{kind=link}
{kind=link}
{kind=link}
This project was produced for DATA 512 at the University of Washington by Erin Orbits in October 2017.
The goal of this project is to explore the concept of 'bias' in data by analyzing Wikipedia articles (or pages) on political figures from different countries.
The dataset we will analyze includes information on the political articles associated with individual countries available on English language Wikipedia, the predicted article quality scores for those articles, and the population sizes for 210 countries as of 2015.
The project will quantify the number of Wikipedia articles devoted to politicians within each country, the quality of those political articles, and consider how those measurements vary between countries.
The analysis will include a series of visualizations that show:
- The countries with the greatest and least coverage of politicians on Wikipedia on a per capita basis.
- The countries with the highest and lowest proportion of high quality articles about politicians.
This README file and the Jupyter Notebook file, hcds-a2-bias.ipynb, contain the information needed to reproduce this project's analysis, including a description of the data and all relevant resources and documentation, with hyperlinks to those resources.
The data used in this project was generated by combining three datasets from different sources:
- the Wikipedia article data,
- the population data, and
- the article quality prediction data.
The Wikipedia article dataset can be found on the Figshare website. You can download the data from the website as shown in the screenshot image below.
Figshare is an open repository where users can make their research and data available in a citable and discoverable manner, for more information, see About Figshare.
A copy of the Wikipedia article dataset is also available in this data-512-a2 repository: page_data.csv.
This English-language Wikipedia article data about politicians came from the "Category: Politicians by nationality" and corresponding subcategories. These are some of the subcategories:
Politicians by nationality (243 C)
► Assassinated politicians by nationality (129 C)
► Political candidates by nationality (15 C)
► Politicians by ethnic or national descent (12 C)
► Politicians by former country (18 C)
► Politicians by nationality and city (15 C)
► Politicians by nationality and party (232 C)
► Politicians convicted of crimes by nationality (72 C)
► Politicians by nationality and century (45 C)
► Leaders of political parties by country (39 C)
► Politicians by century and nationality (4 C)
► Politicians from dependent territories (9 C)
► Women in politics by nationality (234 C)
► LGBT politicians by nationality (41 C)
► Sportsperson-politicians by nationality (62 C)
► Politicians of African nations (65 C)
► Politicians of Asian nations (49 C, 1 P)
► Politicians of Caribbean nations (28 C)
► Politicians of European nations (62 C)
► Politicians of North American nations (10 C)
► Politicians of Oceanian nations (31 C)
► Politicians of South American nations (16 C)
The article data was extracted using the Wikimedia API, saved as a CSV file named page_data.csv, and uploaded to Figshare.
Note: The process of extracting the article data is limited since the "recursion only went 2 levels deep into the category tree." Politicians by Country from the English-language Wikipedia, Figshare. For example, among the articles devoted to Antiguan politicians, someone exclusively listed as an Antiguan politician is included in the dataset, but a politician who was assassinated is not. Id.
The columns in the page_data.csv file are:
- country: the country name, extracted from the category name
- page: the Wikipedia page (aka article) title
- rev_id: the revision_id for the last edit to the page
License
The Wikipedia data, along with the code used to generate that data, are released on Figshare under the CC-BY-SA 4.0 license.
Additionally, the Wikimedia Foundation data is licensed under an Apache 2.0 License, which includes in part:
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
For more information on this license, see Apache 2.0 License.
Terms of Use
The use of Wikipedia data is subject to the Wikimedia Foundation terms of use. A summary along with the complete terms are available here.
The population data for 210 countries comes from the Population Research Bureau's (PRB) 2015 World Population Data Sheet, available on this PRB Data website. If you would like to download the population data, follow the link and click the Excel icon on the right side, as shown in the screenshot below.
However, that same population dataset is also available in this repository, population_mid-2015.csv.
The columns in the Population Mid-2015.csv file:
- Location: the country name
- Location Type: "Country"
- TimeFrame: "Mid-2015"
- Data Type: "Number"
- Data: the population value encoded as a number with commas
Population Data License
It's not clear if the population data is subject to a license.
However, the stated mission of the PRB is to provide access to data. "The Population Reference Bureau informs people around the world about population, health, and the environment, and empowers them to use that information to advance the well-being of current and future generations." PRB's About Page Additionally, the PRB's annual report states that it is "committed to making all of its products and resources publicly available by disseminating them widely through both print and digital channels, and in innovative formats." See report
The predicted quality scores for each article in the Wikipedia dataset comes from a Wikimedia API endpoint for a machine learning system called ORES ("Objective Revision Evaluation Service"). ORES estimates the quality of an article at a particular point in time, and assigns a series of probabilities that the article is best described by one of the categories listed below.
