One‑API is a single‑endpoint gateway that lets you manage and call dozens of AI SaaS models without the headache of custom adapters. 🌐 Simply change the model_name and you can reach OpenAI, Anthropic, Gemini, Groq, DeepSeek, and many others—all through the same request format.
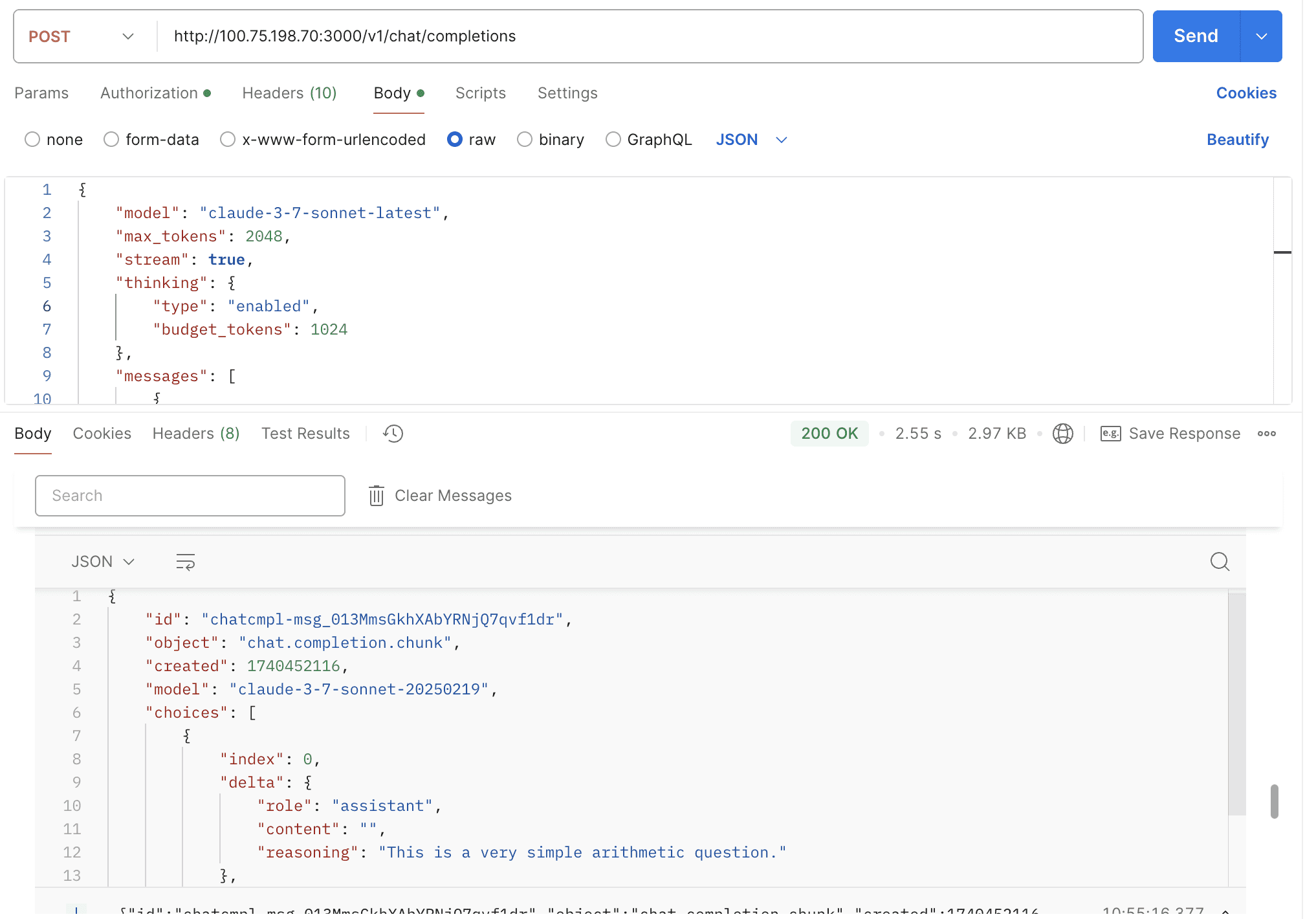
=== One-API Regression Matrix ===
Variant gpt-4o-mini gpt-5-mini claude-haiku-4-5 gemini-2.5-flash openai/gpt-oss-20b deepseek-chat grok-4-fast-non-reasoning azure-gpt-5-nano
Chat (stream=false) PASS 6.03s PASS 12.39s PASS 7.08s PASS 3.08s PASS 2.96s PASS 6.11s PASS 2.99s PASS 8.99s
Chat (stream=true) PASS 5.70s PASS 10.19s PASS 3.49s PASS 4.98s PASS 7.22s PASS 3.73s PASS 2.71s PASS 15.24s
Chat Tools (stream=false) PASS 6.02s PASS 9.29s PASS 4.17s PASS 3.19s PASS 1.78s PASS 5.16s PASS 3.03s PASS 15.86s
Chat Tools (stream=true) PASS 4.82s PASS 5.52s PASS 4.71s PASS 6.72s PASS 0.61s PASS 6.22s PASS 4.16s PASS 14.32s
Chat Structured (stream=false) PASS 6.02s PASS 10.66s PASS 6.47s PASS 6.71s PASS 7.63s PASS 4.65s PASS 1.51s PASS 15.48s
Chat Structured (stream=true) PASS 2.21s PASS 10.34s PASS 4.18s PASS 4.98s PASS 1.20s PASS 6.46s PASS 2.55s PASS 15.21s
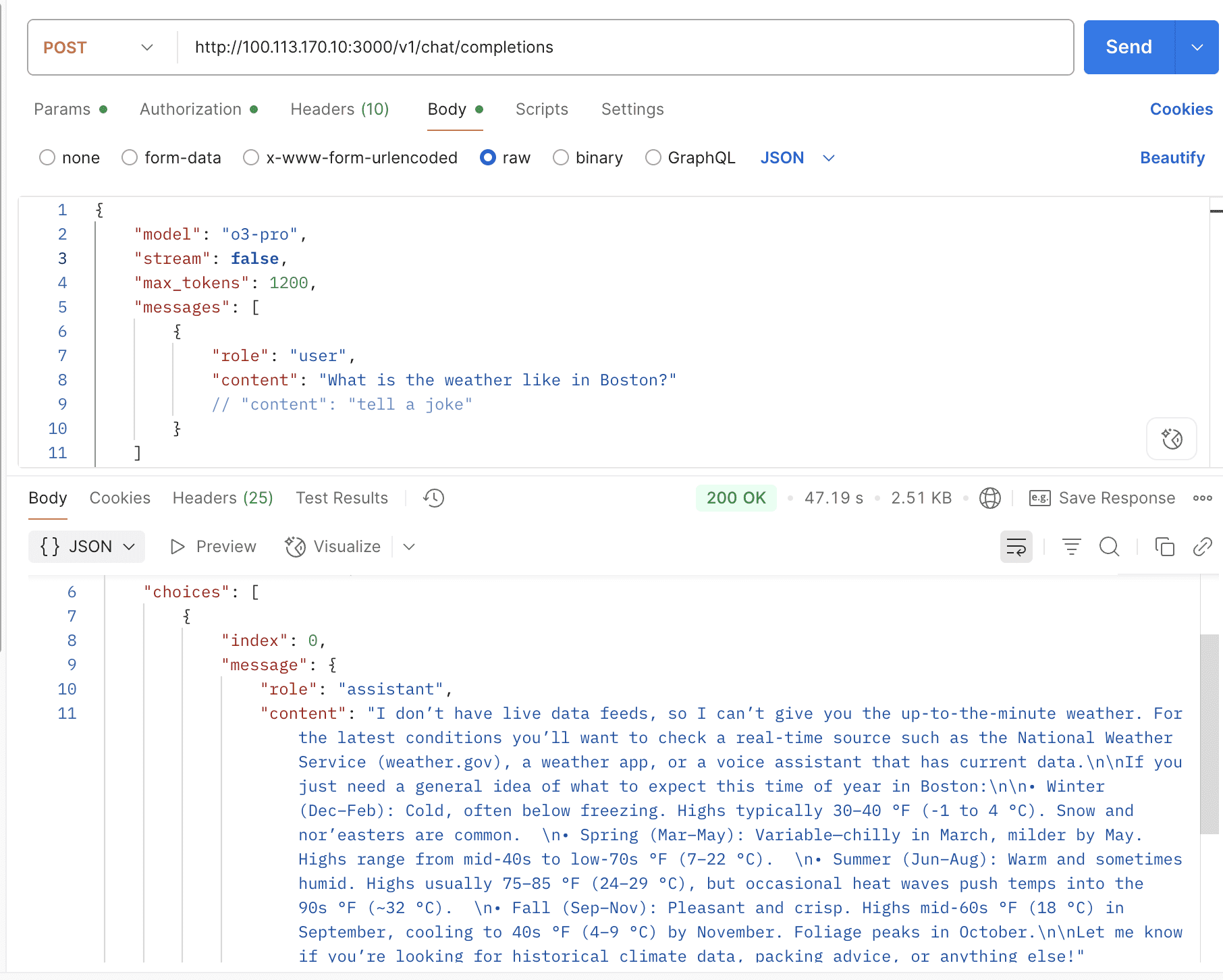
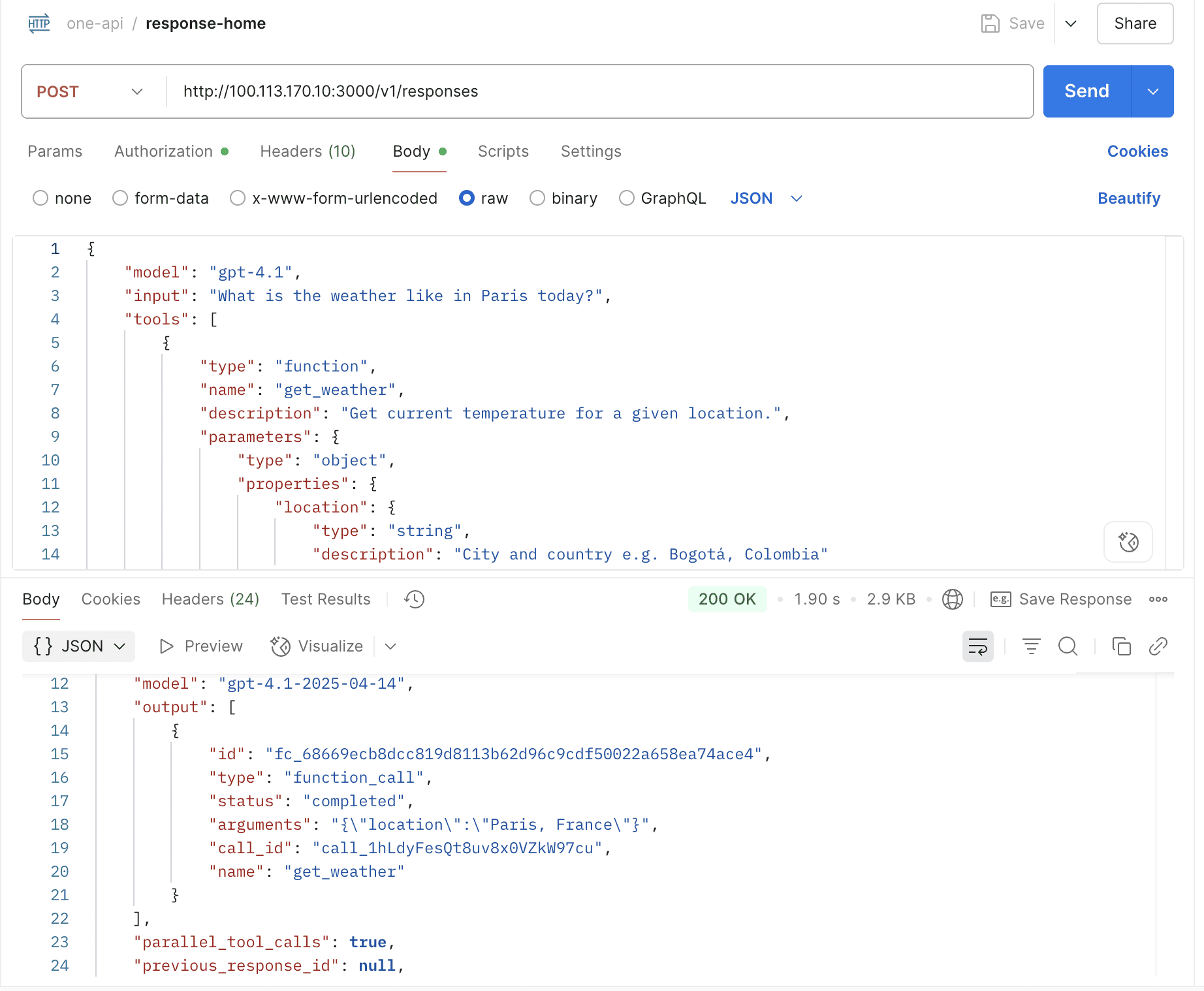
Response (stream=false) PASS 5.78s PASS 17.29s PASS 10.73s PASS 5.62s PASS 5.60s PASS 5.97s PASS 5.07s PASS 18.06s
Response (stream=true) PASS 4.26s PASS 15.69s PASS 5.50s PASS 5.12s PASS 3.54s PASS 5.48s PASS 3.76s PASS 17.50s
Response Vision (stream=false) PASS 5.17s PASS 11.08s PASS 9.90s PASS 5.10s SKIP SKIP PASS 5.52s PASS 30.63s
Response Vision (stream=true) PASS 7.62s PASS 8.67s PASS 4.27s PASS 4.98s SKIP SKIP PASS 3.07s PASS 42.85s
Response Tools (stream=false) PASS 6.03s PASS 8.21s PASS 4.16s PASS 7.69s PASS 2.61s PASS 4.28s PASS 3.52s PASS 8.67s
Response Tools (stream=true) PASS 8.13s PASS 6.76s PASS 4.70s PASS 2.53s PASS 3.73s PASS 5.20s PASS 2.70s PASS 11.90s
Response Structured (stream=false) PASS 6.50s PASS 11.52s PASS 4.32s PASS 8.05s PASS 6.02s FAIL status 400 Bad Request: {"error"… PASS 2.76s PASS 23.83s
Response Structured (stream=true) PASS 4.25s PASS 6.12s PASS 5.14s PASS 4.97s PASS 3.60s FAIL status 400 Bad Request: {"error"… PASS 1.74s PASS 26.90s
Claude (stream=false) PASS 3.70s PASS 7.73s PASS 4.16s PASS 8.12s PASS 4.20s PASS 3.56s PASS 6.54s PASS 6.79s
Claude (stream=true) PASS 3.67s PASS 9.14s PASS 7.58s PASS 4.26s PASS 4.18s PASS 4.68s PASS 3.71s PASS 9.45s
Claude Tools (stream=false) PASS 5.20s PASS 12.11s PASS 7.30s PASS 1.85s PASS 5.79s PASS 6.70s PASS 1.76s PASS 9.87s
Claude Tools (stream=true) PASS 2.50s PASS 9.40s PASS 9.78s PASS 7.23s PASS 2.23s PASS 4.74s PASS 2.65s PASS 8.85s
Claude Structured (stream=false) PASS 5.19s PASS 17.93s PASS 3.50s PASS 6.09s PASS 4.75s PASS 5.64s PASS 5.13s FAIL structured output fields missing
