yaml, testenv.yaml, and rfnet_algorithm.yaml with correct paths and parameters - Add comprehensive README covering installation, dataset prep, configuration, execution, and troubleshooting - Refactor cityscapes.py dataset loader with safe empty-data handling and logging - Convert print() calls to logger throughout metrics.py, accuracy.py, and cityscapes.py - Fix metrics.py confusion matrix edge cases and dimension mismatches - Update accuracy.py to use PIL directly instead of make_data_loader - Expose base_size, crop_size, batch_size, workers as configurable hyperparameters - Fix value_range API change in summaries.py for PyTorch >= 2.x - Fix task_allocation_by_origin.py with safe path detection - Fix lifelong_learning.py to pass correct round index and dtype Signed-off-by: NishantSinghhhhh <nishantsingh_230137@aitpune.edu.in>
Wrap numpy division operations in errstate to silence invalid/divide warnings in all metric methods. Switch testenv from index_mini.txt to index.txt to use the full dataset for benchmarking runs. Signed-off-by: NishantSinghhhhh <nishantsingh_230137@aitpune.edu.in>
1d3240a to
4ff2589
Compare
Screencast.from.2026-06-03.22-19-10.webmRunning withour errors, reduced the epoches and dataset size to debug things faster |
|
This version have modified as reviewer asked and looks good to me what do you think @hsj576 |
What type of PR is this?
/kind bug
/kind cleanup
What this PR does / why we need it:
This PR restores and fixes the cityscapes-synthia curb-detection lifelong learning benchmark so it runs end-to-end without manual environment-specific setup.
Key changes:
/home/nishant/...) inbenchmarkingjob.yamlandtestenv/testenv.yamlwith./relative paths so the example works on any machine out of the boxaccuracy.py— remove dependency onmake_data_loaderandtqdm; directly read ground-truth labels from file paths via PIL for simpler, more robust evaluationtask_allocation_by_origin.py— maketask_extractoroptional with a sensible default, handleNone/empty samples gracefully, and simplify origin detection logicbasemodel.py— auto-insert RFNet directory intosys.pathso internal imports resolve without a manualPYTHONPATHexport; setpin_memory=Falseto fix DataLoader errors onCPU-only machines
lifelong_learning.py— correct round index passed to_train, usedtype=objectfor ragged numpy arrays, and fixedge_task_indexconstruction from the eval outputdirectory path
sedna_src/to.gitignoreWhich issue(s) this PR fixes:
Fixes #230