The range of quality scores are, from best to worst:
- FA - Featured article
- GA - Good article
- B - B-class article
- C - C-class article
- Start - Start-class article
- Stub - Stub-class article
These quality scores are a sub-set of quality assessment categories developed by Wikipedia editors. For more information about the scores, see Project Assessment.
The ORES API documentation can be found here and the web API is here. The API requires a revision ID, which is the third column in the Wikipedia dataset (originally titled "last_edit"), and the machine learning model, which is "wp10".
When you query the API, the ORES returns a JSON object that includes a predicted quality score, as well as the probability values for each of the six possible quality scores. But, for the analysis in this project, you only need the predicted quality score value, not the probabilities.
This is an example of a response in the JSON format from the ORES API:
{"enwiki": {
"models": {"wp10": {"version": "0.5.0"}}, "scores": {"774499188": {"wp10": {"score": {"prediction": "Stub",
>>>>>>> "probability": {
>>>>>>>> "B": 0.03488477079112925,
>>>>>>>> "C": 0.06953258948284814,
>>>>>>>> "FA": 0.0025762575670963965,
>>>>>>>> "GA": 0.007911851615317388,
>>>>>>>> "Start": 0.4106575723489943,
>>>>>>>> "Stub": 0.4744369581946146
>>>>>> }
>>>>>> }
}}}
}
}
Note: If a Wikipedia article is deleted or a revision ID value gets deleted, the ORES API returns an error.
For example, with revision ID 807367030 (which corresponded to an article about "Jalal Movaghar" of Iran), the ORES API error message is: “RevisionNotFound: Could not find revision ({revision}:807367030)“.
Article Quality Prediction Data License
The Wikipedia data, and the code used to generate that data, are released under a Creative Commons Attribution-ShareAlike 3.0 Unported License.
This project uses the open-source web application Jupyter Notebook. To download Jupyter Notebook, see Installation and for more information, see Documentation.
The code in the Jupyter Notebook project file, hcds-a2-bias.ipynb, is written in Python 3. You also need to have Python installed in order to run the Jupyter Notebook application. To download a version of Python 3, like Python 3.6, see Download and Beginner's Guide.
Alternatively, you can download a version of Python 3 by downloading Anaconda (Download, Documentation).
In addition to Python 3.X, the following Python libraries are needed to run the code in hcds-a2-bias.ipynb.
- Matplotlib : will be used for data visualization
- Pandas : will be used for data processing
- Seaborn -- Note: this library is only for style purposes and is not essential
If necessary, you can pip install any of the above libraries, for example:
pip install matplotlib or pip3 install matplotlib.
Additionally, if you have any version of Python 3.X installed, you should already have the CSV, JSON,
and Requests libraries installed. These dependency libraries will be used to get and save data in the notebook