Claude Structured (stream=true) PASS 1.53s FAIL stream missing structured output… PASS 3.50s PASS 5.22s PASS 1.85s PASS 3.93s PASS 1.49s FAIL stream missing structured output…
Totals | Requests: 160 | Passed: 151 | Failed: 5 | Skipped: 4
Failures:
- azure-gpt-5-nano · Claude Structured (stream=false) → structured output fields missing
- azure-gpt-5-nano · Claude Structured (stream=true) → stream missing structured output fields
- deepseek-chat · Response Structured (stream=false) → status 400 Bad Request: {"error":{"message":"This response_format type is unavailable now (request id: 202510240239395607035417250974)","type":"invalid_request_error","param":"","code":"invalid_reques…
- deepseek-chat · Response Structured (stream=true) → status 400 Bad Request: {"error":{"message":"This response_format type is unavailable now (request id: 202510240239394051289902547661)","type":"invalid_request_error","param":"","code":"invalid_reques…
- gpt-5-mini · Claude Structured (stream=true) → stream missing structured output fields
Skipped (unsupported combinations):
- deepseek-chat · Response Vision (stream=false) → vision input unsupported by model deepseek-chat
- deepseek-chat · Response Vision (stream=true) → vision input unsupported by model deepseek-chat
- openai/gpt-oss-20b · Response Vision (stream=false) → vision input unsupported by model openai/gpt-oss-20b
- openai/gpt-oss-20b · Response Vision (stream=true) → vision input unsupported by model openai/gpt-oss-20b
The original author stopped maintaining the project, leaving critical PRs and new features unaddressed. As a long‑time contributor, I’ve forked the repository and rebuilt the core to keep the ecosystem alive and evolving.
- 🔧 Complete billing overhaul – per‑channel pricing for the same model, discounted rates for cached inputs, and transparent usage reports.
- 🖥️ Refreshed UI/UX – a fully rewritten front‑end that makes tenant, quota, and cost management a breeze.
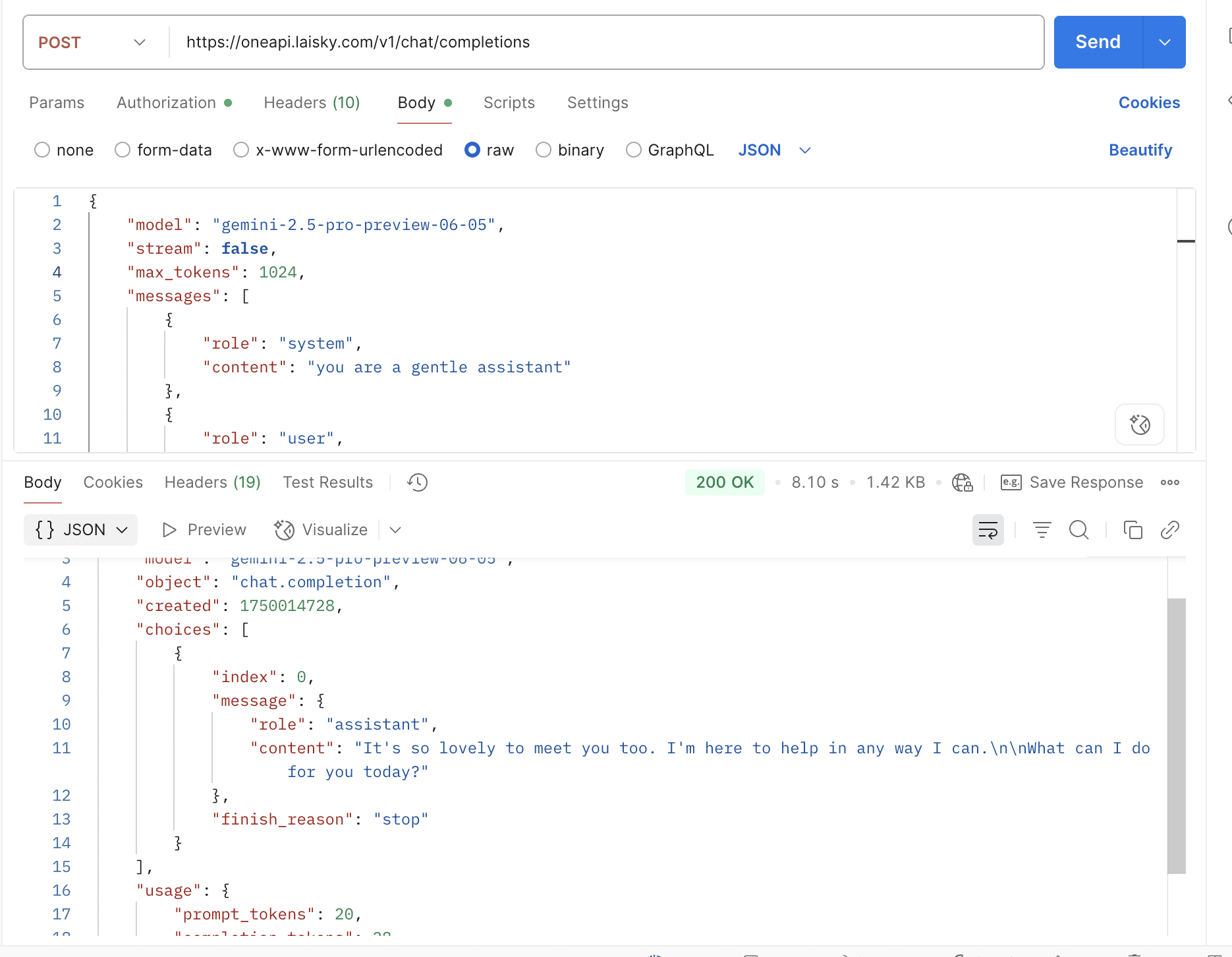
- 🔀 Transparent API conversion – send a request in ChatCompletion, Response, or Claude Messages format and One‑API will automatically translate it to the target provider’s native schema.
- 🔄 Drop‑in database compatibility – the original One‑API schema is fully supported, so you can migrate without data loss or schema changes.
- 🐳 Multi‑architecture support – runs on Linux x86_64, ARM64, and Windows out of the box.
Docker images available on Docker Hub:
ppcelery/one-api:latestppcelery/one-api:arm64-latest
One‑API empowers developers to:
- Centralize tenant management and quota control.
- Route AI calls to the right model with a single endpoint.
- Track usage and costs in real time.
Also welcome to register and use my deployed one-api gateway, which supports various mainstream models. For usage instructions, please refer to https://wiki.laisky.com/projects/gpt/pay/.