file, hcds-a2-bias.ipynb.
This visualization of the combined datasets was created with Matplotlib.
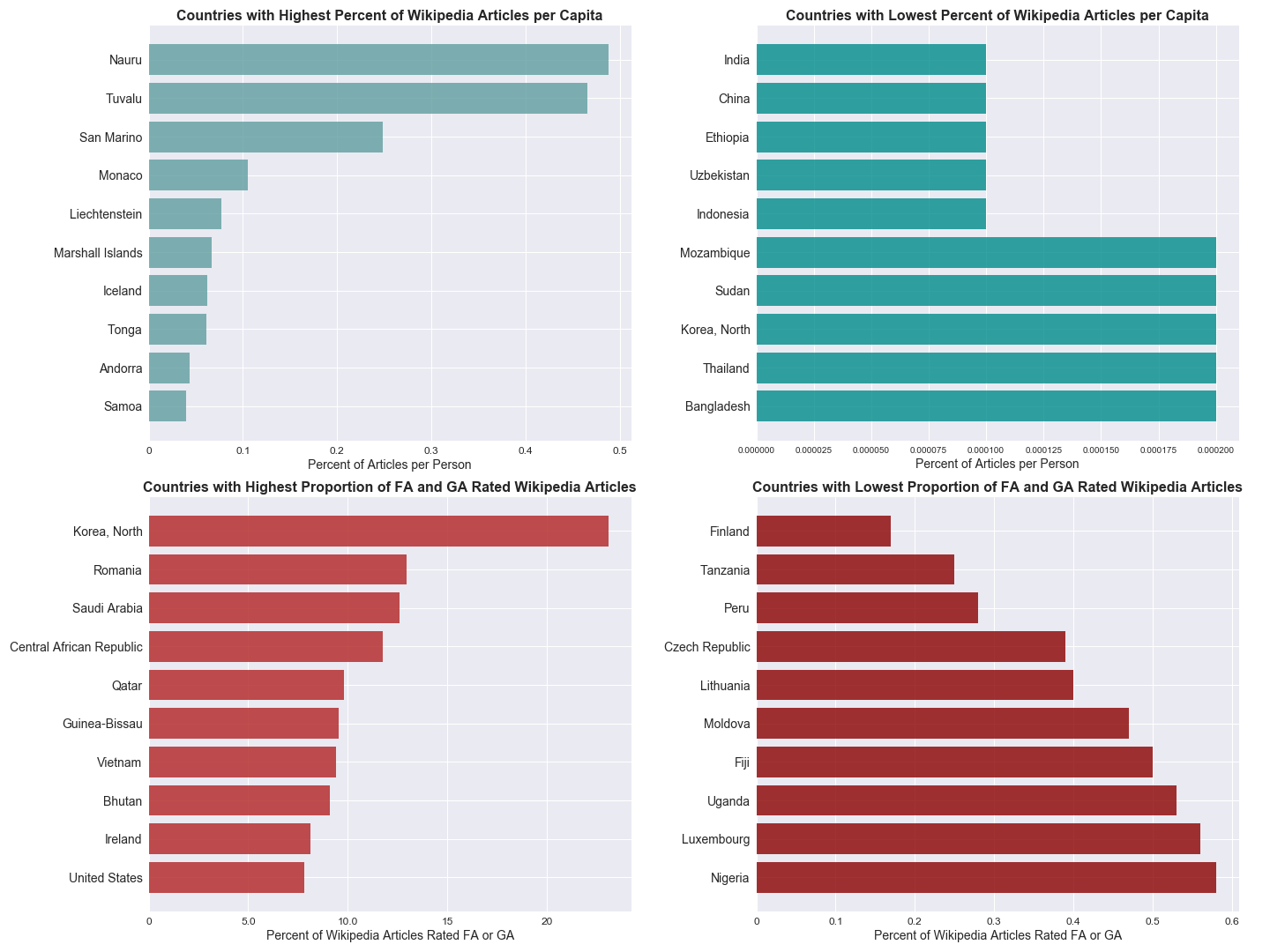
See the Jupyter Notebook file, hcds-a2-bias.ipynb, in this repository for the code to create this visualization.
First and foremost, this English-language Wikipedia article data was generated from the "Category: Politicians by nationality" and one subcategory. So, the editors who created these articles had to categorize the subjects of these articles as "politicians" and decide on the subjects' "nationality."
The Merriam-Webster Dictionary defines a politician as "a person experienced in the art or science of government," or "a person engaged in party politics as a profession," or "often disparaging: a person primarily interested in political office for selfish or other narrow usually short-sighted reasons."
Especially, since the term "politician" can be considered disparaging, it's possible that editors would be reluctant to label their articles as politicians. For example, out of the 33 most well-known U.S. presidents, only four have articles in our dataset, and one of those is John F. Kennedy, who's country is listed as "Ireland." Additionally, these modern politicans are not included in our dataset:
- "Ronald Reagan",
- "George H. W. Bush",
- "Bill Clinton",
- "Hillary Rodham Clinton",
- "George W. Bush",
- "Barack Obama",
- "Donald Trump",
- "Bernie Sanders", or
- "Sarah Palin".
Country with the Highest Proportion of Per Capita Articles: Nauru (0.4880 %)
Country with the Lowest Proportion of Per Capita Articles ( > 0 ): Bangladesh (0.0002 %)
Country with the Highest Proportion of Quality Articles: North Korea (23.08 %)
Country with the Lowest Proportion of Quality Articles ( > 0 ): Finland (0.17 %)
Countries with No High Quality Articles: 'Andorra', 'Antigua and Barbuda', 'Bahamas', 'Bahrain', 'Barbados', 'Belgium', 'Belize', 'Burundi', 'Cape Verde', 'Comoros', 'Djibouti', 'Dominica', 'Eritrea', 'Federated States of Micronesia', 'French Guiana', 'Guadeloupe', 'Guyana', 'Honduras', 'Kazakhstan', 'Kiribati', 'Lesotho', 'Liechtenstein', 'Macedonia', 'Marshall Islands', 'Monaco', 'Mozambique', 'Nauru', 'Nepal', 'San Marino', 'Sao Tome and Principe', 'Seychelles', 'Solomon Islands', 'Suriname', 'Swaziland', 'Switzerland', 'Tajikistan', 'Timor-Leste', 'Tonga', 'Tunisia', 'Turkmenistan', 'Zambia'
5 Countries with Highest Number of Articles:
> France 1689 (population 64,346,720);
> Australia 1566;
> China 1138 (population 1,371,920,000);
> United States 1098;
> Mexico 1081
Initially, it was surprising that North Korea had the highest proportion of high quality articles, but given the number of missing articles in this dataset, I'm not sure I can conclude anything. The classification system for Wikipedia articles seems somewhat arbitrary. Before drawing any conclusions about bias, I would like to include data from other categories, perhaps the subcategories of Category:Lists of political office-holders by country.