- One API
- Synopsis
- Tutorial
- Contributors
- New Features
- Universal Features
- OpenAI Features
- (Merged) Support gpt-vision
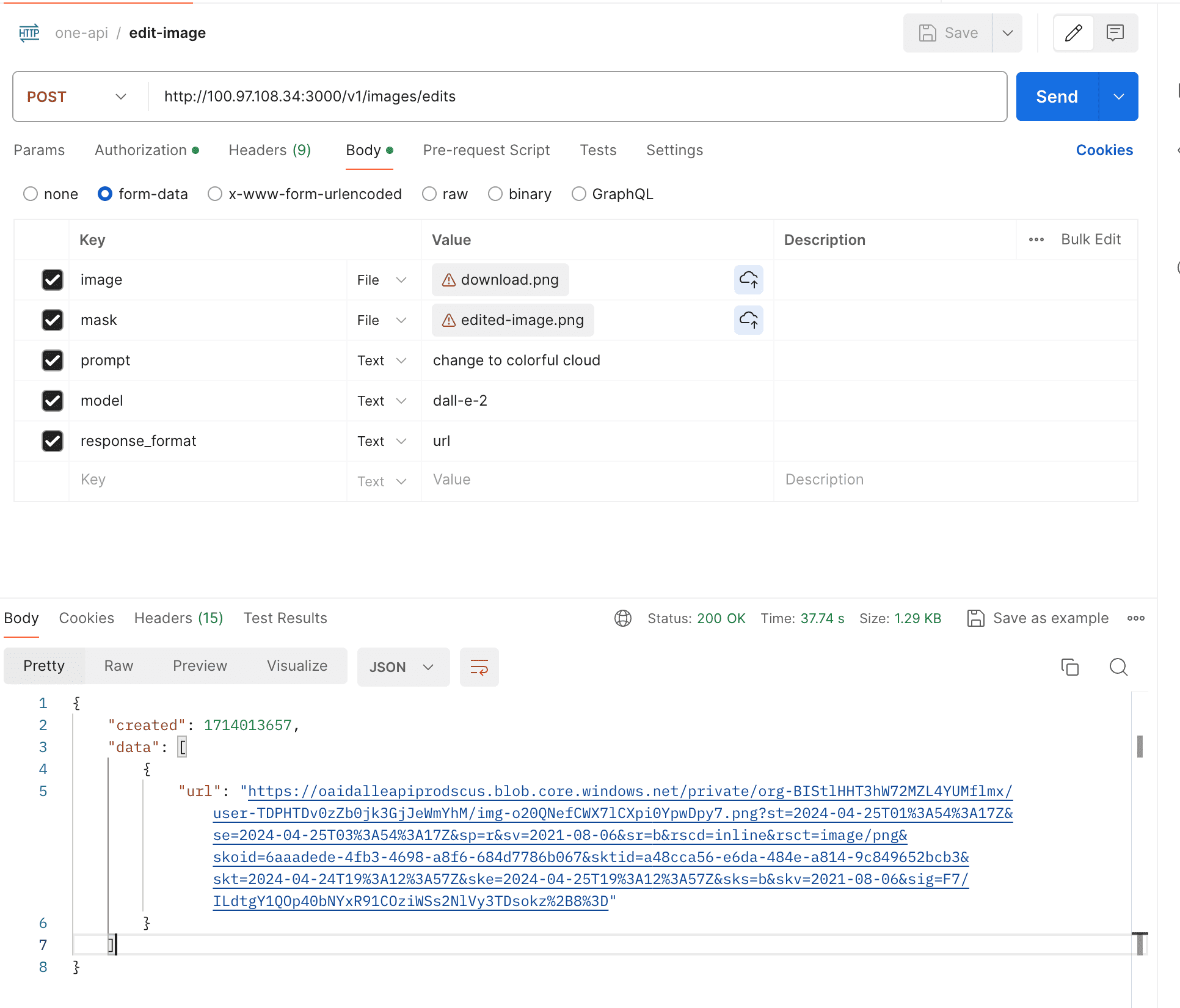
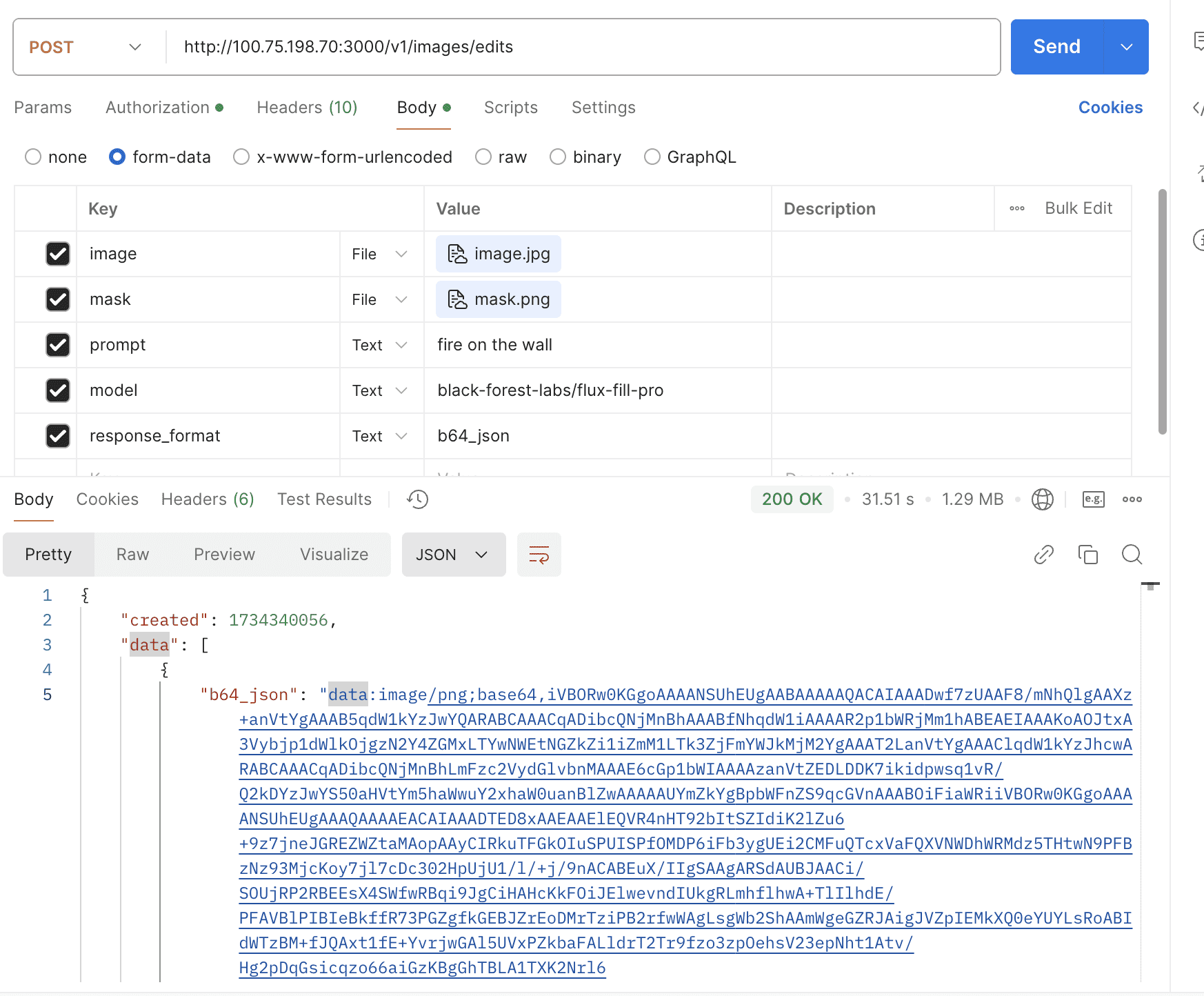
- Support openai images edits
- Support OpenAI o1/o1-mini/o1-preview
- Support gpt-4o-audio
- Support OpenAI web search models
- Support gpt-image-1's image generation & edits
- Support o3-mini & o3 & o4-mini & gpt-4.1 & o3-pro & reasoning content
- Support OpenAI Response API
- Support gpt-5 family
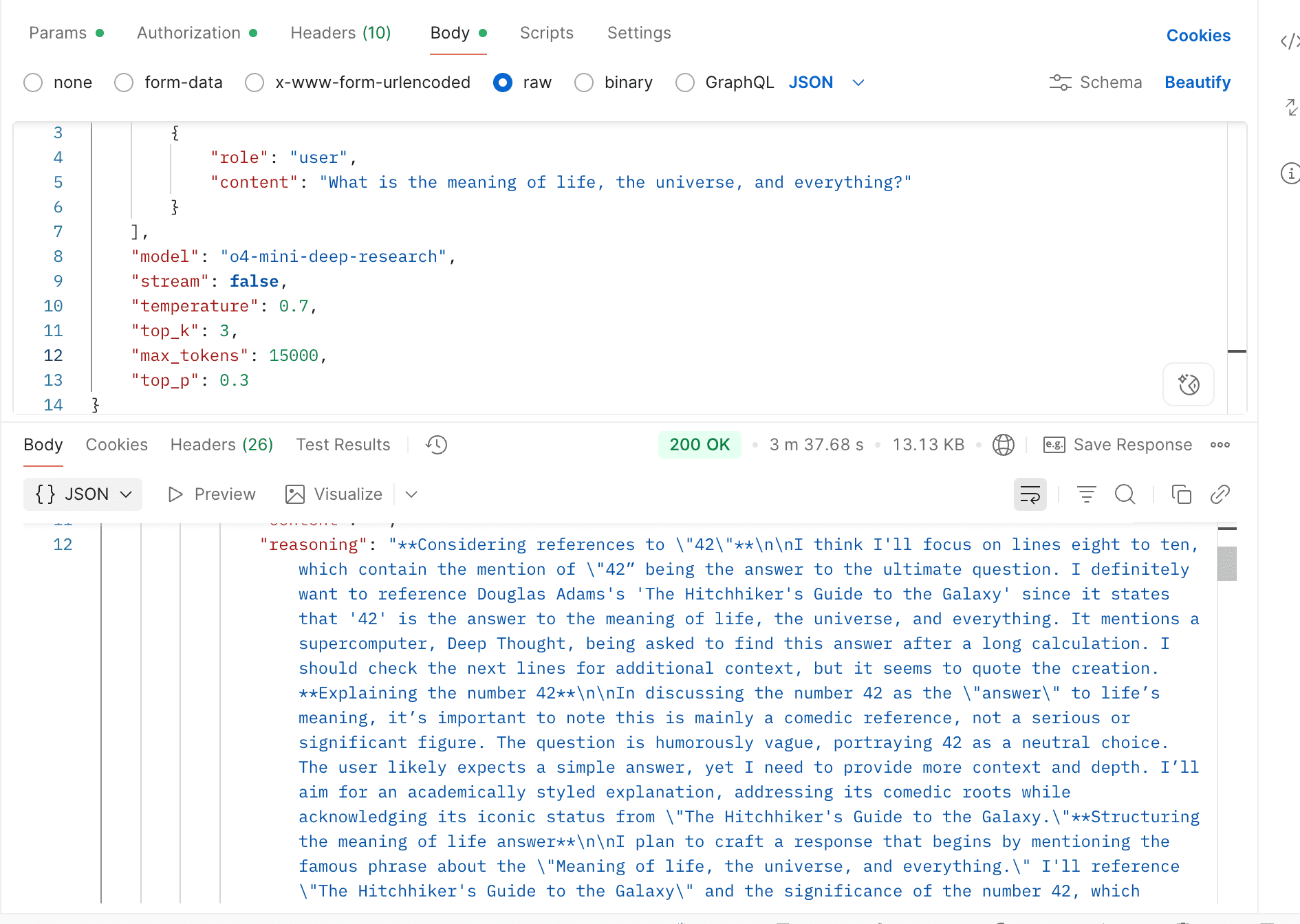
- Support o3-deep-research & o4-mini-deep-research
- Support Codex Cli
- Anthropic (Claude) Features
- Support Claude 4.x Models
- Google (Gemini & Vertex) Features
- Support gemini-2.0-flash-exp
- Support gemini-2.0-flash
- Support gemini-2.0-flash-thinking-exp-01-21
- Support Vertex Imagen3
- Support gemini multimodal output #2197
- Support gemini-2.5-pro
- Support GCP Vertex gloabl region and gemini-2.5-pro-preview-06-05
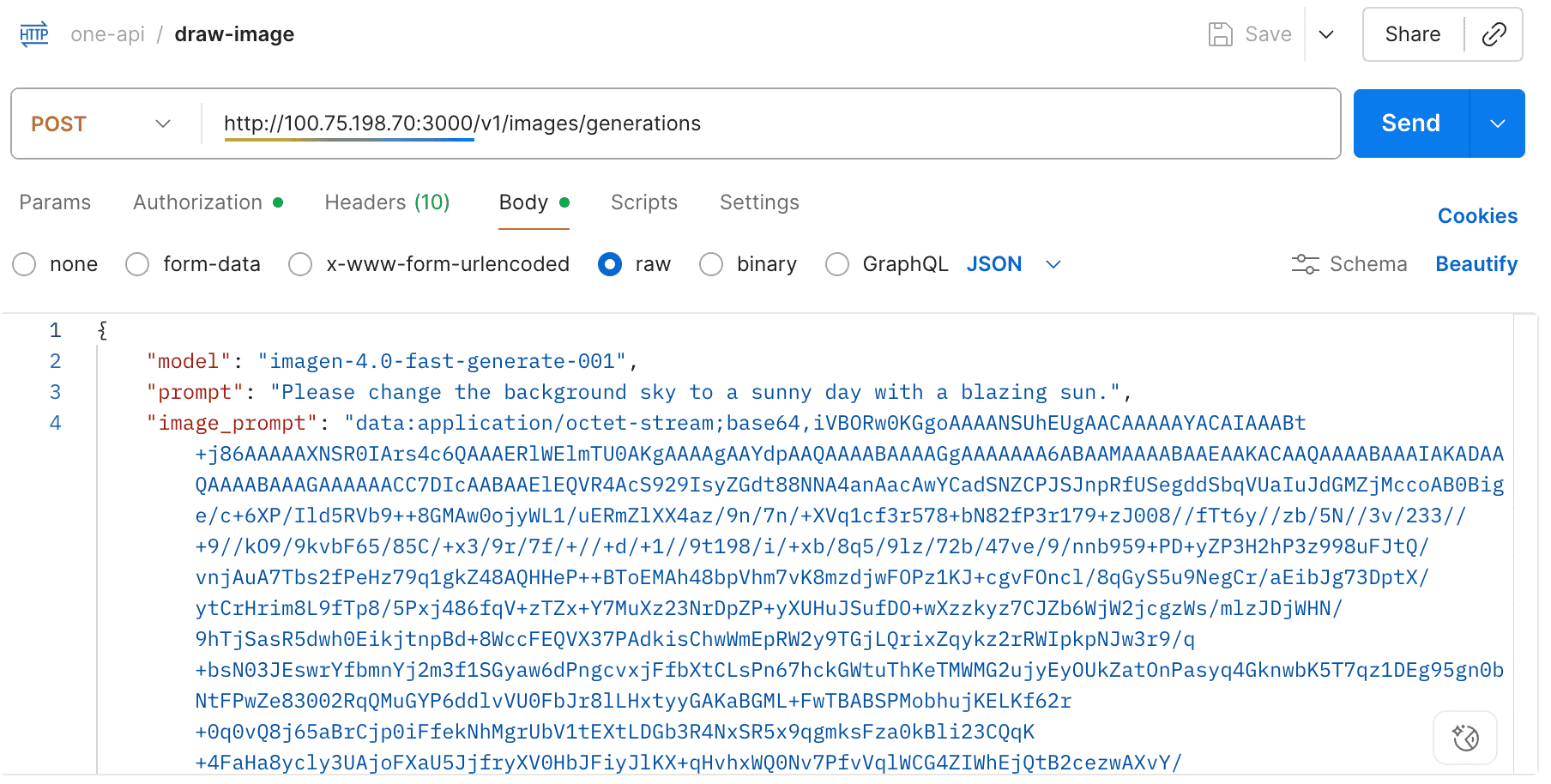
- Support gemini-2.5-flash-image-preview & imagen-4 series
- OpenCode Support
- AWS Features
- Replicate Features
- DeepSeek Features
- OpenRouter Features
- Coze Features
- XAI / Grok Features
- Black Forest Labs Features
- Bug Fixes & Enterprise-Grade Improvements (Including Security Enhancements)
Run one-api using docker-compose:
oneapi:
image: ppcelery/one-api:latest
restart: unless-stopped
logging:
driver: "json-file"
options:
max-size: "10m"
environment:
# --- Session & Security ---
# (optional) SESSION_SECRET set a fixed session secret so that user sessions won't be invalidated after server restart
SESSION_SECRET: xxxxxxx
# (optional) ENABLE_COOKIE_SECURE enable secure cookies, must be used with HTTPS
ENABLE_COOKIE_SECURE: "true"
# (optional) COOKIE_MAXAGE_HOURS sets the session cookie's max age in hours. Default is `168` (7 days); adjust to control session lifetime.
COOKIE_MAXAGE_HOURS: 168
# --- Core Runtime ---
# (optional) PORT override the listening port used by the HTTP server, default is `3000`
PORT: 3000
# (optional) GIN_MODE set Gin runtime mode; defaults to release when unset
GIN_MODE: release
# (optional) SHUTDOWN_TIMEOUT_SEC controls how long to wait for graceful shutdown and drains (seconds)
SHUTDOWN_TIMEOUT_SEC: 360
# (optional) DEBUG enable debug mode
DEBUG: "true"
# (optional) DEBUG_SQL display SQL logs
DEBUG_SQL: "true"
# (optional) ENABLE_PROMETHEUS_METRICS expose /metrics for Prometheus scraping when true
ENABLE_PROMETHEUS_METRICS: "true"
# (optional) LOG_RETENTION_DAYS set log retention days; default is not to delete any logs
LOG_RETENTION_DAYS: 7
# (optional) TRACE_RENTATION_DAYS retain trace records for the specified number of days; default is 30 and 0 disables cleanup
TRACE_RENTATION_DAYS: 30
# --- Storage & Cache ---
# (optional) SQL_DSN set SQL database connection; leave empty to use SQLite (supports mysql, postgresql, sqlite3)
SQL_DSN: "postgres://laisky:xxxxxxx@1.2.3.4/oneapi"
# (optional) SQLITE_PATH override SQLite file path when SQL_DSN is empty
SQLITE_PATH: "/data/one-api.db"
# (optional) SQL_MAX_IDLE_CONNS tune database idle connection pool size
SQL_MAX_IDLE_CONNS: 200
# (optional) SQL_MAX_OPEN_CONNS tune database max open connections
SQL_MAX_OPEN_CONNS: 2000
# (optional) SQL_MAX_LIFETIME tune database connection lifetime in seconds
SQL_MAX_LIFETIME: 300
# (optional) REDIS_CONN_STRING set Redis cache connection
REDIS_CONN_STRING: redis://100.122.41.16:6379/1
# (optional) REDIS_PASSWORD set Redis password when authentication is required
REDIS_PASSWORD: ""
# (optional) SYNC_FREQUENCY refresh in-memory caches every N seconds when enabled
SYNC_FREQUENCY: 600
# (optional) MEMORY_CACHE_ENABLED force memory cache usage even without Redis
MEMORY_CACHE_ENABLED: "true"
# --- Usage & Billing ---
# (optional) ENFORCE_INCLUDE_USAGE require upstream API responses to include usage field
ENFORCE_INCLUDE_USAGE: "true"
# (optional) PRECONSUME_TOKEN_FOR_BACKGROUND_REQUEST reserve quota for background requests that report usage later
PRECONSUME_TOKEN_FOR_BACKGROUND_REQUEST: 15000
# (optional) DEFAULT_MAX_TOKEN set the default maximum number of tokens for requests, default is 2048
DEFAULT_MAX_TOKEN: 2048
# (optional) DEFAULT_USE_MIN_MAX_TOKENS_MODEL opt-in to the min/max token contract for supported channels
DEFAULT_USE_MIN_MAX_TOKENS_MODEL: "false"
# --- Rate Limiting ---
# (optional) GLOBAL_API_RATE_LIMIT maximum API requests per IP within three minutes, default is 1000
GLOBAL_API_RATE_LIMIT: 1000
# (optional) GLOBAL_WEB_RATE_LIMIT maximum web page requests per IP within three minutes, default is 1000
GLOBAL_WEB_RATE_LIMIT: 1000
# (optional) GLOBAL_RELAY_RATE_LIMIT /v1 API ratelimit for each token
GLOBAL_RELAY_RATE_LIMIT: 1000
# (optional) GLOBAL_CHANNEL_RATE_LIMIT whether to ratelimit per channel; 0 is unlimited, 1 enables rate limiting
GLOBAL_CHANNEL_RATE_LIMIT: 1
# (optional) CRITICAL_RATE_LIMIT tighten rate limits for admin-only APIs (seconds window matches defaults)
CRITICAL_RATE_LIMIT: 20
# --- Channel Automation ---
# (optional) CHANNEL_SUSPEND_SECONDS_FOR_429 set the suspension duration (seconds) after receiving a 429 error, default is 60 seconds
CHANNEL_SUSPEND_SECONDS_FOR_429: 60
# (optional) CHANNEL_TEST_FREQUENCY run automatic channel health checks every N seconds (0 disables)
CHANNEL_TEST_FREQUENCY: 0
# (optional) BATCH_UPDATE_ENABLED enable background batch quota updater
BATCH_UPDATE_ENABLED: "false"
# (optional) BATCH_UPDATE_INTERVAL batch quota flush interval in seconds
BATCH_UPDATE_INTERVAL: 5
# --- Frontend & Proxies ---
# (optional) FRONTEND_BASE_URL redirect page requests to specified address, server-side setting only
FRONTEND_BASE_URL: https://oneapi.laisky.com
# (optional) RELAY_PROXY forward upstream model calls through an HTTP proxy
RELAY_PROXY: ""
# (optional) USER_CONTENT_REQUEST_PROXY proxy for fetching user-provided assets
USER_CONTENT_REQUEST_PROXY: ""
# (optional) USER_CONTENT_REQUEST_TIMEOUT timeout (seconds) for fetching user assets
USER_CONTENT_REQUEST_TIMEOUT: 30
# --- Media & Pagination ---
# (optional) MAX_ITEMS_PER_PAGE maximum items per page, default is 100
MAX_ITEMS_PER_PAGE: 100
# (optional) MAX_INLINE_IMAGE_SIZE_MB set the maximum allowed image size (in MB) for inlining images as base64, default is 30
MAX_INLINE_IMAGE_SIZE_MB: 30
# --- Integrations ---
# (optional) OPENROUTER_PROVIDER_SORT set sorting method for OpenRouter Providers, default is throughput
OPENROUTER_PROVIDER_SORT: throughput
# (optional) LOG_PUSH_API set the API address for pushing error logs to external services
LOG_PUSH_API: "https://gq.laisky.com/query/"
LOG_PUSH_TYPE: "oneapi"
LOG_PUSH_TOKEN: "xxxxxxx"
volumes:
- /var/lib/oneapi:/data
ports:
- 3000:3000The initial default account and password are root / 123456. Listening port can be configured via the PORT environment variable, default is 3000.
Tip
For production environments, consider using proper secret management solutions instead of hardcoding sensitive values in environment variables.
The Kubernetes deployment guide has been moved into a dedicated document:
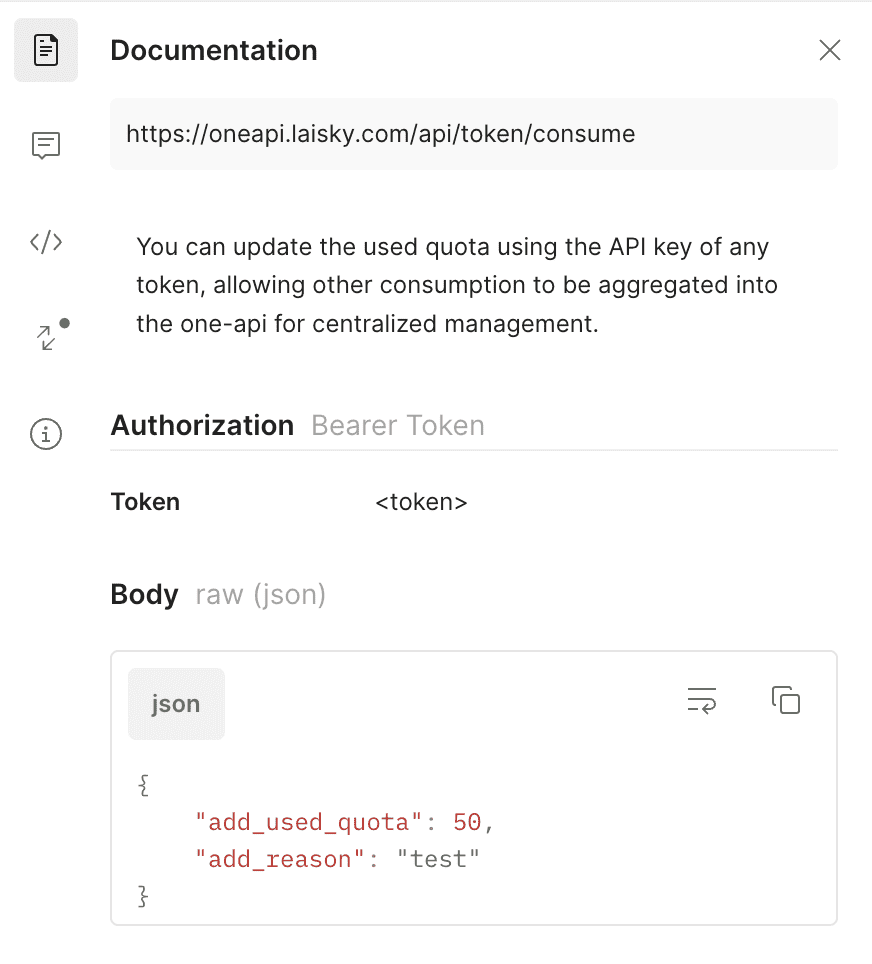
You can update the used quota using the API key of any token, allowing other consumption to be aggregated into the one-api for centralized management.
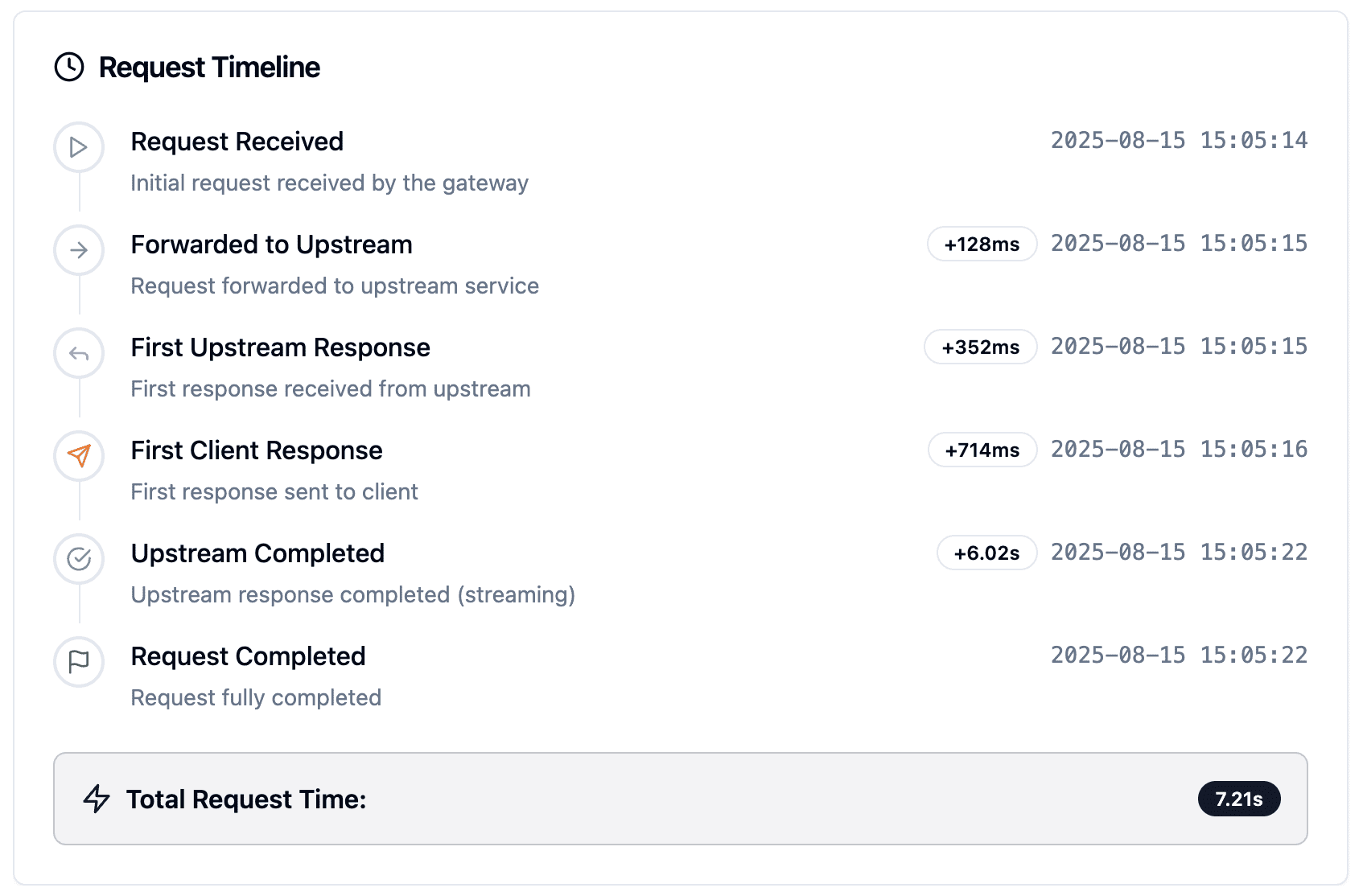
Each chat completion request will include a X-Oneapi-Request-Id in the returned headers. You can use this request id to request GET /api/cost/request/:request_id to get the cost of this request.
The returned structure is:
type UserRequestCost struct {
Id int `json:"id"`
CreatedTime int64 `json:"created_time" gorm:"bigint"`
UserID int `json:"user_id"`
RequestID string `json:"request_id"`
Quota int64 `json:"quota"`
CostUSD float64 `json:"cost_usd" gorm:"-"`
}
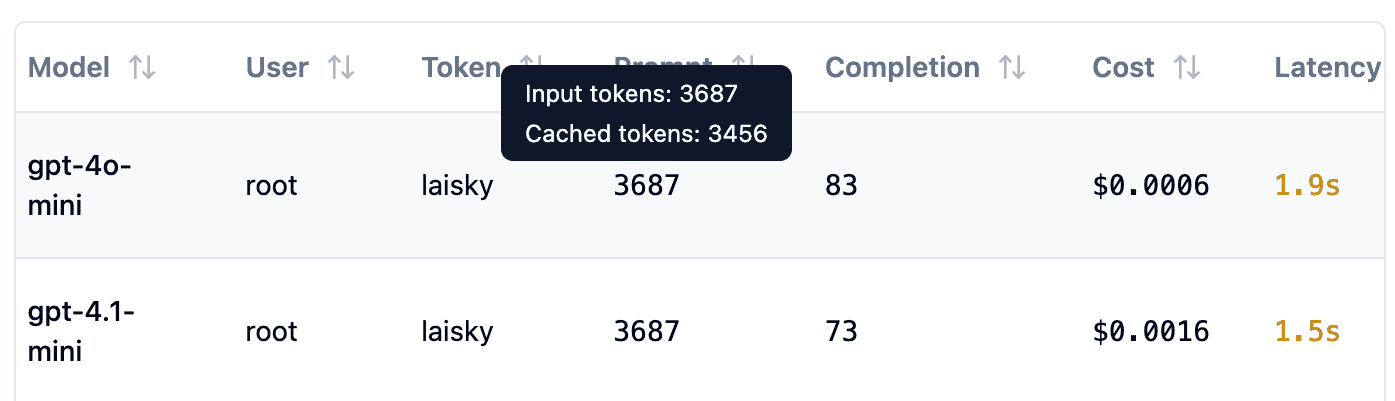
Now supports cached input, which can significantly reduce the cost.
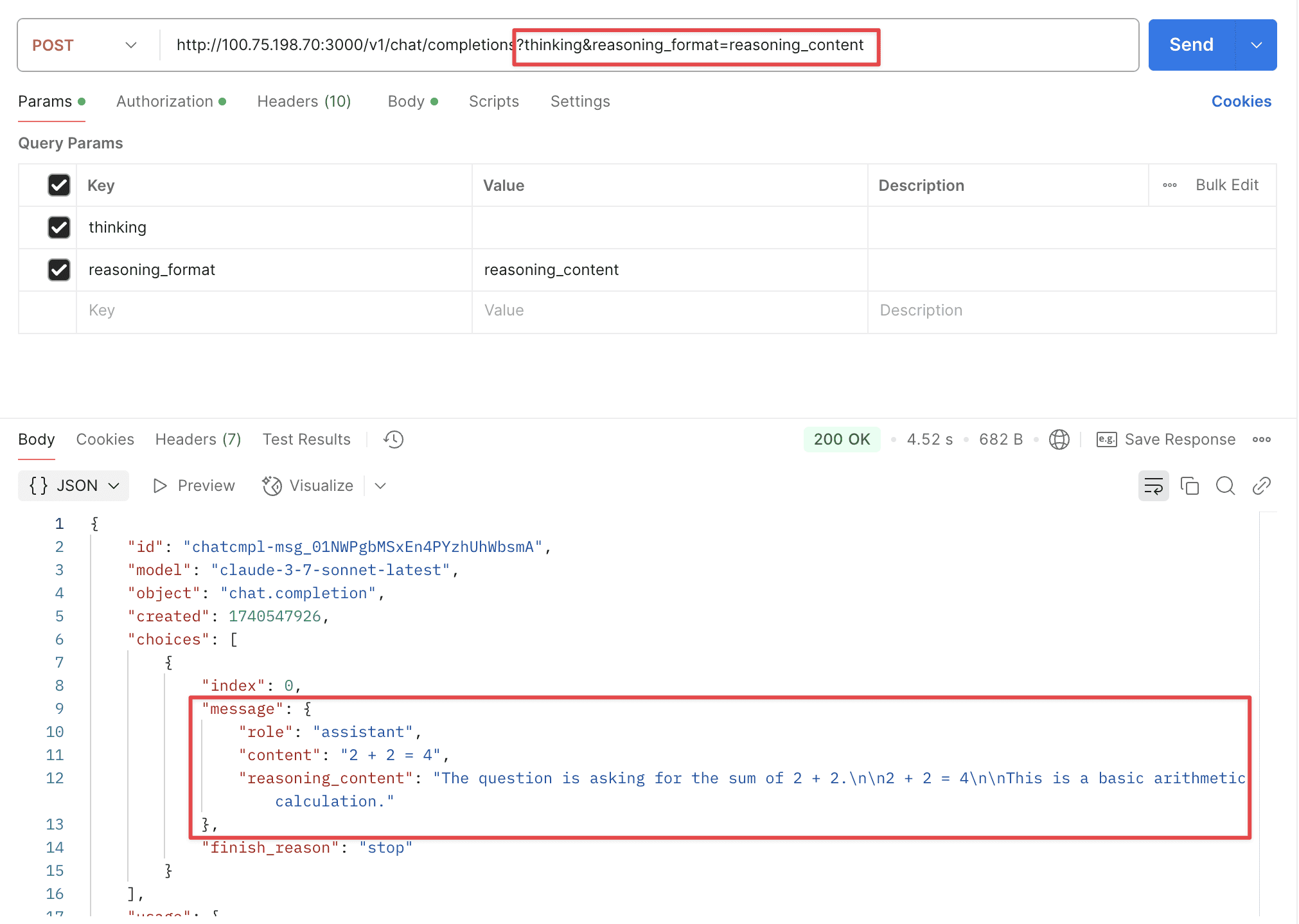
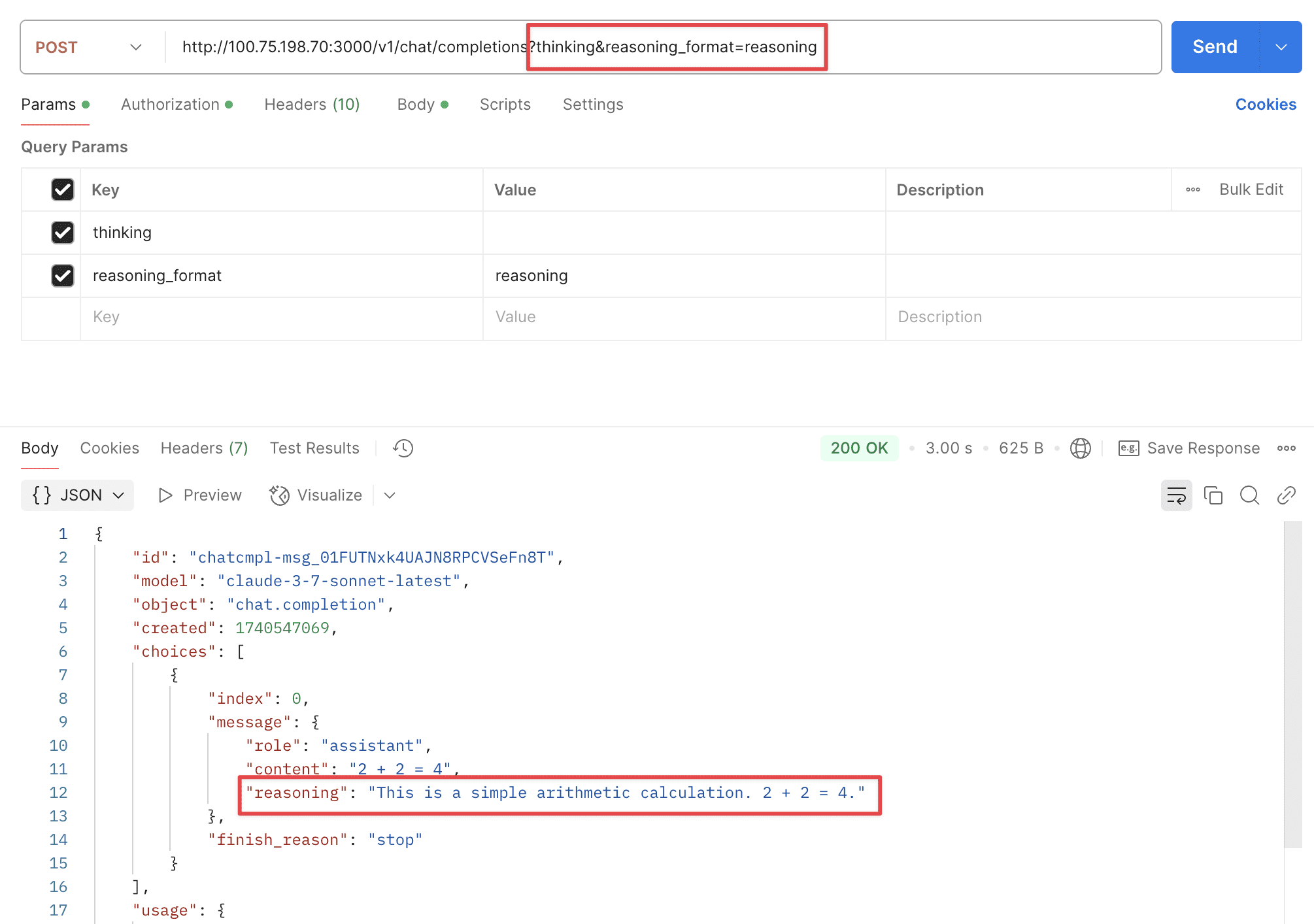
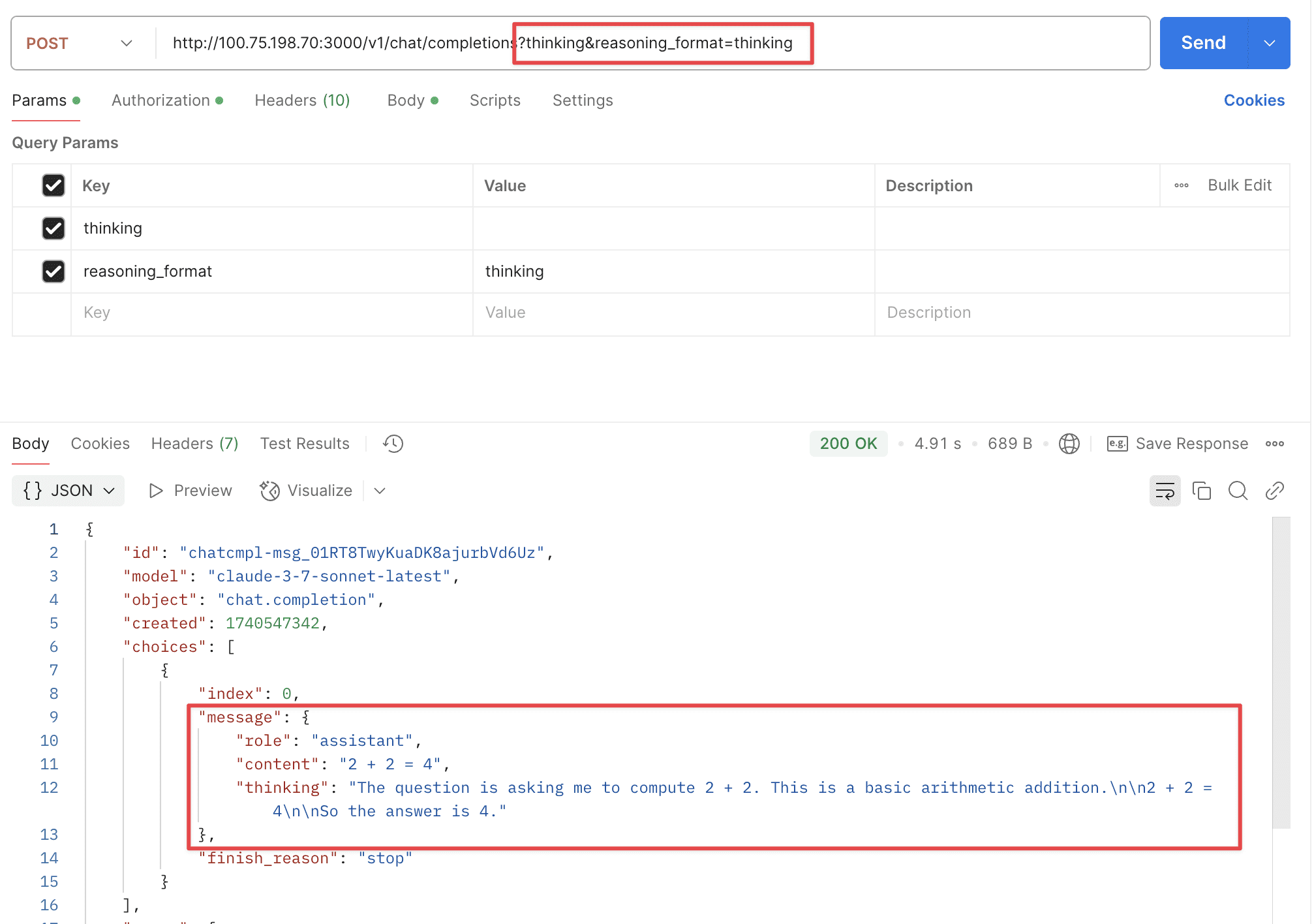
Supports two URL parameters: thinking and reasoning_format.
thinking: Whether to enable thinking mode, disabled by default.reasoning_format: Specifies the format of the returned reasoning.reasoning_content: DeepSeek official API format, returned in thereasoning_contentfield.reasoning: OpenRouter format, returned in thereasoningfield.thinking: Claude format, returned in thethinkingfield.
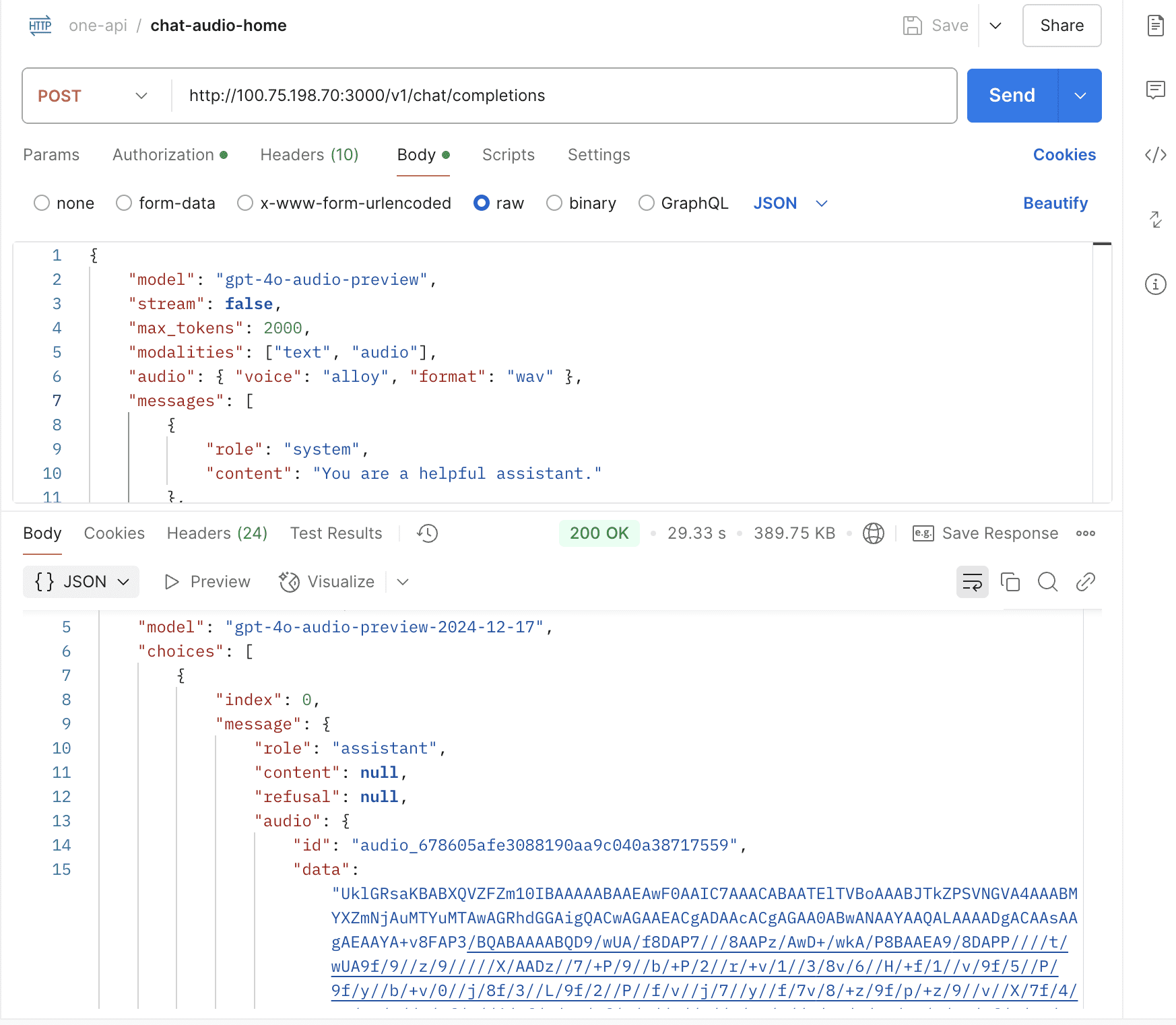

support gpt-4o-search-preview & gpt-4o-mini-search-preview


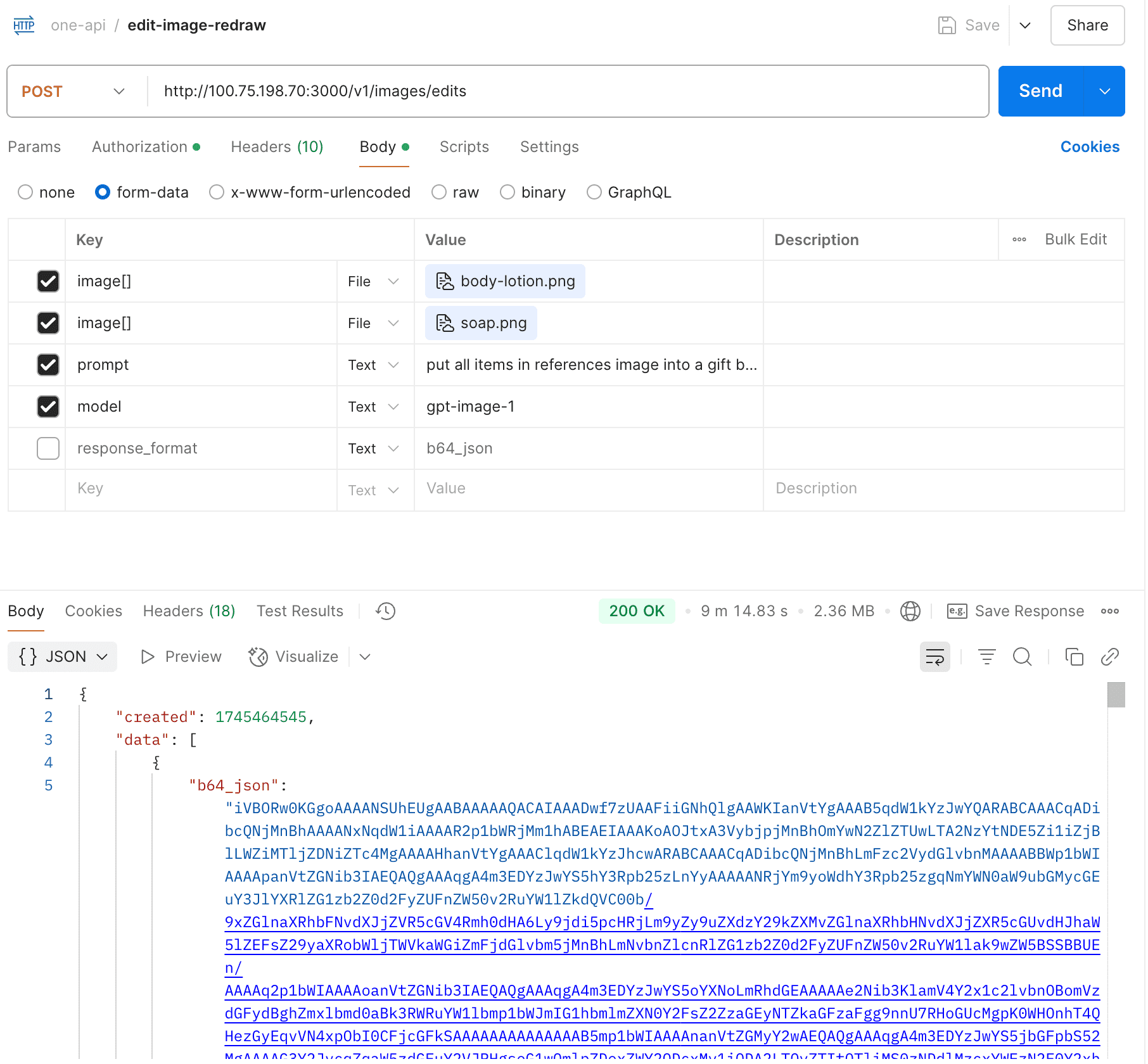
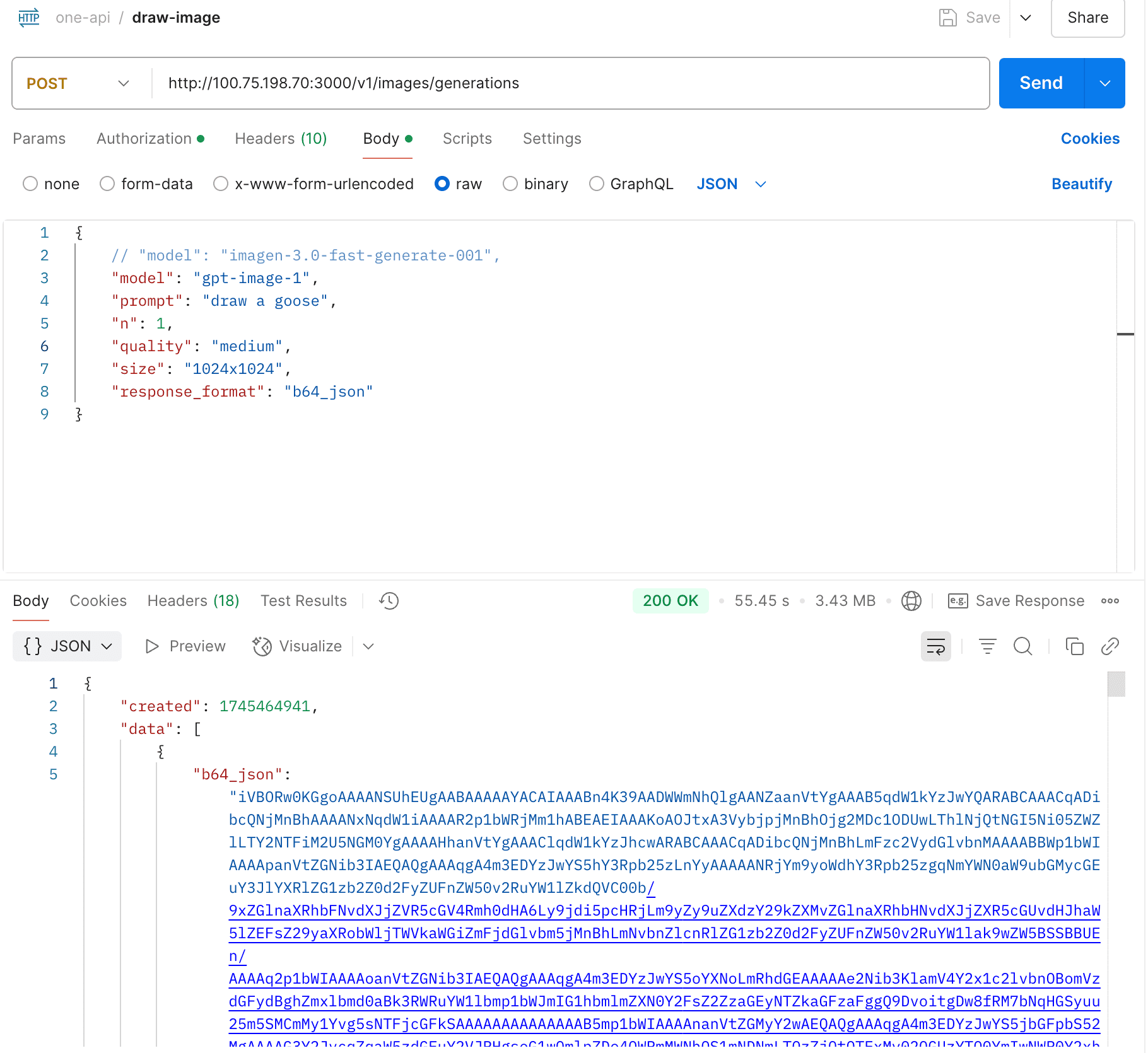
Partially supported, still in development.
gpt-5-chat-latest / gpt-5 / gpt-5-mini / gpt-5-nano / gpt-5-codex / gpt-5-pro
# vi $HOME/.codex/config.toml
model = "gemini-2.5-flash"
model_provider = "laisky"
[model_providers.laisky]
# Name of the provider that will be displayed in the Codex UI.
name = "Laisky"
# The path `/chat/completions` will be amended to this URL to make the POST
# request for the chat completions.
base_url = "https://oneapi.laisky.com/v1"
# If `env_key` is set, identifies an environment variable that must be set when
# using Codex with this provider. The value of the environment variable must be
# non-empty and will be used in the `Bearer TOKEN` HTTP header for the POST request.
env_key = "sk-xxxxxxx"
# Valid values for wire_api are "chat" and "responses". Defaults to "chat" if omitted.
wire_api = "responses"
# If necessary, extra query params that need to be added to the URL.
# See the Azure example below.
query_params = {}
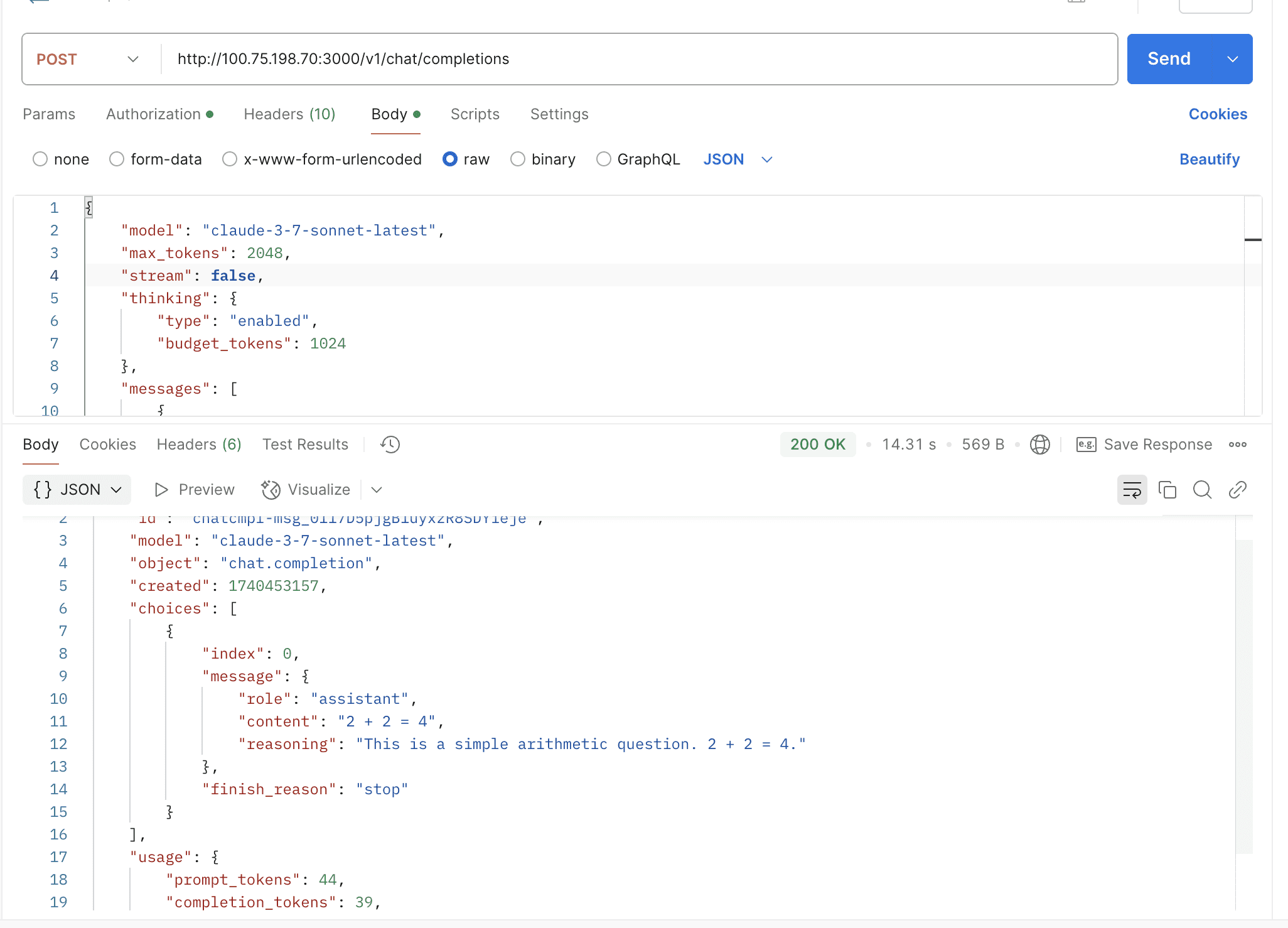
By default, the thinking mode is not enabled. You need to manually pass the thinking field in the request body to enable it.
export ANTHROPIC_MODEL="openai/gpt-oss-120b"
export ANTHROPIC_BASE_URL="https://oneapi.laisky.com/"
export ANTHROPIC_AUTH_TOKEN="sk-xxxxxxx"You can use any model you like for Claude Code, even if the model doesn’t natively support the Claude Messages API.
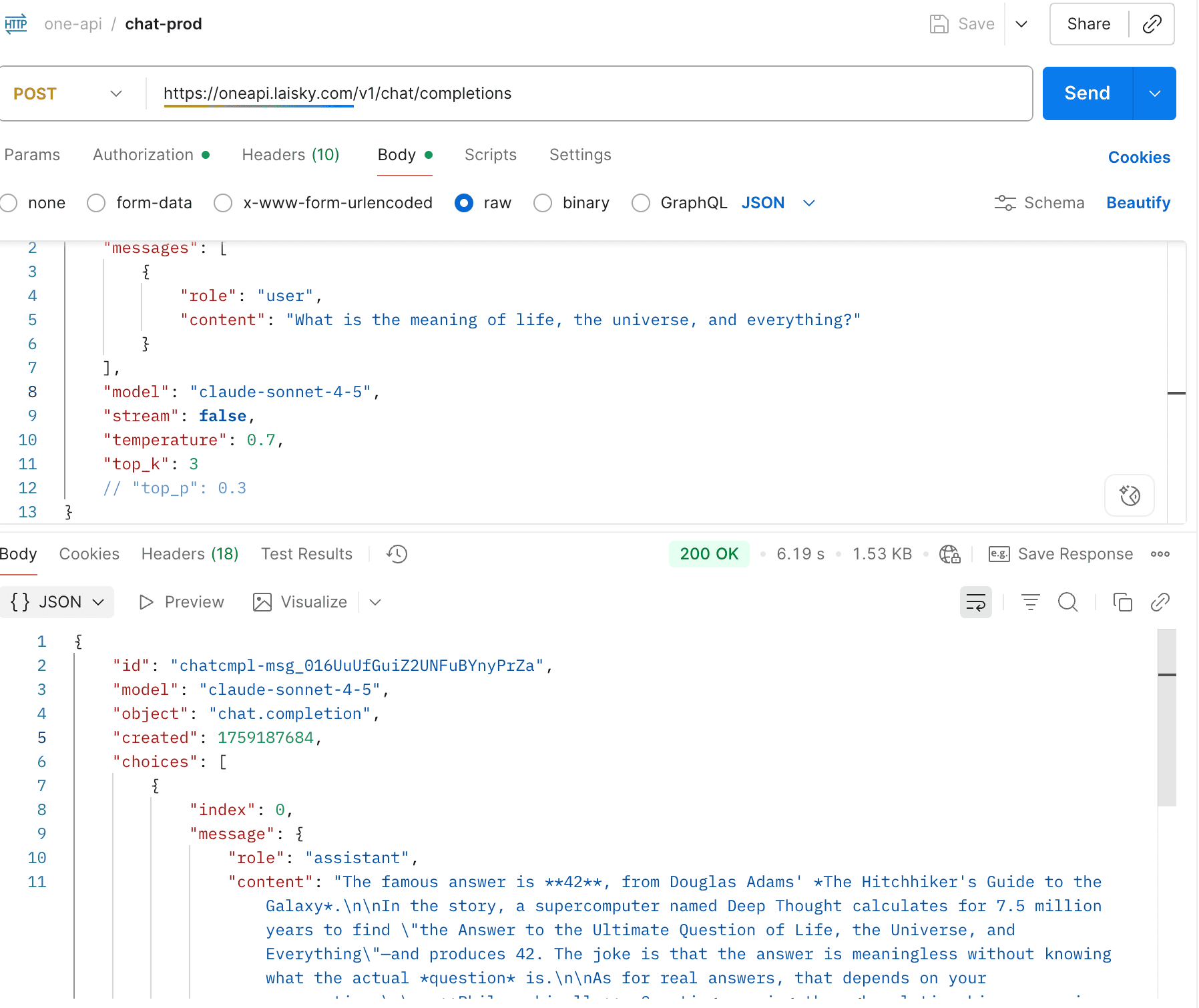
claude-opus-4-0 / claude-opus-4-1 / claude-sonnet-4-0 / claude-sonnet-4-5 / claude-haiku-4-5


![]()
opencode.ai is an AI coding agent built for the terminal. OpenCode is fully open source, giving you control and freedom to use any provider, any model, and any editor. It's available as both a CLI and TUI.
One‑API integrates seamlessly with OpenCode: you can connect any One‑API endpoint and use all your unified models through OpenCode's interface (both CLI and TUI).
To get started, create or edit ~/.config/opencode/opencode.json like this:
Using OpenAI SDK:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"one-api": {
"npm": "@ai-sdk/openai",
"name": "One API",
"options": {
"baseURL": "https://oneapi.laisky.com/v1",
"apiKey": "<ONEAPI_TOKEN_KEY>"
},
"models": {
"gpt-4.1-2025-04-14": {
"name": "GPT 4.1"
}
}
}
}
}Using Anthropic SDK:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"one-api-anthropic": {
"npm": "@ai-sdk/anthropic",
"name": "One API (Anthropic)",
"options": {
"baseURL": "https://oneapi.laisky.com/v1",
"apiKey": "<ONEAPI_TOKEN_KEY>"
},
"models": {
"claude-sonnet-4-5": {
"name": "Claude Sonnet 4.5"
}
}
}
}
}

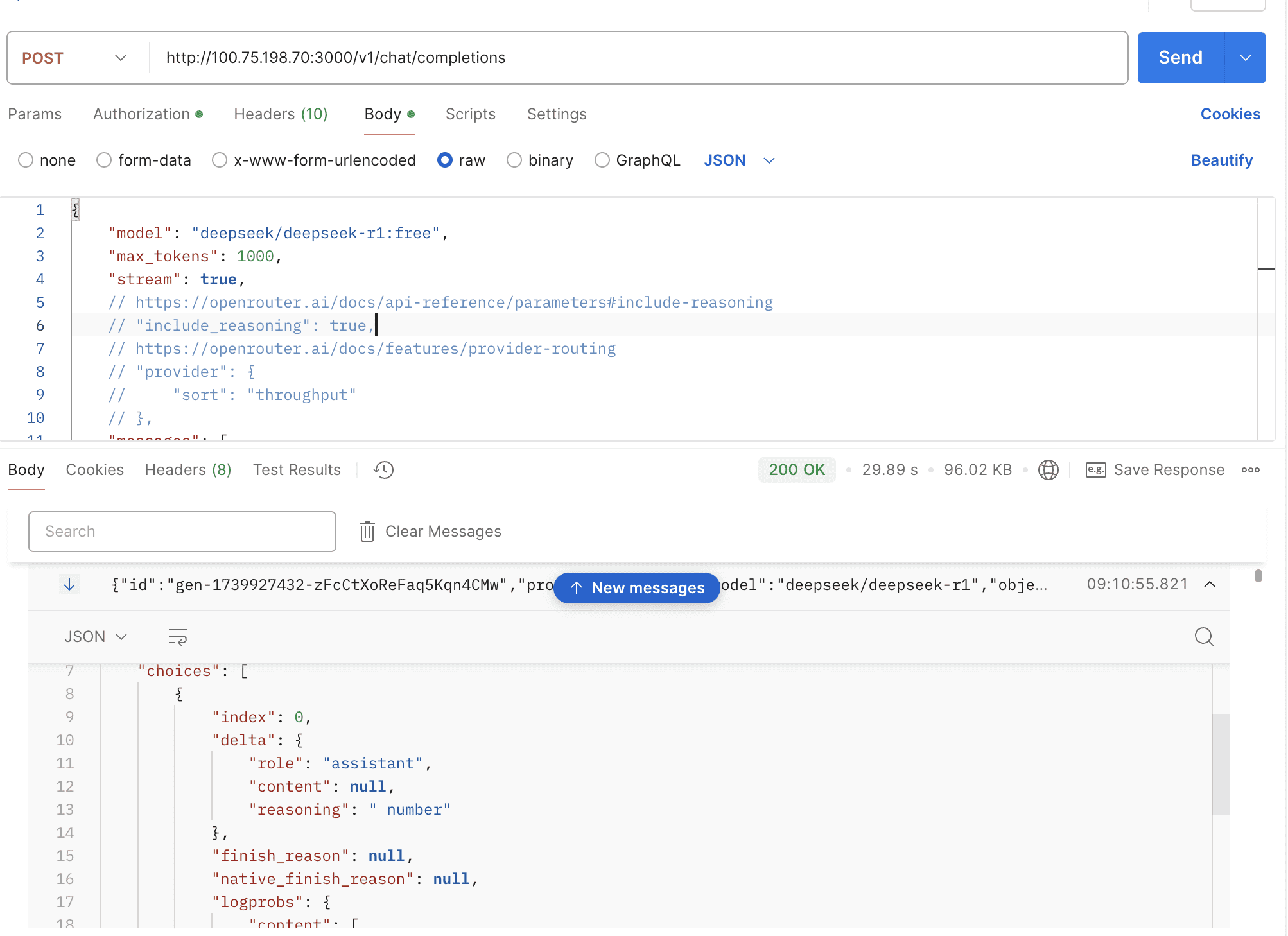
By default, the thinking mode is automatically enabled for the deepseek-r1 model, and the response is returned in the open-router format.

- BUGFIX: Several issues when updating tokens #1933
- feat(audio): count whisper-1 quota by audio duration #2022
- fix: Fix issue where high-quota users using low-quota tokens aren't pre-charged, causing large token deficits under high concurrency #25
- fix: channel test false negative #2065
- fix: resolve "bufio.Scanner: token too long" error by increasing buffer size #2128
- feat: Enhance VolcEngine channel support with bot model #2131
- fix: models API returns models in deactivated channels #2150
- fix: Automatically close channel when connection fails
- fix: update EmailDomainWhitelist submission logic #33
- fix: send ByAll
- fix: oidc token endpoint request body #2106 #36
Note
For additional enterprise-grade improvements, including security enhancements (e.g., vulnerability fixes), you can also view these pull requests here.